As vector search becomes a core component of AI-driven applications, teams are evaluating which platforms best meet their performance, integration, and operational requirements. Two commonly considered options are MongoDB Vector Search and Pinecone. MongoDB integrates vector search into a general-purpose database, while Pinecone is a dedicated managed vector service.
This article compares both systems to help determine which is more suitable for specific workloads.
What is MongoDB Vector Search?
MongoDB Vector Search provides vector indexing and similarity search directly within MongoDB collections. It is supported in MongoDB Atlas and in self-managed Community and Enterprise Advanced deployments.
MongoDB uses Apache Lucene vector indexes based on the Hierarchical Navigable Small World (HNSW) algorithm to perform approximate nearest neighbor (ANN) search. Exact search is also available when accuracy is prioritized over speed.
Because embeddings and application attributes reside in the same document, similarity search can be combined with standard query filters without requiring a separate data store or synchronization layer. This enables hybrid query execution within a single system.
What is Pinecone?
Pinecone is a managed vector database for storing embeddings and performing similarity search over high-dimensional data. It implements ANN search and abstracts operational responsibilities such as index management, scaling, sharding, and replication.
Vectors can be stored with basic metadata that supports filtering, but Pinecone does not function as a general-purpose data store. Additional application context must be maintained externally and joined at the application layer. Pinecone is optimized for high-throughput, low-latency top-k vector retrieval.
Architecture and Design
1. Data Model
The two systems differ significantly in how they structure and store vector data together with accompanying attributes. MongoDB combines embeddings and non-vector fields within a single document, whereas Pinecone follows a more minimal model centered around the vector itself. Examples of each approach are shown below.
MongoDB stores embeddings and non-vector attributes in the same document. This keeps object state, metadata, and vectors within a unified schema.
For Example:
{
"_id": "p123",
"title": "Wireless Headphones",
"category": "audio",
"price": 149.99,
"brand": "Acme",
"embedding": [ 0.0121, -0.4423, 0.9982, 0.1159, -0.3204, 0.5541, -0.2298, 0.7312, 0.1883,-0.0334, 0.9123, -0.5510, 0.0022,
0.8211, -0.1188, 0.6635, -0.0091, 0.5222,-0.2010, 0.7732, 0.4453, -0.6521, 0.3902, -0.1132, 0.8233, -0.2921, 0.5010, 0.1423,
-0.7711, 0.3102, -0.5520, 0.4481, -0.0182, 0.6012, 0.0021, -0.4199, 0.7332, -0.1153, 0.8121, -0.3120, 0.0011, 0.5533, 0.4211,
-0.1742, 0.9001 -0.3191, 0.7713, -0.0021, 0.2334, 0.7110
],
"tags": ["electronics", "wireless", "headphones"],
"updated_at": "2025-02-10T10:22:00Z"
}
MongoDB documents are stored in BSON format with a maximum size limit of 16 MB per document. This constraint affects how large embeddings can be stored: For example, using float32 vectors (4 bytes per dimension), a single document can theoretically hold vectors up to ~4 million dimensions, though in practice, the limit is lower due to other document fields and BSON overhead. Most production use cases involve embeddings between 128 and 4096 dimensions, well within this limit.
Pinecone maintains a minimal structure: a vector plus optional metadata fields. It is optimized for similarity lookup rather than modeling complex entities.
For Example:
{
"id": "p123",
"values": [
0.0121, -0.4423, 0.9982, 0.1159, -0.3204, 0.5541, -0.2298, 0.7312, 0.1883, -0.0334, 0.9123, -0.5510, 0.0022, 0.8211,
-0.1188, 0.6635, -0.0091, 0.5222, -0.2010, 0.7732, 0.4453, -0.6521, 0.3902, -0.1132, 0.8233, -0.2921, 0.5010, 0.1423,
-0.7711, 0.3102, -0.5520, 0.4481, -0.0182, 0.6012, 0.0021, -0.4199, 0.7332, -0.1153, 0.8121, -0.3120, 0.0011, 0.5533,
0.4211, -0.1742, 0.9001, -0.3191, 0.7713, -0.0021, 0.2334, 0.7110
],
"metadata": {
"category": "audio",
"brand": "Acme"
}
}
2. Search Engine
Both solutions implement vector search using distinct architectural models, which influences performance characteristics, request flow, and integration with surrounding components. MongoDB adopts a dual-process model that separates storage and query execution, while Pinecone provides a fully managed vector search service built around distributed ANN indexing. The following sections describe these designs in greater detail.
MongoDB Vector Search is implemented as a two-process architecture consisting of:
- mongod: The process is the primary database component. It stores BSON documents, replicates data across the replica set, handles CRUD operations and transactions, and serves as the system of record. It does not manage Lucene indexes or run vector search logic.
- mongot: The process runs beside the database to provide search capabilities. It manages Lucene index structures for both text and vector fields and is responsible for executing $search and $vectorSearch operations. mongot does not store complete documents. It keeps only Lucene index segments containing the fields referenced by the index definitions.
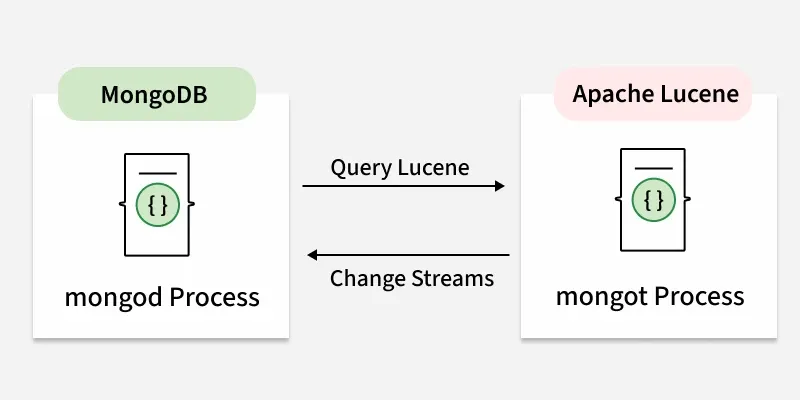
Index synchronization is based on MongoDB change streams. When documents are inserted, updated, or removed in mongod and the affected fields are part of a search index, mongod generates internal change stream events. mongot consumes these events and updates the Lucene index so that indexed data remains consistent with the underlying database without requiring manual rebuilds.
Query execution is also coordinated. When a client submits an aggregation pipeline that includes $search or $vectorSearch, mongod parses the pipeline and sends the search stage to mongot. The search engine evaluates similarity or text relevance through Lucene and returns matching document identifiers with scores. mongod then retrieves the documents from storage, applies any additional stages in the pipeline, merges results when necessary, and sends the final response to the client.
Multiple mongot processes can be deployed in a cluster to increase throughput and availability. Search requests are routed internally to active mongot instances, so applications do not need to direct queries to specific search nodes. Because mongot is separated from the storage engine, vector and text search workloads do not interfere with transactional operations on mongod. This division allows MongoDB to scale vector search capacity while preserving transactional consistency and data durability.
Pinecone provides approximate nearest neighbor vector search using proprietary indexing components built on algorithms such as HNSW and IVF. The architecture differs between deployment models:
A. Pod-Based Indexes
- Each index runs on one or more pods, which are compute units that store vector partitions and execute similarity search. Newly ingested vectors become queryable shortly after upsert; index structures are updated incrementally and maintained automatically, without requiring user-initiated rebuilds. Background compaction merges smaller index segments into larger ones to improve query latency and reduce fragmentation over time.
- High availability is achieved by replicating pod groups across multiple nodes or availability zones. If an index executor becomes unavailable, requests are transparently served by a healthy replica. Index lifecycle tasks, including index construction, compaction, update propagation, and recovery, are handled entirely by the service.
B. Serverless Indexes
Infrastructure is fully abstracted and managed by Pinecone. Compute and storage scale independently based on demand, without exposing pods or nodes to the user. Vectors are distributed automatically across Pinecone's backend infrastructure. Index updates and compaction happen transparently in the background. The service automatically provisions capacity to handle incoming traffic and scales down during idle periods.
During query execution, Pinecone evaluates similarity against stored embeddings using the chosen metric (for example, cosine, dot product, or Euclidean). Metadata filters can be applied during retrieval, and filter evaluation is integrated into the vector search path so that returned top-k results satisfy both similarity ranking and filter criteria. Query responses include the top-k vector identifiers along with distance scores and any stored metadata. These query semantics remain consistent across both pod-based and serverless deployments.
3. Horizontal Scalability
Both solutions support horizontal scaling, but they differ significantly in how this is achieved. MongoDB relies on explicit sharding with well-defined routing and data distribution mechanics, while Pinecone automatically partitions data across compute units (pods in pod-based deployments, or managed infrastructure in serverless). Although Pinecone does not refer to this as sharding, the underlying behavior is functionally similar: Each pod stores a subset of the vectors, and query execution fans out across them before results are merged.
The following sections examine these approaches in more detail.
- MongoDB Vector Search achieves horizontal scalability through its built-in sharding architecture, which allows deployments to handle very large datasets. Data is distributed across shards based on a shard key, with each shard storing a portion of the overall dataset.
- In a sharded deployment, queries are routed through mongos, which coordinates request execution. Each shard’s mongod forwards the vector search stage to its co-located mongot process. The mongot process evaluates only the Lucene-based vector index for that shard. Each mongot returns partial top-k results to mongod, which then aggregates and globally ranks them before returning the final output.
- MongoDB Atlas supports deploying dedicated search nodes (mongot processes) independently from database nodes (mongod). This isolates vector and full-text search workloads from transactional operations. Multiple mongot instances can be provisioned (one or more per shard) to increase parallelism and high availability, with internal load balancing distributing search traffic across available search nodes.
This architecture enables independent scaling. Adding shards increases data capacity and distributes vector indexes. Adding search nodes increases query throughput without modifying stored data. Vector indexes are kept in sync through change streams from mongod, and each shard remains a standard MongoDB replica set to ensure data durability. If a node fails, replica-set failover keeps database operations running, and remaining mongot processes continue to serve search requests to maintain availability.
Pinecone offers two deployment models:
A. Pod-Based Indexes
- Each index is composed of multiple pods, which are Pinecone-defined compute units that store a portion of the vector dataset. Pinecone automatically partitions vectors across pods, allowing the index to grow as more pods are added. During query execution, Pinecone sends the query to all pods in parallel. Each pod searches only its local partition and returns partial top-k matches. Pinecone's internal routing layer merges and re-ranks these partial results to produce the final global top-k.
- Horizontal scalability is controlled through two parameters: pods and replicas. Increasing the number of pods expands total storage capacity and distributes the search workload across more partitions. Replicas are full copies of the index stored on separate pod groups. Replicas do not increase total storage capacity, but they multiply available compute resources, improving query throughput (QPS) and providing high availability.
- Replication and rebalancing are automatic. New replicas synchronize in the background, and Pinecone places them across availability zones so that the index remains available even if a node fails. Pod-based deployments provide predictable performance and costs, making them suitable for production workloads with stable traffic patterns.
Serverless Indexes
- Pinecone automatically manages all infrastructure, scaling compute and storage independently based on usage. There are no pods to configure - capacity scales up and down dynamically without manual intervention. Billing is based on actual read/write request units and storage consumed rather than provisioned capacity. Serverless is recommended for development, variable workloads, and applications with unpredictable traffic patterns. It eliminates capacity planning but may have higher per-operation costs at scale compared to optimally-sized, pod-based deployments.
4. Application Integration and Result Model
MongoDB exposes vectors and application attributes through a unified query interface. Similarity scoring, filtering, and projection execute within the same context, allowing queries to mix vector and non-vector predicates. Results are returned as full documents, making additional lookups unnecessary.
Pinecone integrates at the application layer. Queries return vector matches with their metadata, while enrichment, joining, or context retrieval must be performed by the calling system. Its operations focus on upsert, query, delete, and similarity scoring. Returned results consist of vector IDs, distances, and optional metadata; obtaining full application data typically requires an external data store.
Both pod-based and serverless Pinecone indexes expose the same query API, so applications can switch between deployment models without code changes.
5. Querying
Both systems support vector similarity search, but they expose this capability through different query models. MongoDB integrates vector search directly into its aggregation pipeline, allowing vector and non-vector predicates to run within a single query. Pinecone, in contrast, offers a client-driven API focused on vector lookup, with optional metadata filtering and application-level enrichment. The following examples illustrate how queries are structured in each system.
MongoDB uses an aggregation pipeline stage called $vectorSearch to perform vector similarity queries on stored embeddings. For example, to find the five nearest vectors to a given query embedding (with approximate search) in a collection, you can run an aggregation like:
db.movies.aggregate([
{
$vectorSearch: {
index: "vector_index", // Name of the Search index
path: "plot_embedding", // Vector field to search
queryVector: [0.12, -0.45, 0.33, ...], // The query embedding vector
limit: 5, // Top-K results to return
numCandidates: 100, // Candidates to consider
filter: { // Optional metadata filter
genre: "Action",
year: { $in: [1999, 2000] }
},
exact: false // Use ANN (false) or exact search (true)
}
},
{
$project: {
title: 1,
score: { $meta: "vectorSearchScore" } // Include similarity score in results
}
},
{
$project: {
title: 1,
score: { $meta: "vectorSearchScore" } // Include similarity score in results
}
},
])
In this query, the $vectorSearch stage specifies the vector index, the field path containing vectors, the query vector, and parameters like limit (top-k) and numCandidates for ANN searches. The filter object is used to pre-filter documents (e.g., only "Action" movies from 1999 or 2000) before performing the similarity search. The exact flag toggles between approximate nearest neighbor (ANN) search using the index (for speed) and exact nearest neighbor (ENN) linear scan (for maximum accuracy). After the search, the example uses $project with $meta: "vectorSearchScore" to return the similarity score for each result alongside the movie title. By default, results from $vectorSearch come sorted by similarity score (highest relevance first).
MongoDB supports pre-filtering on indexed scalar fields using a standard query (filter) document with logical operators such as $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $and, $or. Only fields defined as filter-fields in the search index can be used for this purpose. Supported types include boolean, numeric, string, date, UUID, and similar.
The similarity value is returned as vectorSearchScore, normalized to a range of 0–1. For cosine and dot-product metrics, MongoDB applies (1 + sim) / 2, ensuring scores fall within [0, 1].
Result ranking is controlled by the limit parameter of $vectorSearch, which returns the top-N most similar documents. Results are implicitly sorted by descending similarity, and $sort is not allowed within the $vectorSearch stage.
Pinecone provides a client API for vector queries. Using the Python SDK, a typical query looks like:
import pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="us-west1-gcp")
index = pinecone.Index("my-index")
query_vector = [0.12, -0.45, 0.33, ...] # the query embedding vector
response = index.query(
namespace="movies", # optional namespace to partition data
vector=query_vector,
top_k=5, # top-K results
filter={"genre": {"$in": ["Action", "Adventure"]}}, # metadata filter
include_values=False, # whether to return full vector values
include_metadata=True # return metadata fields in results
)
for match in response["matches"]:
print(match["id"], match["score"], match.get("metadata"))
This Pinecone query searches the "my-index" index (within the "movies" namespace) for the five most similar vectors to query_vector. The filter specifies a metadata condition (here, using Pinecone’s filter syntax to require genre is "Action" or "Adventure"). The results will include each match’s ID and a similarity score, and because include_metadata=True, any stored metadata (like title, year, etc.) will be returned as well. By default, the returned matches are ordered from most similar to least similar. The include_values flag can be set to True if you want the raw vector values in the output (omitted above for brevity). The example above uses the Python client, but Pinecone offers similar query methods in other languages (JavaScript, Java, Go, C#, etc.) and a REST/GRPC API.
Pinecone supports flexible metadata filtering via JSON filter expressions (e.g., $eq, $in, $and) supplied in Index.query. Filters may reference any stored metadata fields, such as:
{ "genre": { "$eq": "drama" }, "year": { "$gte": 2020 } }
Each match includes a score representing the similarity or distance, depending on the index metric. For example, with Euclidean distance, lower values indicate closer neighbors, while with cosine similarity, higher values are better.
Query results are controlled using top_k, which specifies how many closest matches to return. Pinecone always returns results ordered by similarity/distance; sorting on non-vector attributes is not supported.
Running MongoDB Vector Search and Pinecone
MongoDB Vector Search can run either in a fully managed cloud environment (Atlas) or self-managed on-premises/cloud VMs. Pinecone, by contrast, is available only as a managed cloud service and cannot be deployed on-prem. Both MongoDB Atlas and Pinecone offload infrastructure management, but MongoDB additionally provides on-prem options via Community and Enterprise distributions. Pinecone offers simpler SaaS usage at the cost of deployment flexibility.
1. MongoDB Atlas (managed cloud)
MongoDB Atlas is a fully managed service that supports vector search. You enable a vector index and query it using the $vectorSearch operator. MongoDB Atlas runs on AWS, GCP, and Azure. A free M0 tier is available for development. Atlas itself cannot run on-prem.
2. MongoDB Community Edition (self-managed)
MongoDB Community is free to install and can run on-prem or on any cloud VM. Native vector search is supported in recent versions via the companion mongot process. Deployment and operations are fully user-managed. The software is free.
3. MongoDB Enterprise Advanced (self-managed)
MongoDB Enterprise can be deployed on-prem or in a private/public cloud and supports vector search. Search nodes run mongot alongside mongod; a Kubernetes Operator is available for orchestration in enterprise environments. It requires a commercial license.
4. Pinecone (managed cloud)
Pinecone is a fully managed SaaS vector database. It cannot run on-prem and has no self-hosted version. You create an index through the console or API and query vectors via Pinecone endpoints. It operates in AWS, GCP, and Azure regions. A free Starter plan is available for prototyping.
Product | Cloud | On-premises | Free tier | Local dev (laptop) | Notes |
|---|---|---|---|---|---|
MongoDB Atlas | (AWS, GCP, Azure) | ❌ | ✅ | ✅ via Atlas CLI dev cluster* | Fully managed |
MongoDB CE | (self-host) | ✅ | ✅ | ✅ | Self-managed deployment; supports vector search when paired with mongot |
MongoDB EA | (self-host) | ✅ | ❌ | ✅ | Commercial; Enterprise support |
Pinecone (serverless) | (AWS, GCP, Azure) | ❌ | ✅ | ❌ | Auto-scaling, per-per-use |
Pinecone (pod-based) | (AWS, GCP, Azure) | ❌ | ❌ | ❌ | Fixed capacity, predictable cost |
The MongoDB Atlas CLI local-dev allows you to run a lightweight Atlas-compatible environment locally, using Docker, to develop and test vector search without requiring a cloud cluster.
Embedding Models and Pipelines
MongoDB provides vector search but does not generate embeddings inside the database. Applications must produce vectors externally using providers such as OpenAI, Cohere, Hugging Face, or Voyage AI, and then store them as fields in MongoDB documents. MongoDB highlights Voyage AI as a high-quality option, but developers may choose any embedding model.
Embedding pipelines are typically implemented in application code or through MongoDB Atlas features such as Triggers. These workflows fetch raw data, call an embedding model, and save the resulting vectors to MongoDB. Once vectors are stored, developers define a vector search index on the field and query using $vectorSearch. MongoDB also integrates with RAG frameworks like LangChain and LlamaIndex to automate embedding + indexing.
Embedding Dimensions and Limits
- MongoDB supports vectors of varying dimensions, constrained primarily by the 16 MB BSON document size limit. Common embedding models use 384-1536 dimensions (e.g., OpenAI ada-002 uses 1536), which poses no practical constraint.
- Pinecone accepts embeddings up to 20,000 dimensions. Its hosted inference models typically generate embeddings between 384 and 1024 dimensions.
Pinecone is a dedicated vector database that accepts embeddings from any model and additionally provides integrated inference. Its hosted model catalog includes:
- NVIDIA llama-text-embed-v2.
- Microsoft multilingual-e5-large.
- Pinecone-sparse-english-v0.
- OpenAI text-embedding-3-large.
- Rerankers (Pinecone, Cohere, open-source).
If you choose the integrated embedding option, Pinecone will automatically handle the conversion of text into vector embeddings when you upsert and search.
Developers can generate vectors directly via the Pinecone inference API or bring vectors generated externally (e.g., OpenAI, Hugging Face). Newer workflows also support one-step operations that both embed and index data. Pinecone offers SDKs (Python, JS, Java, Go, C#, etc.) and REST/gRPC APIs for integration.
Summary
MongoDB Vector Search and Pinecone serve different priorities when it comes to performance and application fit. MongoDB Vector Search is integrated into a general-purpose database and provides both approximate and exact search modes. It uses Lucene-based indexes powered by the HNSW algorithm and relies on a separate search daemon called mongot for executing similarity queries. Performance can vary depending on dataset size, query parameters, and index configuration, but it benefits from tight integration with MongoDB’s query engine and support for hybrid queries combining vector similarity with structured filtering.
Pinecone, in contrast, is built as a dedicated high-performance managed vector database. Its architecture is optimized for low-latency, high-throughput top-k vector retrieval and supports automatic scaling (across distributed compute pods in pod-based deployments, or fully managed infrastructure in serverless). It abstracts all infrastructure, making it more predictable and performant at scale, especially when handling large embedding corpora.
In terms of use cases, MongoDB Vector Search is a strong choice when semantic search must be embedded within a broader document or transactional workflow. This includes personalized product recommendations, hybrid retrieval pipelines, or search experiences where vector data and application metadata are tightly coupled. Pinecone is best suited for workloads where vector similarity is the central operation and where simplicity, speed, and scalability are the highest priorities. Examples include semantic search engines, real-time personalization systems, or AI applications querying large vector indexes.
Both platforms support production-grade performance but align with different architectural goals. MongoDB emphasizes integration and flexibility across use cases that combine structured and semantic queries, while Pinecone focuses on specialization and managed scalability for high-throughput vector search.