Context-Augmented Generation (CAG) enhances text generation by incorporating contextual information such as user intent and domain knowledge. It maintains coherence through contextual retrieval, enriching each chunk with meaningful details before embedding. This approach enables accurate and personalised responses ideal for chatbots and digital assistants that require conversational continuity.
Importance of Contextual Generation
CAG offers a significant improvement over Retrieval Augmented Generation (RAG) by focusing on understanding and preserving meaning rather than just retrieving information. While RAG often loses semantic connections when splitting text, CAG uses each chunk with contextual understanding, ensuring more accurate and coherent outputs.
- Enhances Personalization: Incorporates user intent, preferences and conversation history making responses more relevant and tailored.
- Reduces Retrieval Errors: Contextually enriched chunks improve retrieval accuracy and reduce the chances of incomplete or irrelevant responses.
- Improves Coherence: Generates more logically connected and human-like answers by using contextual relationships between data points.
- Minimizes External Dependence: Relies less on continuous external retrieval, as contextual knowledge is embedded within the stored data itself.
- Ideal for Interactive Systems: Performs exceptionally well in chatbots, virtual assistants and recommendation systems that require ongoing dialogue continuity.
How Does CAG Operate?
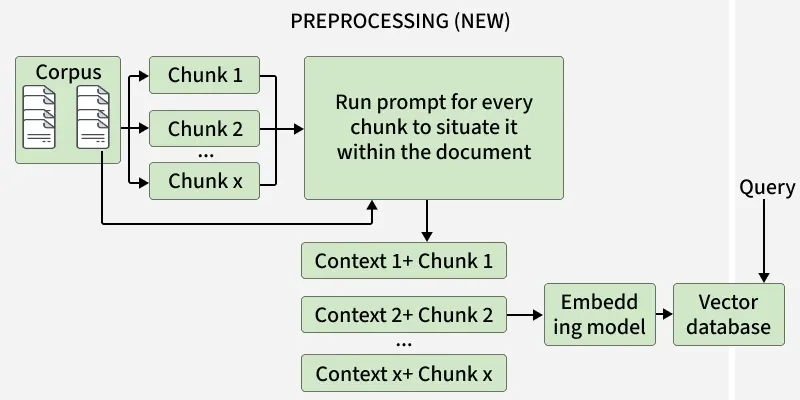
- Document Chunking: The input document or dataset is first divided into smaller, manageable chunks to facilitate processing and embedding.
- Contextual Enrichment: Each chunk is passed to a Large Language Model (LLM) which generates additional explanatory or contextual information related to that chunk. This step ensures that even when chunks are separated, their meaning and relationships are preserved.
- Vector Store Creation: The enriched chunks, now containing both original and contextual details are embedded into high-dimensional vectors and stored in a vector database for efficient retrieval.
- Query Processing: When a user submits a query, it is analyzed to capture context such as previous interactions, user intent or domain relevance before performing retrieval.
- Contextual Retrieval: Relevant enriched chunks are fetched from the vector store based on semantic similarity and query context, ensuring more precise and meaningful results.
- Response Generation: The retrieved contextual information and user query are combined and passed to the LLM which generates a coherent, factually grounded and personalized response.
- Continuous Learning: The system can update stored contexts dynamically as new data or user interactions occur, enhancing adaptability and maintaining relevance over time.
Step-By-Step Implementation
Here we split a document into chunks, enrich each chunk with contextual meaning using an LLM and then retrieve the most relevant enriched chunks based on user queries to generate coherent, context-aware responses.
Step 1: Import Dependencies
- Import modules for embeddings, LLM communication and utility operations.
- os handles environment variables.
from sentence_transformers import SentenceTransformer, util
from langchain_google_genai import ChatGoogleGenerativeAI
import textwrap, os
Step 2: Configure API Key and Initialize Models
- Set up your Google API key to authenticate Gemini usage.
- Load the lightweight MiniLM model for embeddings and Gemini for text generation.
os.environ["GOOGLE_API_KEY"] = "API KEY"
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.7)
embedder = SentenceTransformer('all-MiniLM-L6-v2')
Output:
Step 3: Sample Document
- Define the text that will be processed through the Contextual Augmented Generation pipeline.
- This document will be split into chunks for enrichment and retrieval.
document = """
Contextual Augmented Generation (CAG) is an advancement over Retrieval Augmented Generation (RAG).
Unlike RAG, which simply retrieves and attaches chunks of text, CAG enriches each chunk by adding contextual cues.
This allows the model to understand the relationship between different sections of a document.
As a result, it can generate more coherent and contextually aware answers.
CAG is particularly useful for chatbots, customer support, and multi-turn dialogue systems.
"""
Step 4: Create Chunks from the Document
- This function splits the document into small, manageable parts for embedding.
- Chunk size determines how much text each segment contains.
def create_chunks(text, chunk_size=10):
words = text.split()
chunks = [' '.join(words[i:i + chunk_size]) for i in range(0, len(words), chunk_size)]
return chunks
chunks = create_chunks(document)
print("Original Chunks:\n")
for i, ch in enumerate(chunks):
print(f"Chunk {i+1}:", textwrap.fill(ch, width=80), "\n")
Output:

Step 5: Enrich Each Chunk Using the LLM
- The enrichment step gives each chunk additional context within the whole document.
- The prompt ensures Gemini adds short, factual connections without inventing new content.
def enrich_chunk(chunk, full_doc):
prompt = f"""
You are enhancing chunks of a document for contextual retrieval.
<document>
{full_doc}
</document>
Here is the specific chunk:
<chunk>
{chunk}
</chunk>
Task:
1. Explain how this chunk connects logically to the overall document
2. Write your answer as a short, factual, and context-rich summary.
3. Do not copy the chunk itself or restate it.
Answer:
"""
response = llm.invoke(prompt)
return response.content.strip()
print("\nEnriched Chunks:\n")
enriched_chunks = []
for ch in chunks:
enriched_text = enrich_chunk(ch, document)
enriched_chunks.append(enriched_text)
print("-", enriched_text, "\n")
Step 6: Create Embeddings for Enriched Chunks
- Transform enriched chunks into dense vectors that capture their semantic meaning.
- These embeddings allow similarity search between queries and stored chunks.
embeddings = embedder.encode(enriched_chunks, convert_to_tensor=True)
enriched_embeddings
Output:

Step 7: Implement Question Answering via Similarity Search
When the user asks a question it:
- Convert it to an embedding.
- Compare it to all enriched chunk embeddings using cosine similarity.
- Select top-k most relevant chunks.
- Pass them as context to the LLM for a grounded answer.
def answer_question(question, enriched_chunks, embeddings, top_k=2):
question_embedding = embedder.encode(question, convert_to_tensor=True)
cos_scores = util.cos_sim(question_embedding, embeddings)[0]
top_results = cos_scores.topk(k=top_k)
context = "\n".join([enriched_chunks[idx] for idx in top_results[1]])
prompt = f"""
You are an intelligent assistant. Use only the context below to answer the question.
Context:
{context}
Question:
{question}
Answer:
"""
response = llm.invoke(prompt)
return response.content.strip()
Step 8: Generate Response
- Demonstrates the complete CAG workflow from enrichment to retrieval-based generation.
- The model answers using the enriched, contextually grounded chunks.
question = "How does CAG differ from RAG?"
answer = answer_question(question, enriched_chunks, embeddings)
print("Question:", question)
print("\nAnswer:", answer)
Output:
Question: How does CAG differ from RAG?
Answer: CAG enriches each retrieved chunk by adding contextual cues, whereas RAG simply retrieves and attaches chunks of text.
You can download the complete code file from here.
Performance Boosting with Reranking
In Context Augmented Generation (CAG), reranking serves as a useful technique to refine generated results and improve output quality. After multiple candidate responses are produced, reranking helps select the one that best fits the user query and context.
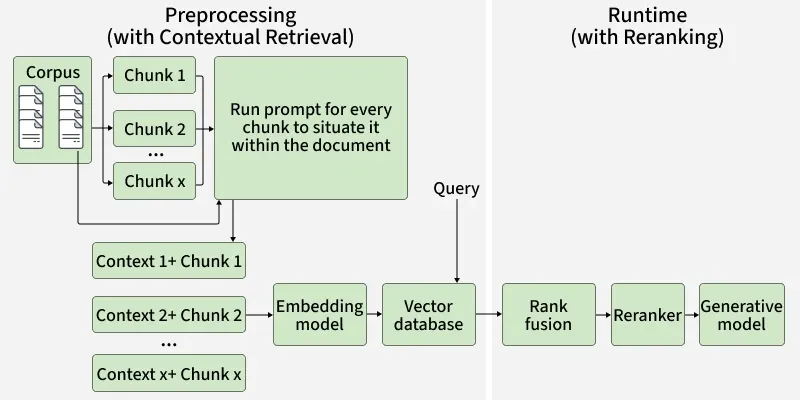
- Reranking reorders retrieved chunks based on their semantic relevance to the query.
- This step ensures the final output aligns closely with the intended meaning.
- Reduces token load and latency by processing fewer, high-quality chunks.
- Produces more precise and context-aware results.
- It significantly enhances the overall performance of CAG systems.
RAG vs CAG
The following table compares RAG and CAG:
Parameters | Retrieval-Augmented Generation (RAG) | Contextual-Augmented Generation (CAG) |
|---|---|---|
Core Idea | Retrieve relevant chunks from a knowledge base and use an LLM to generate context-aware responses | Enhance retrieval by enriching each chunk with additional context |
Chunk handling | Documents are divided into chunks that may miss broader context, leading to less accurate retrievals | Each chunk is enriched with brief context before embedding to preserve meaning |
Ideal use cases | Best for retrieving factual data when minor context loss is acceptable | Ideal for context-heavy tasks like multi-turn chats or complex document understanding. |
Limitations | May retrieve incomplete chunks, causing context loss or hallucinations. | Adds extra preprocessing (LLM enrichment), larger embeddings and higher cost or latency. |
Application of CAG
- Conversational AI: Enriches chatbots and virtual assistants by keeping context over turns.
- Customer Support: It remembers past interactions for accurate and personalized responses.
- Knowledge Retrieval: Provides context-aware answers from large-scale enterprise or research databases.
- Healthcare & Legal: Analyzes records and case files while maintaining contextual relationships.
- Recommendations: It uses user behavior and context to generate smarter suggestions.
- Education: Summarizes content, makes study notes and answers queries with contextual grounding.
- Software Development: Remembers code context to provide precisely relevant code snippets.
Disadvantages
- Higher Cost: Additional LLM calls and processing increase computational overhead.
- Complex Pipelines: Multiple steps like context creation, augmentation and embedding are hard to handle.
- Risk of Bias: Poorly generated context may add irrelevant or biased information.
- Larger Storage: The enriched chunks lead to larger embedding sizes.
- Model Dependency: The quality depends on how well the LLM can generate meaningful context.
- Reduced Payoff: Provides less reward for basic fact-retrieval questions.