StyleGAN is a generative model developed by NVIDIA that produces highly realistic images by controlling image features at multiple levels, from overall structure to fine details such as texture and lighting. Unlike traditional GANs, StyleGAN separates style from content, allowing precise control over the appearance of generated images.
- Generates highly realistic and detailed images
- Controls features at multiple levels
- Separates style from content for better control
- Commonly used for realistic human face generation
- Produces images that may not exist in reality
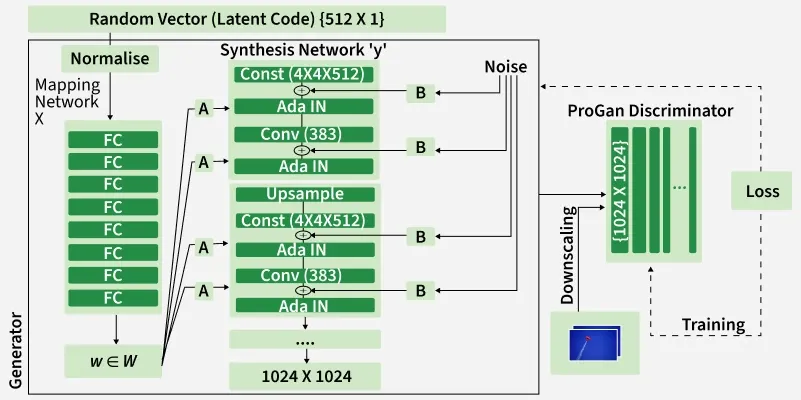
Architecture of StyleGAN
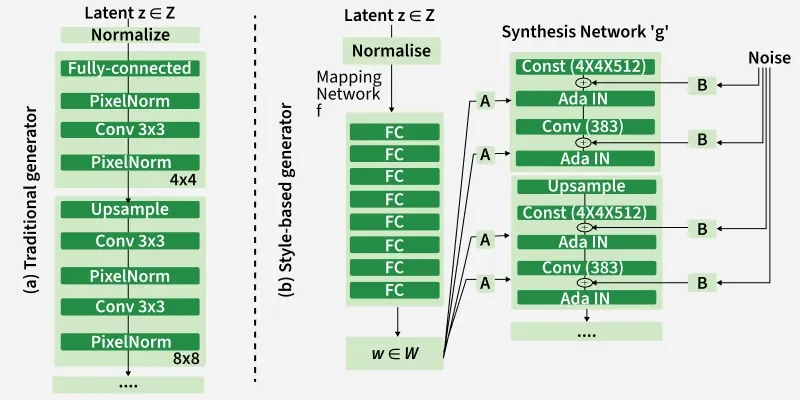
StyleGAN improves traditional GAN architecture by modifying the generator to achieve better control over image features and higher image quality.
1. Progressive Growing of Images
StyleGAN starts training with low-resolution images and gradually increases the resolution up to 1024×1024. This stabilizes training and helps the model learn coarse structures before fine details.
- New layers are gradually added to both the generator and discriminator during training.
- This approach stabilizes training by allowing the model to first learn coarse structures before adding fine details.
- Progressive growing leads to smoother training and better image quality overall.
2. Bi-linear Sampling
StyleGAN uses bi-linear sampling instead of nearest-neighbor sampling for resizing feature maps, producing smoother transitions and reducing artifacts.
- Produces smoother images
- Reduces pixelation and artifacts
- Improves visual realism
3. Mapping Network and Style Network
Inplace of feeding a random latent vector
- This produces an intermediate vector
w which controls image features like texture and lighting. - The vector
w is transformed using an affine transformation and then fed into an Adaptive Instance Normalization (AdaIN) layer.
The input to the AdaIN is
AdaIN (x_i, y) = y_{s, i}\left ( \left ( x_i - \mu_i \right )/ \sigma_i \right )) + y_{b, i}
where each feature map
4. Constant Input and Noise Injection
StyleGAN uses a learned constant tensor instead of random noise as the generator input. Gaussian noise is added at each layer to create realistic random details such as freckles, wrinkles, and hair variations.
- This focuses the model on applying style changes rather than learning basic structure from noise.
- To add natural-looking random variations like skin pores, wrinkles or freckles, Gaussian noise is added independently to each convolutional layer during synthesis.
- This noise introduces stochastic detail without affecting overall structure helps in improving realism.
5. Mixing Regularization
Two latent vectors are mixed during training so different layers receive different styles. This improves feature diversity and robustness.
- Two different latent vectors
z_1 andz_2 are sampled and mixed by applying them to different layers in the generator. - This forces the model to produce consistent images even when styles change mid-way helps in improving robustness of features.
6. Style Control at Different Resolutions
StyleGAN’s synthesis network controls image style at different resolutions each affecting different aspects of the image:

- Coarse Resolution (4×4 to 8×8): Affects major features like pose and general shape.
- Middle Resolution (16×16 to 32×32): Affects facial features, hair, eyes etc.
- Fine Resolution (64×64 to 1024×1024): Controls finer details like colors and micro-features.
7. Feature Disentanglement Studies
To understand how well it separates features, two key metrics are used:
- Perceptual Path Length: Measures how smooth the transition between two generated images is when interpolating between their latent vectors. Shorter path length shows smoother changes.
- Linear Separability: Tests whether certain features like gender, age, etc and can be separated using a simple linear classifier in the latent space which shows how well features are disentangled .
Applications
- Generates realistic human faces for gaming, entertainment, virtual avatars and digital media
- Helps fashion designers create and explore new clothing styles, colors and patterns
- Produces synthetic images for data augmentation in machine learning tasks
- Supports realistic character and NPC creation in animation and video games
- Enables high-quality image editing and enhancement applications
Limitations
- Requires high computational power and long training time
- Training can become unstable on complex datasets
- Output quality depends heavily on training data quality
- May generate biased or unrealistic images in some cases
- Difficult to achieve precise control over specific image attributes
- Can be misused for generating fake or misleading media