Generative Pre trained Transformer (GPT) is a language model that understands and generates human like text. It learns patterns and relationships between words from large data and can perform multiple language tasks using a single model.
- Text Understanding: GPT can read and understand human language.
- Text Generation: It can generate meaningful and natural sounding text.
- Learning from Data: It is trained on large datasets to learn language patterns.
- Multiple Tasks: It can write, summarize, answer questions and even help in coding.
- Context Awareness: It understands how words relate to each other to give relevant responses.
How GPT Works
GPT models are built upon the transformer architecture, introduced in 2017, which uses self attention mechanisms to process input data in parallel, allowing for efficient handling of long range dependencies in text. The core process involves:
- Pre-training: The model is trained on vast amounts of text data to learn language patterns, grammar, facts and some reasoning abilities.
- Fine-tuning: The pre-trained model is further trained on specific datasets with human feedback to align its responses with desired outputs.
Architecture
Let's explore the architecture:
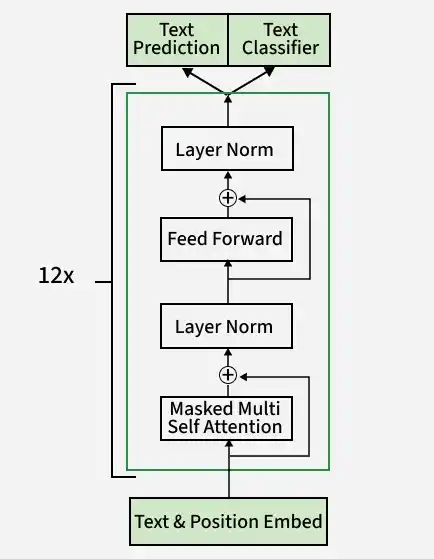
1. Input Embedding
- Input: The text is first broken into tokens (words or subwords).
- Embedding: Each token is converted into a dense vector representation.
2. Positional Information
Since the model does not understand order by default, positional information is added to the embeddings to preserve sequence order.
3. Decoder Blocks
- LayerNorm: Each block starts with layer normalization.
- Masked Multi-Head Self-Attention: The model attends only to previous tokens using multiple attention heads.
- Add & Norm: The attention output is added to the input (residual connection) and normalized.
- Feed Forward: A feed-forward network (Linear -> GeLU -> Linear) processes the data further.
- Add & Norm: Again, the output is added back and normalized.
4. Layer Stack
Multiple decoder blocks are stacked (e.g., 12 blocks) to capture deeper patterns and relationships in the text.
5. Final Layers
- LayerNorm: A final normalization is applied.
- Linear: The output is mapped to the vocabulary size.
- Softmax: Probabilities are generated for predicting the next token or task output.
GPT Evolution
GPT models have evolved rapidly, improving in scale, reasoning and real world performance. Earlier versions focused on basic language patterns, while newer models handle complex tasks more effectively.
1. Early Development
- GPT (2018): Introduced the idea of pre-training + fine-tuning for language tasks.
- GPT-2 (2019): Improved text generation and coherence with larger scale.
2. Scaling Phase
GPT-3 (2020) was a major improvement in size and performance, capable of few-shot and zero-shot learning.
3. Advanced Capabilities
GPT-4 (2023) introduced better reasoning, improved context understanding, and multimodal abilities.
4. Recent Improvements
GPT-4.1 / 4.5 (2025) brought improved coding, longer context handling, and better instruction following.
5. Current Generation:
GPT-5 (2026) is a more advanced and efficient system that balances speed and deep reasoning. It shows improvements in accuracy, reduced errors, better understanding of complex tasks and stronger performance across coding, reasoning and real world applications.
Applications
- Content Creation: GPT can generate articles, stories and poetry, assisting writers with creative tasks.
- Customer Support: Automated chatbots and virtual assistants powered by GPT provide efficient and human-like customer service interactions.
- Education: GPT models can create personalized tutoring systems, generate educational content and assist with language learning.
- Programming: GPT's ability to generate code from natural language descriptions aids developers in software development and debugging.
- Healthcare: Applications include generating medical reports, assisting in research by summarizing scientific literature and providing conversational agents for patient support.
Advantages
- Versatility: Capable of handling diverse tasks with minimal adaptation.
- Contextual Understanding: Deep learning enables comprehension of complex text..
- Scalability: Performance improves with data size and model parameters.
- Few-Shot Learning: Learns new tasks from limited examples.
- Creativity: Generates novel and coherent content.
Ethical Considerations
- Bias: Models inherit biases from training data.
- Misinformation: Can generate convincing but false content.
- Resource Intensive: Large models require substantial computational power.
- Transparency: Hard to interpret reasoning behind outputs.
- Job Displacement: Automation of language based tasks may impact employment.