BERT (Bidirectional Encoder Representations from Transformers) is a natural language processing model developed by Google that understands the context of words in a sentence by analyzing text in both directions. It is widely used to improve language understanding tasks with high accuracy.
- Uses a transformer-based encoder architecture
- Processes text bidirectionally (left and right context)
- Captures contextual relationships between words
- Designed for language understanding tasks like classification, question answering, and Named Entity Recognition (NER)
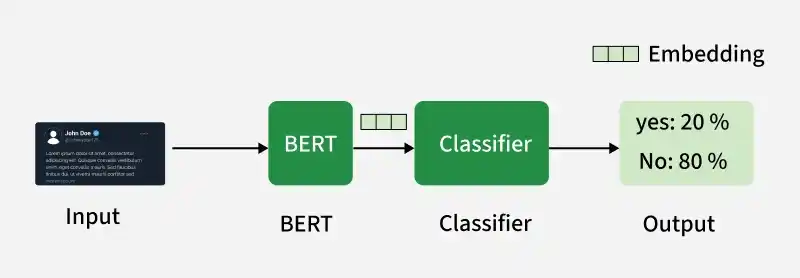
BERT Pre-training
BERT is trained on large amounts of unlabeled text to learn contextual representations of words based on their surrounding context.
- Learns embeddings that capture meaning using both left and right context
- Trained using unsupervised learning on large text datasets
- Uses tasks like predicting masked words (MLM)
- Learns relationships between sentences using Next Sentence Prediction (NSP)
Workflow of BERT
BERT uses a transformer-based encoder to process input text and generate contextualized representations for each token. Instead of predicting text sequentially like traditional models, it focuses on understanding context using its training strategies.
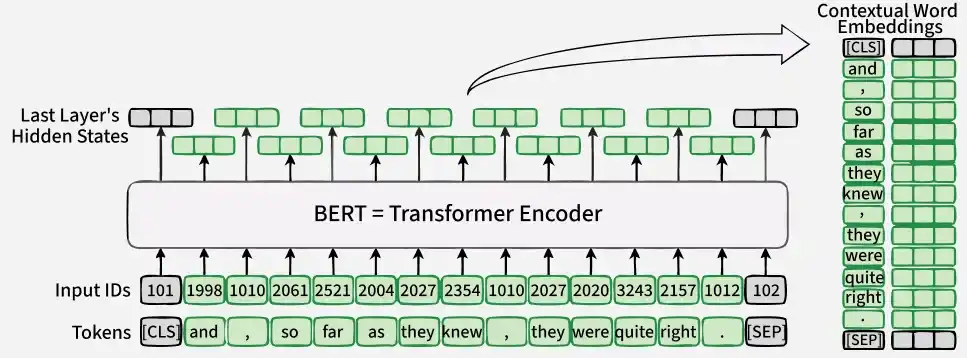
- Input tokens are converted into embeddings and passed through the Transformer encoder
- Produces contextual vectors for each token in the sequence
- Unlike directional models, it does not rely only on left-to-right or right-to-left processing
- Uses Masked Language Model (MLM) to predict missing words based on context
- Uses Next Sentence Prediction (NSP) to learn relationships between sentences
1. Masked Language Model (MLM)
In BERT’s pre-training, some words in the input sequence are masked, and the model learns to predict these missing words using the surrounding context.
- A classification layer is added on top of the encoder outputs to predict masked words
- Output vectors are projected to the vocabulary space using the embedding matrix
- Softmax is applied to generate probability distribution over all possible words
- Loss is calculated only for masked positions, comparing predicted and actual words
- Focus on masked tokens may slow convergence compared to directional models
- However, it enables deeper contextual understanding by using both left and right context
2. Next Sentence Prediction (NSP)
Next Sentence Prediction trains BERT to understand the relationship between two sentences by predicting whether one sentence follows another.
- Uses the [CLS] token representation, passed through a classification layer
- Outputs probabilities (via Softmax) to determine if the second sentence is related
- During training, 50% of sentence pairs are actual consecutive sentences, while 50% are randomly paired
- Helps the model distinguish between logically connected and unrelated sentences
- Improves performance in tasks requiring sentence-level understanding like question answering
Combined Training of MLM and NSP
BERT is trained using both Masked Language Model (MLM) and Next Sentence Prediction (NSP) simultaneously. The model minimizes a combined loss function from both tasks, enabling it to learn deeper language understanding.
- MLM helps the model understand context within a sentence by predicting masked words
- NSP helps capture relationships between pairs of sentences
- Training both together improves understanding at both word-level and sentence-level
- Results in a more comprehensive and context-aware language model
BERT Fine-Tuning
After pre-training, BERT is fine-tuned on labeled data to adapt it for specific NLP tasks. This step customizes the model’s general language understanding for particular applications.
- Uses labeled datasets for task-specific training
- Adjusts model parameters based on the target task
- Applied to tasks like sentiment analysis, question answering and NER
- Requires minimal architectural changes due to its flexible design
- Enhances performance by aligning the model with task specific requirements
BERT Architecture
BERT uses a multilayer bidirectional Transformer encoder to understand text by capturing context from both directions. Unlike the original Transformer, which has both encoder and decoder, BERT uses only the encoder for language understanding tasks.
- Built on a stack of Transformer encoder layers using self-attention and feed-forward networks
- BERTBASE has 12 layers in the Encoder stack while BERTLARGE has 24 layers in the Encoder stack.
- BERT architectures (BASE and LARGE) also have larger feedforward networks (768 and 1024 hidden units respectively), and more attention heads (12 and 16 respectively) than the Transformer architecture suggested in the original paper. It contains 512 hidden units and 8 attention heads.
- BERTBASE contains 110M parameters while BERTLARGE has 340M parameters.
.jpg)
Input and Processing
- Input starts with a [CLS] token followed by the sequence of words
- Each token is converted into embeddings and passed through encoder layers
- Each layer applies self-attention and feed-forward transformations
- Outputs contextualized vectors for each token
.jpg)
Output Usage
- The [CLS] token output is used for classification tasks
- Final embeddings can be used for tasks like classification, translation and more
- Even a simple neural layer on top of BERT can achieve strong performance
Applications of BERT in NLP
BERT can be applied to a wide range of natural language processing tasks by adding task specific layers on top of its encoder outputs.
1. Text Classification
- Used for tasks like sentiment analysis and category prediction
- The [CLS] token represents the entire input sequence
- A classification layer is added on top to make predictions
2. Question Answering
- Identifies the answer span within a given passage
- Learns to predict start and end positions of the answer
- Trained using question passage pairs
3. Named Entity Recognition (NER)
- Identifies entities such as names, organizations and locations
- Uses token-level outputs from BERT
- A classification layer predicts labels for each token
Tokenization and Encoding with BERT
BERT uses a tokenizer to convert text into token IDs that can be processed by the model.
Step1: Run the following command in you command prompt
pip install transformers
Step2: Load the pretrained BERT tokenizer
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
Step3: Convert text into token IDs
encoding = tokenizer.encode(text)
print("Token IDs:", encoding)
Output:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102]
Step3: Convert token IDs back to tokens
tokens = tokenizer.convert_ids_to_tokens(encoding)
print("Tokens:", tokens)
Output:
Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']
Applications of BERT
- Generates contextual embeddings for words and sentences
- Used in Named Entity Recognition (NER) to identify entities like names, locations, and organizations
- Applied in text classification tasks such as sentiment analysis, spam detection, and topic categorization
- Powers question-answering systems by identifying relevant answer spans in text
- Improves machine translation by capturing language context
- Used in text summarization to create concise representations of content
- Supports conversational AI systems like chatbots and virtual assistants
- Helps measure semantic similarity for tasks like duplicate detection and information retrievalBERT vs GPT
BERT vs GPT
| Feature | BERT | GPT |
|---|---|---|
Architecture | Bidirectional; predicts masked words based on left, right context. | Unidirectional; predicts next word given preceding context. |
| Pre-training Objectives | BERT is pre-trained using a masked language model objective and next sentence prediction. | GPT is pre-trained using Next word prediction only. |
| Context Understanding | Strong at understanding and analyzing text. | Strong in generating coherent and contextually relevant text. |
Tasks and Use Cases
| Commonly used in tasks like text classification, NER, sentiment analysis, and QA | Applied to tasks like text generation, chat, summarization, etc. |
| Fine-tuning vs Few-Shot Learning | Fine-tuning with labeled data to adapt its pre-trained representations to the task at hand. | GPT is designed to perform few-shot or zero-shot learning, where it can generalize with minimal task-specific data. |