Hugging Face embeddings are numerical vector representations of data such as words, sentences or images generated using pre trained models available on the Hugging Face platform.
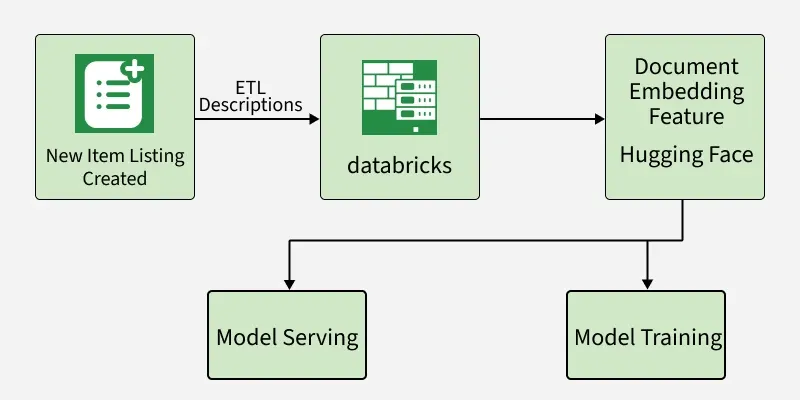
These embeddings capture semantic meaning, context and relationships within the data helping machines to perform tasks like search, classification, clustering and recommendation more effectively.
What are Embeddings?
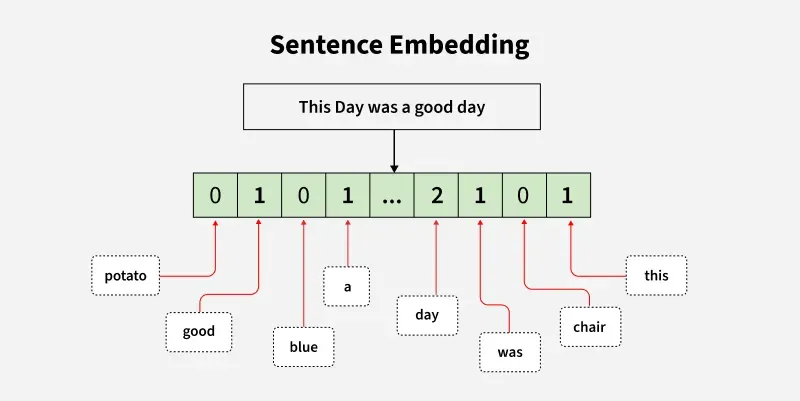
- Embeddings are dense numerical representations of data such as words, sentences or images in a continuous high-dimensional space where semantic relationships are preserved.
- Instead of treating text as separate tokens or raw characters embeddings map them into vectors (numeric representation) so that similar meanings are located closer together in this space.
- This transformation allows machine learning models to process and understand the meaning, context and similarity of data making embeddings essential for tasks like semantic search, recommendation systems, clustering and classification.
Hugging Face Embedding Models are pre trained machine learning models available on the Hugging Face platform and these models are designed to capture the semantic meaning and contextual relationships of the input making them useful for a wide range of tasks like semantic search, text classification, clustering and recommendations.
Many Hugging Face embedding models are built on popular transformer architectures such as BERT, RoBERTa, DistilBERT and Sentence Transformers and can be easily loaded through the transformers or sentence transformers libraries. For example:
- sentence-transformers/all-MiniLM-L6-v2: Fast and lightweight, great for semantic similarity tasks.
- BAAI/bge-base-en: Optimized for retrieval and ranking in search applications.
- Multilingual models: Capable of producing embeddings for multiple languages, enabling cross-lingual semantic matching.
How do they Work?
Step 1: Tokenization
- The input text is first broken down into smaller units (tokens) using a tokenizer.
- For example, “Hugging Face is great” might become [Hugging, Face, is, great] or even subword pieces like ["Hugg", "ing", "Face", "is", "great"].
Step 2: Encoding with Transformer Layers
- These tokens are converted into initial numeric IDs and passed through the model’s transformer architecture like BERT or RoBERTa.
- Each transformer layer applies self attention to understand relationships between tokens.
- This helps capture context for example knowing that “bank” in “river bank” means something different from “bank account.”
Step 3: Contextualized Representations
- After multiple layers of processing each token has a vector that contains both its meaning and its relationship to surrounding words.
Step 4: Pooling to Get a Single Embedding
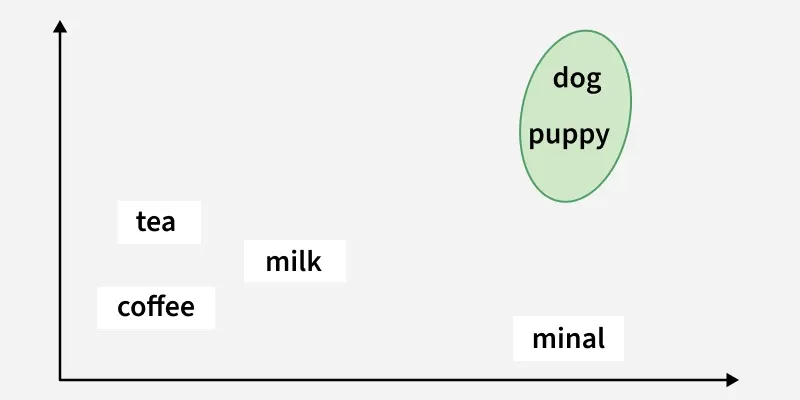
- For sentence or document embeddings the token vectors are combined into one fixed length vector.
- The result is a dense vector often with hundreds of dimensions where similar texts are located close together in the vector space.
- For Example The embeddings for “dog” and “puppy” will be closer than “tea” and “coffee”
Step 5: Usage in Downstream Tasks
- These embeddings can now be compared, clustered or fed into other ML models for search, classification, recommendations and more.
Implementation
- This code loads a pre trained Hugging Face Sentence Transformer model (all-MiniLM-L6-v2) to convert two sentences into numerical embeddings.
- The encode() method generates dense vector representations for each sentence and embeddings.shape shows their dimensions one vector per sentence each with a fixed number of features.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
sentences = [
"Hugging Face makes NLP easy.",
"Transformers are powerful for deep learning."
]
embeddings = model.encode(sentences)
print("Embedding shape:", embeddings.shape)
Output:
Embedding shape: (2, 384)
Applications
- Recommendation Systems: Content based recommendation engines use embeddings to suggest similar items whether articles, products or videos based on semantic similarity.
- Question Answering and Chatbots: Embeddings help match user queries to relevant answers, enabling more accurate and context aware responses.
- Cross Lingual Retrieval: Multilingual embedding models can compare and match meaning between texts written in different languages.
- Anomaly Detection: In security or data analysis embeddings can flag unusual items that don’t fit the learned semantic patterns.