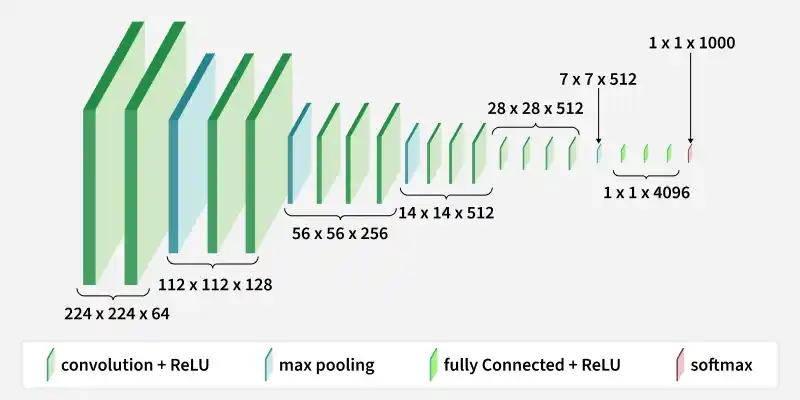
VGG-16 is a convolutional neural network (CNN) designed for image classification tasks, known for its simple and uniform architecture that delivers strong performance on visual recognition problems.
- Consists of 16 layers (13 convolutional + 3 fully connected layers)
- Uses repeated 3×3 convolution filters for feature extraction
- Applies max pooling between layers to reduce spatial dimensions
- Produces final predictions using fully connected layers with softmax
This model achieves 92.7% test accuracy on the ImageNet dataset which contains 14 million images belonging to 1000 classes.
VGG-16 Model Objective
The ImageNet dataset contains images of fixed size 224×224 with RGB channels, forming an input tensor of shape (224, 224, 3). The model processes this input and outputs a vector of 1000 values:
This vector represents the classification probabilities for each class. For example, if the model assigns different probabilities to classes such as 0, 1, 2, 3, 780, and 999, with all others being 0, the classification vector can be written as:
To make sure these probabilities add to 1, we use softmax function. This softmax function is defined as follows:
\hat{y}_i = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}}
After this we take the 5 most probable candidates into the vector.
and our ground truth vector is defined as follows:
Then we define our Error function as follows:
E = \frac{1}{n}\sum_{k}min_{i}d(c_{i}, G_{k})
It calculates the minimum distance between each ground truth class and the predicted candidates where the distance function d is defined as:
- d=0 if
c_i=G_k - d=1 otherwise
So, the loss function for this example is :
\begin{aligned}E &=\frac{1}{3}\left ( min_{i}d(c_{i}, G_{1}) +min_{i}d(c_{i}, G_{2})+min_{i}d(c_{i}, G_{3}) \right )\\&=0\end{aligned}
Since, all the categories in ground truth are in the Predicted top-5 matrix, so the loss becomes 0.
VGG Architecture
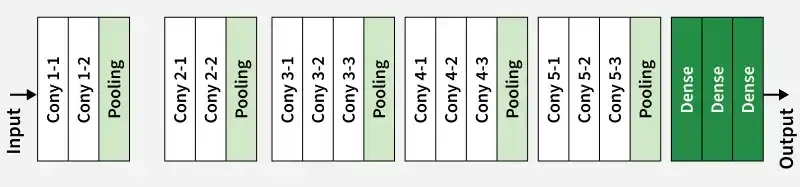
The VGG-16 architecture is a deep convolutional neural network (CNN) designed for image classification, known for its simple and uniform structure. It consists of 16 layers (13 convolutional + 3 fully connected) arranged in blocks, where convolutional layers are followed by max-pooling for downsampling.
- Input Layer: Takes an image of size (224, 224, 3), meaning a colored image
- Conv Blocks: Applies small 3×3 filters in layers to detect simple to complex patterns like edges, textures, and shapes
- Max Pooling: Reduces image size step by step while keeping important features
- Deep Feature Extraction: Repeating convolution layers helps the model learn richer image details
- Flatten Layer: Converts the extracted features into a single long vector
- Fully Connected Layers: Processes this vector to understand the image and prepare final decision
- Output Layer: Uses softmax to give probabilities for 1000 possible classes
VGG-16 for Object Localization
For object localization, instead of predicting only class scores, the model predicts bounding box coordinates. A bounding box is represented by a 4D vector: (x, y, height, width). There are two approaches:
- Shared bounding box: One bounding box is predicted for all classes
- Class-specific bounding box: A separate bounding box is predicted for each class
Since this is a regression task, the loss function is changed from classification loss to regression loss (e.g., MSE), which measures the difference between predicted and actual bounding box values.
Result: VGG-16 performed strongly in the ILSVRC 2014 competition. It achieved a top-5 classification error of 7.32%, finishing second in classification (after GoogLeNet with 6.66%). It also won the localization task with a 25.32% error rate.
Advantages
- Easy to understand and implement due to uniform 3×3 convolution design
- Achieves high accuracy in image classification tasks
- Pre-trained models can be easily reused for other vision tasks
- Deep layers help in learning rich visual features
Limitations
- Slow training due to its deep architecture and large number of parameters
- Large model size (~528 MB), requiring significant storage and bandwidth
- High number of parameters (~138 million), making it computationally expensive
- Prone to training instability in very deep setups compared to newer architectures