LLaMA (Large Language Model Meta AI) is a family of advanced language models developed by Meta (formerly Facebook) that can understand and generate human-like text, making them highly valuable for tasks in natural language processing (NLP), conversational AI, text generation and other AI-driven language applications.
Key Features of LLaMA
- Strong performance in NLP tasks like generation, translation and summarization.
- Transformer-based architecture with self-attention for context understanding.
- Supports fine-tuning across different environments.
- Adaptable for tasks like chatbots and content generation.
- Available in multiple sizes (7B–65B) for different needs.
- Accessible for research and development.
Architecture
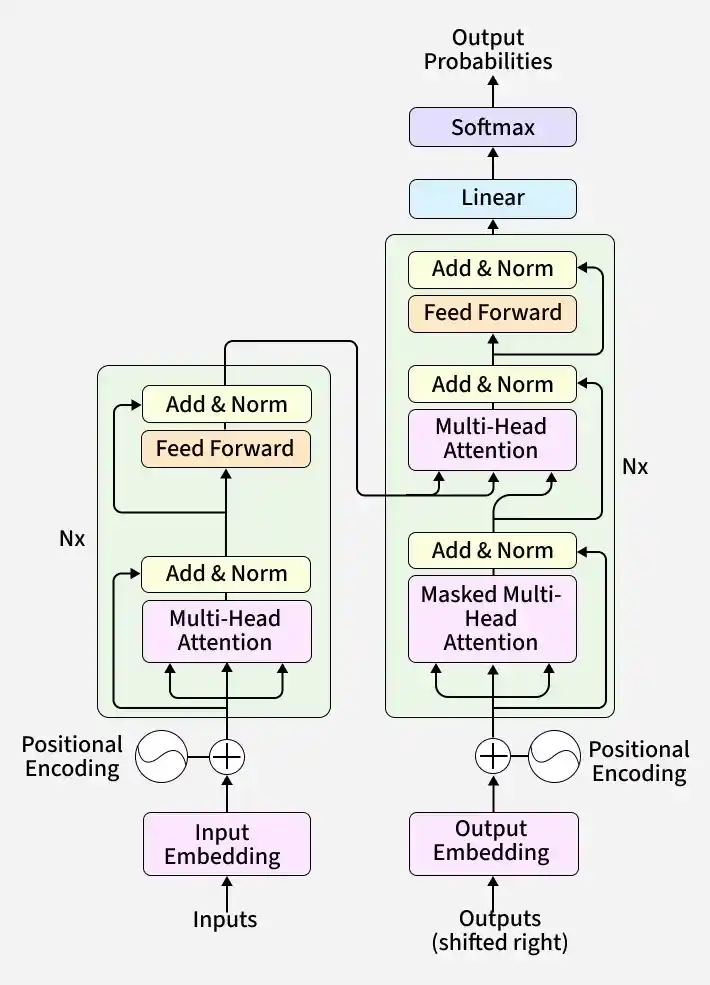
- Transformer-Based: LLaMA uses the Transformer architecture, which processes sequences in parallel and captures long-range dependencies using self-attention mechanisms.
- Stacked Transformer Blocks: The model consists of multiple layers, each including a multi-head self-attention mechanism followed by a feedforward neural network to extract complex patterns in text.
- Multiple Model Sizes: Available in different scales to balance performance and hardware requirements: LLaMA-7B, LLaMA-13B, LLaMA-30B and LLaMA-65B parameters.
- Positional Encoding: Uses positional information to understand the order of words in a sentence, ensuring proper context comprehension.
- Parallel Processing: Self-attention allows the model to analyze all words in a sequence simultaneously, making training and inference more efficient.
- Contextual Understanding: Each layer refines the model’s understanding of text, enabling LLaMA to generate coherent and contextually accurate outputs.
- Rotary Positional Embeddings (RoPE): LLaMA uses RoPE instead of traditional positional encoding, allowing better handling of long sequences by encoding relative positions.
- RMSNorm: Instead of Layer Normalization, LLaMA uses Root Mean Square Normalization (RMSNorm), which improves training stability and efficiency.
Applications
- Conversational AI: Powers chatbots and virtual assistants capable of natural, context-aware conversations, improving customer engagement and support.
- Content Creation: Automates writing for blogs, social media, product descriptions and marketing materials, saving time while maintaining quality.
- Machine Translation: Enables accurate multilingual translation for documents, reports and communications across different languages.
- Sentiment Analysis: Analyzes text to determine sentiment, helping brands monitor customer feedback, social media and product reviews.
- Text Summarization: Condenses long documents or articles into concise summaries, making large volumes of information easier to digest.
Advantages
- High Performance: Achieves state-of-the-art results across NLP tasks like text generation, summarization, translation and sentiment analysis.
- Scalable and Flexible: Can be trained and fine-tuned on a range of hardware setups, from high-end GPUs to accessible computing environments.
- Versatile Applications: Useful for chatbots, content creation, translation, sentiment analysis and more across multiple industries.
- Open-Source Friendly: Meta provides access to models and documentation, promoting research, collaboration and innovation.
- Context-Aware Understanding: Uses Transformer-based architecture with self-attention mechanisms to maintain coherence and context in generated text.
Limitations
- Resource Intensive: Large models require significant computing power and memory for training and inference.
- Potential Bias: Like other language models, LLaMA can reflect biases present in training data, affecting fairness and neutrality.
- Interpretability Challenges: Understanding why the model generates a specific output can be difficult, limiting transparency.
- Ethical Concerns: Misuse in generating fake content, misinformation or spam is possible if not carefully monitored.
- Fine-Tuning Requirements: Domain-specific tasks may require additional fine-tuning to achieve optimal performance.
For a detailed comparison, refer to the ChatGPT vs LLaMA article.