Mamba is a neural network architecture designed for large language models and long-sequence tasks. It overcomes Transformer limitations by providing faster inference, lower memory usage and better scalability all without using attention. Key features of mamba models are
- Uses Selective SSMs (S6) to focus on important past information and handle long-range dependencies.
- Built on State Space Models (SSMs) that track internal states over time to predict system behavior.
- Efficient long-sequence processing with linear scaling.
- Lightweight architecture without Attention or MLP blocks.
- Stable and scalable performance for large models and long contexts.
Mamba = State-Space Models + Selective Input Filtering + Parallel Computation
Why Mamba?
Transformers are highly capable but struggle with long sequences
- Training memory grows quadratically: O(n²)
- Inference memory grows linearly: O(n)
- Attention becomes inefficient for very long contexts
Mamba solves these problems by leveraging Structured State Space Models (SSMs), offering:
- Constant memory inference: O(1)
- Linear training memory: O(n)
- High throughput with GPU optimized parallel scan algorithms
How it Works
Mamba models use selective memory updates and hardware optimized computation, making them faster and more efficient than Transformers. SSMs maintain a hidden state that updates over time using current input and past state to produce the output.
The state transition in a selective SSM is:
\text{state}(t) = A \cdot \text{state}(t-1) + B_t \cdot \text{input}(t)
The output is computed as:
\text{output}(t) = C_t \cdot \text{state}(t) + D_t \cdot \text{input}(t)
where
- A: fixed memory matrix
B_t : Input dependent update matrixC_t : input-dependent output matrixx_t : input token embedding at time t
Mamba uses Selective SSMs (S6) to dynamically focus on important past information (similar to attention but far more memory efficient) and accelerates processing with a GPU optimized parallel scan that enables fast, scalable handling of very long sequences.
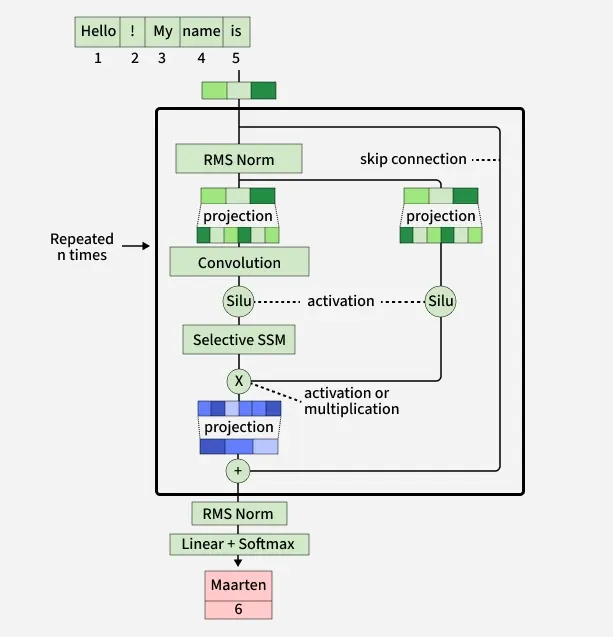
The Mamba Block
The Mamba Block is the core building unit of the Mamba architecture, similar to how the attention block is the core unit in Transformers. It combines the Selective State Space Model (S6) with a gating mechanism to process long sequences efficiently while preserving important context.
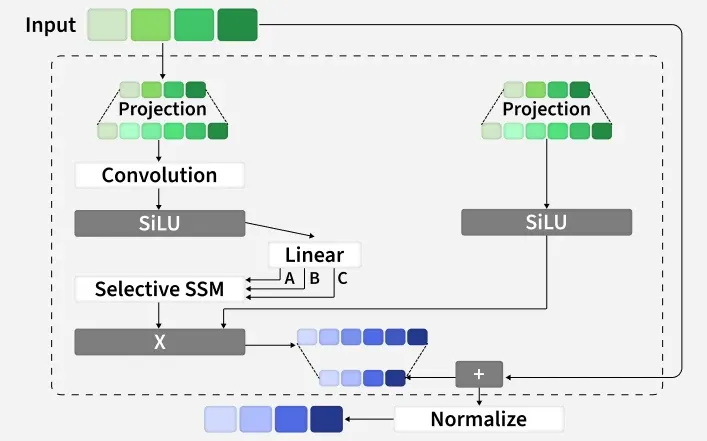
1. Input Projection: The input sequence is first projected into a higher-dimensional space through a linear projection layer.
2. Parallel Processing Paths: The projected input splits into two parallel paths:
SSM Path:
- The projected input passes through a 1D convolution layer.
- A SiLU activation is applied to introduce non linearity.
- A linear layer generates input dependent parameters:
\Delta (step size), B and C. - These parameters are fed into the Selective SSM which updates the hidden state and produces a transformed sequence.
Gating Path:
- The same input projection goes through a SiLU activation.
- This produces a gating signal that determines how much of the SSM output should pass through.
3. Gated Output: The output of the Selective SSM is multiplied element wise with the gate activation to control information flow.
4. Residual Connection: The original input is added back to the gated SSM output, improving gradient flow and model stability.
5. Normalization: A final normalization layer produces the block’s output, ready to be passed to the next Mamba block or output layer.
Mamba-2
The Mamba 2 block is an improved version of the original Mamba block redesigned for higher speed, lower memory use and better parallelism while keeping the same selective state space idea.
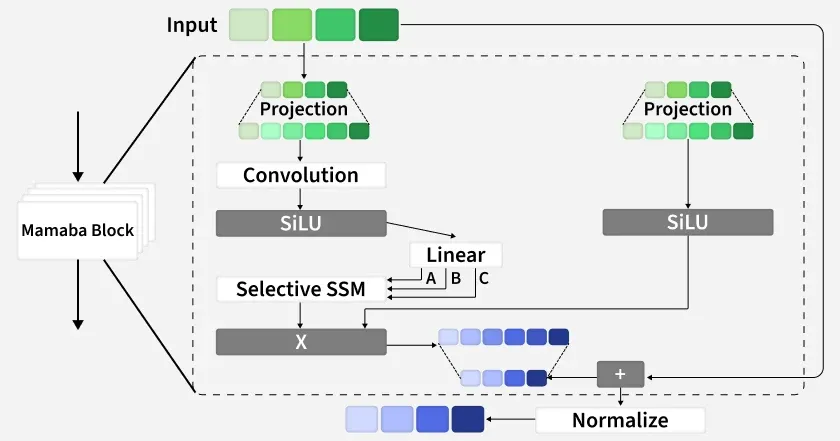
1. Input Projection: The input sequence enters a Mamba-2 block which improves speed and parallelism over the original Mamba design.
2. Dimensionality Expansion: The input is first passed through a projection layer to increase its dimensionality, preparing it for selective state updates.
3. Split into Dual Branches: The projected input splits into two parallel branches:
- Selective SSM branch
- Gating branch
4. Selective SSM Branch
- A 1D convolution captures local patterns from the input.
- A SiLU activation introduces non-linearity.
- A linear layer generates parallel input-dependent parameters
\Delta , B and C. - These parameters feed into the Selective SSM, which updates hidden states efficiently.
- Mamba-2 computes these updates in parallel allowing faster processing than Mamba-1.
5. Gating Branch:
- The input projection goes through a SiLU activation to produce a gating signal.
- This gate decides how much of the SSM output should pass through (similar to attention control).
6. Gated Combination: The SSM output is multiplied with the gate output, allowing selective emphasis on important tokens.
7. Residual Path: A residual connection adds the original input back to the processed output for stability.
8. Normalization Step: A normalization layer prepares the final output, which is then passed to the next Mamba-2 block.
9. Stacking for Deep Models: Multiple Mamba-2 blocks can be stacked to build deep, high-capacity models with lower memory use than transformers.
How to Install and Run Mamba Models
Step 1: Install Required Packages
- Install the core mamba-ssm package used for Mamba and Mamba2 models.
- Install optional causal-conv1d for faster convolution inside the Mamba block.
- Developer dependencies can be installed using the [dev] option.
- Run these commands in terminal before executing the model code.
pip install mamba-ssm
pip install "causal-conv1d>=1.4.0"
pip install "mamba-ssm[causal-conv1d]"
pip install "mamba-ssm[dev]"
Step 2: Import Libraries
- Import PyTorch for tensor creation and GPU usage.
- Import Mamba and Mamba2 from the mamba_ssm package.
- These classes implement selective state space models.
import torch
from mamba_ssm import Mamba, Mamba2
Step 3: Setup Device
- Decide whether to use CUDA or CPU based on availability.
- Using GPU significantly speeds up Mamba inference.
device = "cuda" if torch.cuda.is_available() else "cpu"
Step 4: Create Input Tensor
- Define batch, sequence length and model dimension.
- Create a random tensor with shape (batch, length, dim).
- Move tensor to the selected device.
- This tensor acts as input to both Mamba and Mamba2.
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to(device)
Step 5: Initialize Mamba Model
- Create a Mamba model with required hyperparameters.
- d_model must match the last dimension of input.
- d_state defines memory size (small example uses 16).
- d_conv controls local convolution width.
mamba_model = Mamba(
d_model=dim,
d_state=16,
d_conv=4,
expand=2,
).to(device)
Step 6: Run Forward Pass on Mamba
- Perform a forward pass.
- Output has the same shape as input.
y_mamba = mamba_model(x)
assert y_mamba.shape == x.shape
Step 7: Initialize Mamba2 Model
- Create a Mamba2 model with larger state dimension.
- d_state=64 or 128 is common for real models.
- Other parameters (d_conv, expand) remain similar.
mamba2_model = Mamba2(
d_model=dim,
d_state=64,
d_conv=4,
expand=2,
).to(device)
Step 8: Run Forward Pass on Mamba2
- Perform forward pass similar to Mamba.
- Mamba2 output shape must match input.
y_mamba2 = mamba2_model(x)
assert y_mamba2.shape == x.shape
Mamba LLM
Mamba introduces a Selective SSM layer that redefines how sequence data is processed. This allows the model to:
- Focus on Relevant Information: Mamba assigns varying importance to each input giving more weight to data that influences predictions.
- Dynamically Adapt to Inputs: The model adjusts its behavior based on the input sequence enabling strong performance across diverse sequence modeling tasks.
- Why This Matters: These capabilities allow Mamba to handle very long sequences efficiently making it ideal for tasks requiring long-range memory.
Models Built Using Mamba
Several advanced AI models leverage the Mamba architecture to improve long sequence processing, scalability and efficiency. Some widely known models based on or inspired by Mamba include:
- Mamba-1 and Mamba-2: Original State Space Model based architectures with high efficiency and linear time sequence processing.
- Jamba: A hybrid Transformer and Mamba architecture that combines attention with selective state space processing.
- RWKV-6: An improved recurrent state space framework designed as an alternative to Transformers.
- EVO-1: large scale Mamba based LLM optimized for long context reasoning.
- State Former Models: Architectures that integrate ideas from Transformers and State Space Models.
- AudioMamba and VisionMamba: Domain specific extensions of Mamba for speech/audio and computer vision tasks.
Advantages
- Efficient for long sequences with linear-time processing.
- Faster inference due to removal of attention.
- Lower memory usage supports larger context windows.
- Simple, lightweight architecture using a single SSM block.
- Highly optimized for GPU execution.
Limitations
- New architecture with limited ecosystem support.
- Harder to interpret compared to attention based models.
- Implementation and training are more complex.
- May underperform on tasks requiring explicit token to token interactions.
- Fewer pretrained models available compared to Transformers.
Mamba vs Transformer
Parameter | Transformer | Mamba |
|---|---|---|
Core Mechanism | Uses self-attention to compare every token with every other token | Uses Selective State Space Models (S6) to update a hidden state over time |
Time Complexity | O(n²) due to pairwise attention | O(n) because state updates are linear |
Memory Usage | High memory for long sequences | Very low memory no attention matrix required |
Parallelism | Highly parallel during training but slower in inference | Parallel scan makes training fast and inference faster |
Inductive Bias | Does not assume sequence order uses positional encodings. | Built-in continuous sequence modeling via SSM dynamics |
Use Cases | Great for general LLMs, reasoning, rich interactions. | Great for long context tasks streaming and highspeed LLMs. |