The attention mechanism allows models to focus on the most important parts of input data by assigning different weights to different elements. This helps prioritize relevant information instead of treating everything equally and forms the core of models like Transformers and BERT.
- It improves how models handle long sequences in data.
- It helps capture relationships between distant elements in a sequence.
- Enhances interpretability by showing which parts of input influenced the output.
- Widely applied in translation, summarization, image captioning and speech processing.
Types of Attention Mechanisms
- Soft Attention: Differentiable mechanism using softmax and is widely used in NLP and transformers.
- Hard Attention: A non-differentiable approach that selects specific input parts using sampling, usually trained with reinforcement learning.
- Self-Attention: Enables each input element to attend to other aspects in the same sequence.
- Multi-Head Attention: Uses multiple attention heads to capture diverse features from different representation subspaces.
- Additive Attention: Uses a feed-forward neural network to calculate attention scores instead of dot products.
To know more about the types of attention mechanism, refer to: Types of Attention Mechanism.
Working
The working of attention mechanism can be broken down into several key steps
Step 1: Input Encoding: The input sequence is first encoded using an encoder like RNN, LSTM, GRU or Transformer to generate hidden states representing the input context.
Step 2: Query, Key and Value Vectors: Each input is transformed into:
- Query (Q): Represents what we’re looking for.
- Key (K): Represents what information each input contains.
- Value (V): Contains the actual information of each input.
These are linear transformations of the input embeddings.
Step 3: Similarity Computation: The model computes similarity between the query and each key to determine relevance.
\text{Score}(s,i) = \begin{cases}h_s \cdot y_i & \text{(Dot Product)} \\h_s^T W y_i & \text{(General)} \\v^T \tanh(W[h_s; y_i]) & \text{(Concat)}\end{cases}
Where:
h_s : Encoder hidden state at position sy_i : Decoder hidden state at position iW : Weight matrixv : Weight vector
Step 4: Attention Weights Calculation: The similarity scores are passed through a softmax function to convert them into attention weights:
\alpha(s,i) = \text{softmax}(\text{Score}(s,i))
Step 5: Weighted Sum: The attention weights are used to compute a weighted sum of the value vectors:
c_t = \sum_{i=1}^{T_s} \alpha(s,i) V_i
Here,
Step 6: Context Vector: The context vector
Step 7: Integration: The decoder uses both its own hidden state and the context vector to generate the next output token.
Attention Mechanism Architecture
Attention is a mechanism used within architectures like encoder-decoder models to improve how information is processed. It works alongside components such as the encoder and decoder by helping the model focus on the most relevant parts of the input.
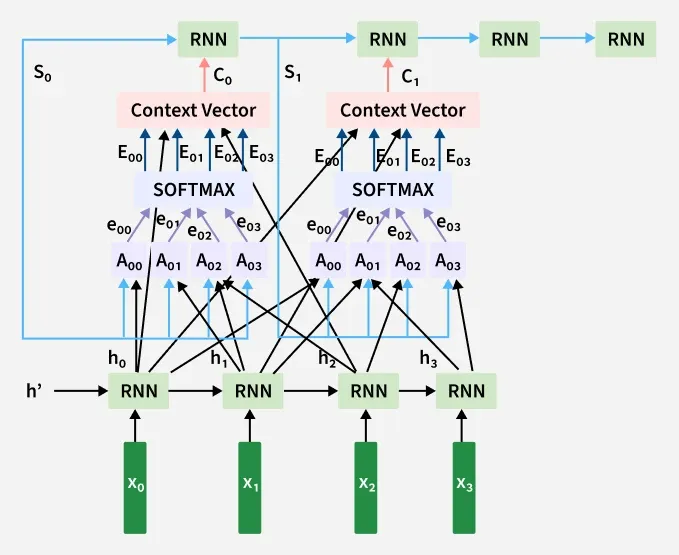
1. Encoder
The Encoder processes the input sequence like a sentence and converts it into a series of hidden states that represent contextual information about each token.
- It typically uses RNNs, LSTMs, GRUs or Transformer-based architectures.
- For a sequence of inputs
x_0, x_1, x_2, x_3 , the encoder generates hidden representations:
h_0, h_1, h_2, h_3
- Each hidden state captures both the current input and information from previous time steps:
h_t =f(h_{t-1},x_t)
- These hidden states are then passed to the attention layer to calculate which parts of the input are most relevant to the current output step.
2. Attention Mechanism
The Attention component determines how much importance should be given to each encoder hidden state when generating a particular word in the output. Its main goal is to create a context vector
Step 1: Feed-Forward Alignment Function: The decoder’s current hidden state
e_{t,i}=g(S_t,h_i )
Here,
S_t : decoder hidden state at time step th_i : encoder hidden state for input token ig : feed-forward network that computes alignment score
Typically, g uses a non-linear activation such as tanh, ReLU or sigmoid.
Step 2: Softmax Normalization: The alignment scores are normalized using a softmax function to produce attention weights
\alpha_{t,i} = \frac{\exp(e_{t,i})}{\sum_{k=1}^{T_s} \exp(e_{t,k})}
Here,
\alpha_{t,i} : attention weight, i.e., how much attention the decoder pays to encoder position i.T_s is the total number of source tokens.
Step 3: Context Vector Generation: Once attention weights are obtained, they are used to compute a weighted sum of encoder hidden states, forming the context vector
C_t = \sum_{i=1}^{T_s} \alpha_{t,i} \, h_i
Here,
C_t : context vector summarizing encoder outputs\alpha_{t,i} : attention weightsh_i : encoder hidden states
This vector represents the most relevant information from the input sentence needed to predict the next output word.
3. Decoder
The Decoder uses both the context vector
At each decoding step:
- The decoder receives
C_t and the previous predicted word. - It produces a new hidden state
S_{t+1} and predicts the next token. - This process repeats for each word in the target sequence.
Mathematically:
y_t =\text{Decoder}(y_{t-1},S_t,C_t)
Here,
y_{t-1} : previously generated tokenS_t : decoder hidden stateC_t : context vector
This combination enables the model to generate contextually accurate translations hence focusing on the most relevant parts of the source sequence for each predicted word.
Improvement Using Attention Mechanism
Traditional deep learning models like RNNs, LSTMs and CNNs have limitations when handling long or complex dependencies. The attention mechanism enhances their effectiveness as follows:
- RNNs/LSTMs: These models compress the entire input into one vector, causing information loss over long sequences. Attention dynamically focuses on the relevant parts, resolving long-term dependency issues.
- CNNs: They have fixed receptive fields and attention enables global dependencies, helping capture relationships beyond local patterns.
- Seq2Seq Models: Replace single context vectors with multiple dynamic ones, improving translation accuracy.
- General Advantage: Helps assign different importance weights to inputs, avoiding equal treatment of all tokens or features.
- Transformers: Attention is the core mechanism in Transformers through self-attention, this removes sequential processing limitations of RNNs which improves efficiency and scalability.
Implementation
Let's see the python implementation of Attention Mechanism
Step 1: Define the Attention Class
- self.attn: transforms combined decoder hidden state and encoder outputs into an intermediate energy vector
- self.v: converts the energy vector into a single score for each time step
- hidden.unsqueeze().repeat(): aligns decoder hidden state with all encoder time steps
- torch.bmm(v, energy): computes attention scores
- softmax: converts scores into attention weights (probabilities)
- torch.bmm(...): generates the context vector as a weighted sum of encoder outputs
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, hidden_dim):
super(Attention, self).__init__()
self.attn = nn.Linear(hidden_dim * 2, hidden_dim)
self.v = nn.Parameter(torch.rand(hidden_dim))
def forward(self, hidden, encoder_outputs):
batch_size = encoder_outputs.shape[0]
seq_len = encoder_outputs.shape[1]
hidden = hidden.unsqueeze(1).repeat(1, seq_len, 1)
energy = torch.tanh(
self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
energy = energy.permute(0, 2, 1)
v = self.v.repeat(batch_size, 1).unsqueeze(1)
attention_scores = torch.bmm(v, energy).squeeze(1)
attention_weights = F.softmax(attention_scores, dim=1)
context = torch.bmm(attention_weights.unsqueeze(1), encoder_outputs)
return context, attention_weights
Step 2: Create Sample Input
- torch.manual_seed(0): makes the random tensors deterministic so outputs are repeatable.
- encoder_outputs: stands in for the sequence of encoder hidden states.
- decoder_hidden: the current decoder hidden state used as the Query to compute attention.
torch.manual_seed(0)
batch_size = 1
seq_len = 4
hidden_dim = 8
encoder_outputs = torch.randn(batch_size, seq_len, hidden_dim)
decoder_hidden = torch.randn(batch_size, hidden_dim)
Step 3: Initialize and Run Attention
1. Attention(hidden_dim): constructs the attention module with the chosen hidden dimension.
2. Calling the module returns:
- context: the context vector of shape [batch, 1, hidden_dim].
- attn_weights: the attention distribution over the seq_len encoder steps (shape [batch, seq_len]).
attention = Attention(hidden_dim)
context, attn_weights = attention(decoder_hidden, encoder_outputs)
Step 4: Inspect Result
- Inspecting attn_weights shows which encoder positions the module focused on (values sum to 1 across the sequence).
- context is the weighted sum of encoder outputs which we will pass into the decoder to inform the next prediction.
print("Encoder Outputs:\n", encoder_outputs)
print("\nDecoder Hidden State:\n", decoder_hidden)
print("\nAttention Weights:\n", attn_weights)
print("\nContext Vector:\n", context)
Output:

You can download source code from here.
Applications
- Machine Translation: Focuses on relevant words while generating each output word.
- Text Summarization: Selects key information for concise summaries.
- Image Captioning: Attends to specific image regions to describe them accurately.
- Sentiment Analysis and NER: Highlights important words or entities in text.
- Speech Recognition: Focuses on critical audio frames for better transcription.
Advantages
- Helps models focus dynamically on the most relevant information.
- Solves long-term dependency issues in sequential data.
- Improves performance and interpretability in NLP and Vision tasks.
- Enables parallel computation (in self-attention) unlike RNNs.
- Enhances context understanding in transformer-based models.
Limitations
- Computationally expensive for long sequences (especially self-attention).
- Requires large memory due to quadratic complexity.
- Attention weights can be difficult to interpret in large models.
- Needs large datasets for effective training.