LLMs (Large Language models) as a judge is an evaluation method that is used to judge the outputs of other models based on predefined criteria or metrics specific to the task. For example, if we ask a model to summarize a piece of text, another LLM can be used to judge that summary. It can check whether the summary is relevant to the original text, factually correct, easy to read and well written. Based on these points, the LLM gives feedback or a score.
When & Why to use LLM as judges
- AI judges are fast, cheaper and in some cases more reliable than human reviewers, also AI judges can output scores based on your custom criteria . Note that just like human reviewers , AI as a judge also has its own limitations.
- Before 2020 (when GPT-3 came) , evaluation of two pieces of texts was done by using metrics like BLEU and ROGUE score , these metrics were great for measuring syntactic and lexical similarity , but struggled with semantic similarity between texts, to overcome this issue LLM as a judge was proposed.
- LLM as a judge should be used for tasks where either human annotation of dataset is expensive / time-consuming or we need to overcome biases when judging , as a large language model is trained on public data , it is implicitly assumed that it is an aggregation of the masses , hence biases are reduced.
- When we need to evaluate huge amount of data , LLM as a judge shines the most.
Types of judges
- No-reference evaluation: Evaluates the quality of the response only based on predefined metrics without any reference response.
# pip install deepeval
from deepeval import evaluate
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
- Reference evaluation : Evaluates the quality of the response with a reference response treating it as a "gold standard"
reference_prompt = """Given a question , answer and a reference response, output a score out of 5 on how close the
generated response is to the reference response
Question : {question}
Answer : {answer}
Reference Response : {reference_resp}
Score : {score}
"""
- Preference-alignment or comparison evaluation : This is the most advanced technique used by many model providers like openAI, Claude . In this the model / humans are used to rate which output out of two is better. preference alignment is linked to theory of associativity.
For example: If we have 3 responses A, B, C and we have data that S(A) > S(B) & S(B) > S(C) , then we assume that S(A) > S(C).
example_prompt = """Given one question and 2 candidate answers , evaluate which one is better , output only the response tag
Question : {question}
Answer1(GPT4.1) : {answer}
Answer2(GPT 3.5) : {answer_2}
Better answer Model_tag is:
"""
Designing a prompt for LLM as a judge
General instructions on how to design a prompt with best practices , but an evaluation prompt should also follow the below given criteria(s).
1. The task to be solved by the model should be explicitly written, along with the criteria and metrics, such as to compare relevance between a generated answer and a reference response.
2. The scoring system which can be any of these
- Classification : Such as good/bad/average/irrelevant e.t.c.
- Numerical(Regression-like) : Such as outputting values between 0 and 1 , including fractions.
- Discrete : Outputting values between 1 to 5, for example ratings/feedback.
Generally LLMs work better with discrete scoring systems.
Working & Methods of LLM as a judge
G-Eval
G-Eval is a recently developed and widely used framework from a research paper titled “NLG Evaluation using GPT-4 with Better Human Alignment” that uses LLMs to evaluate LLM outputs and is one the best ways to create task-specific metrics.
In G-eval we first input task introduction and evaluation criteria to the LLM and ask it to generate a COT of detailed evaluation steps. Then we use the prompt along with the generated COT to evaluate the LLM output , finally we use the probability-weighted summation of the output scores as the final score.
Implementation of G-Eval
Step 1 : Import Required Libraries
# pip install deepeval
from deepeval import evaluate
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
Step 2 : Define Context (Ground Truth & Input Target) + User Query
MATCH_CONTEXT = """
India vs Australia, 3rd ODI, Mumbai, January 15, 2025
Virat Kohli scored 112 runs off 105 balls with 12 fours and 2 sixes.
He was dismissed in the 48th over, caught at long-off by Maxwell
off Starc's bowling. Kohli's innings helped India post 345/7 in
50 overs. This was his 47th ODI century. He reached his 50 in
52 balls and converted it to a century in just 53 more deliveries.
"""
AI_GENERATED_REPORT = """
Virat Kohli produced a masterclass innings of 112 runs off 105 balls,
hitting 12 boundaries and 2 maximums. His knock was the cornerstone
of India's imposing total of 345 runs. Kohli notched up his half-century
in 52 deliveries before accelerating brilliantly. He was eventually
dismissed in the 48th over, caught by Glenn Maxwell off Mitchell Starc.
This century was Kohli's 47th in ODI cricket, further cementing his
legacy as one of the format's greatest batsmen.
"""
USER_QUERY = "Describe Virat Kohli's performance in the match"
Step 3 : Define evaluation Criteria
In the original paper the evaluation criteria was obtained using Auto-chain-of-thought prompting, but in deep-eval we manually define the evaluation guidelines or criteria.
factual_accuracy = GEval(
name="Factual Accuracy",
model="gpt-4o",
criteria="Verify all statistics and facts match the context exactly",
evaluation_steps=[
"Check runs, balls, fours, sixes match context",
"Verify dismissal details are correct",
"Confirm century number is accurate",
"Identify any incorrect facts"
],
evaluation_params=[
LLMTestCaseParams.ACTUAL_OUTPUT,
LLMTestCaseParams.CONTEXT
]
)
groundedness = GEval(
name="Groundedness",
model="gpt-4o",
criteria="Check if every claim is supported by context",
evaluation_steps=[
"Extract all claims from actual output",
"Find evidence for each claim in context",
"Flag any unsupported or hallucinated claims",
"Score based on percentage of grounded claims"
],
evaluation_params=[
LLMTestCaseParams.ACTUAL_OUTPUT,
LLMTestCaseParams.CONTEXT
]
)
Step 4 : Evaluate results
Now we run the LLM on concatenation of input-context, input-target, expected-output, this is handled automatically by deep-eval , so we don't need to do it manually.
test_case = LLMTestCase(
input=USER_QUERY,
actual_output=AI_GENERATED_REPORT,
context=[MATCH_CONTEXT]
)
factual_accuracy.measure(test_case)
print(f"Factual Accuracy: {factual_accuracy.score:.2f}/5.0")
print(f"Reason: {factual_accuracy.reason}\n")
groundedness.measure(test_case)
print(f"Groundedness: {groundedness.score:.2f}/5.0")
print(f"Reason: {groundedness.reason}\n")
results = evaluate(
test_cases=[test_case],
metrics=[factual_accuracy, groundedness]
)
DAG(Direct Acyclic Graph)
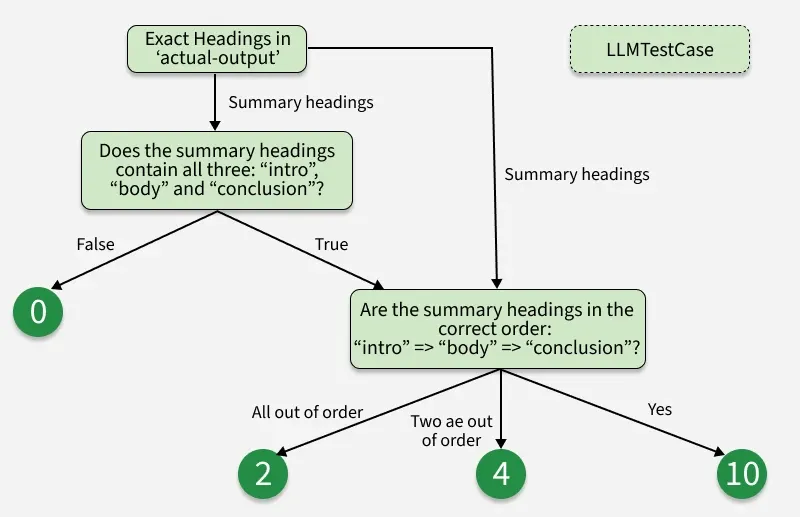
DAG is deterministic in nature compared to G-eval, when we need hierarchical deterministic evaluation DAG is the best choice, but it increases both cost and latency in the evaluating application. In DAG, each node represents an LLM judge handling a specific decision, while edges define the logical flow between decisions. By breaking down an LLM interaction into finer, atomic units, you reduce ambiguity and enforce alignment with your expectations.
Preference Evaluation
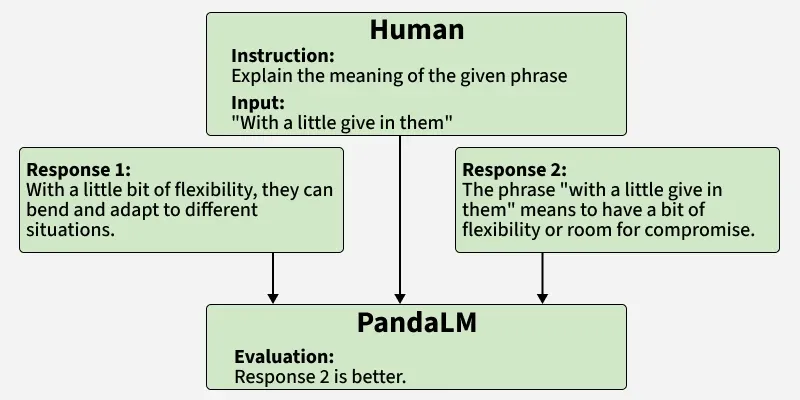
Preference evaluation measures how well a system’s outputs align with human judgment, rather than strict correctness alone. The focus is on perceived quality aspects such as usefulness, clarity and overall acceptability. It is commonly conducted through human comparisons or rankings of multiple outputs. These preference signals are then used for model evaluation or incorporated into training pipelines to better align systems with human expectations.
Limitations of AI as a judge
Although LLM as a judge has revolutionized evaluation, they are far from perfect and it is important to understand the limitations of this technology before using them in production or otherwise.
- Inconsistency : LLMs are non-deterministic and probabilistic models , i.e. same model run on same input two different times would most likely produce two different outputs, this inconsistency makes it hard to reproduce or trust evaluation results.
- Tool variety & Criteria Ambiguity : There is no one standard tool or API for model evaluation , different tools like MLflow, Ragas or llama index rely on different prompts and methods to evaluate a criteria, causing confusion if not managed carefully.
- Increased cost & Latency : Implementing AI as a judge adds latency on the application, hindering the overall user experience if latency is too high, using small models as judges can mitigate this issue to a extent but not eliminate it.
- Biases : LLMs tend to have certain biases like self-bias(a judge model prefers a response generated by itself more) & first-position bias(where models tend to prefer the option they encounter first)
Improving LLM as a judge outputs
Below given techniques can help improve a LLM's outputs , most are available built-in inside frameworks like deepeval.
- COT prompting : Chain-of-Thought prompting is a technique in which a language model is encouraged to generate intermediate reasoning steps before producing a final answer.
- Few shot prompting : Few-shot prompting is a prompting technique in which a language model is provided with a small number of input–output examples within the prompt to demonstrate the desired task behavior. The model learns the pattern from these examples and applies it to a new, unseen input.
- Using Probability of output tokens : The method is used to make scores continuous instead of discrete and to deal with biases, in this the normalized score of the probability of tokens occuring is taken and then divided by the max_score.