Self-attention helps a model understand how words in a sentence are related to each other. It allows the model to look at all words at the same time and decide which ones are important for understanding the meaning of each word. Because of this, self-attention captures context more effectively and plays a key role in models like Transformers.
- Attention helps models focus on the most important words in a sentence, similar to how humans understand language.
- Traditional RNN encoder–decoder models compress input into a single vector, which can lose important information.
- It handles long-range dependencies more effectively than traditional sequential models.
Attention is a mechanism that helps a model focus on the most relevant parts of the input when processing information. It assigns importance to different elements so the model can better understand context and meaning.
Problem with Traditional Models
Traditional sequence models like encoder–decoder architectures were widely used for tasks such as translation and text generation, but they face important limitations when handling complex and long sentences.
Encoder–Decoder Model
The encoder–decoder model model is used for tasks where one sequence needs to be converted into another, such as translating a sentence from one language to another. It works by first understanding the input and then generating the corresponding output based on that understanding.
- Encoder: It takes the input sequence and processes it step by step, converting it into a fixed-size vector called a context vector that summarizes the entire input.
- Decoder: It uses this context vector to generate the output sequence by predicting one word at a time based on the encoded information.

The encoder–decoder architecture has several limitations that affect its ability to effectively handle long and complex sequences.
- The entire input is compressed into a single fixed-length vector, which can lead to loss of important information.
- Performance degrades for long sequences because the model struggles to retain all relevant details.
- It is difficult to capture long-range dependencies between words that are far apart in a sentence.
- Sequential processing makes training slow and limits parallel computation.
Understanding Self-Attention Mechanism
It processes all words at once and identifies which ones are important for capturing context and meaning. Self-attention can be represented mathematically using queries, keys, and values to compute relationships between words.
Attention\left ( Q, K, V \right ) = softmax\left ( \frac{QK^{T}}{\sqrt{d_{k}}} \right )V
where
- Q,K and V are matrices of query, key, and value vectors
- dk is the dimension of the key vectors
Self-attention enables each word to dynamically focus on different parts of the sentence, creating a rich and context-aware representation of the entire sequence.
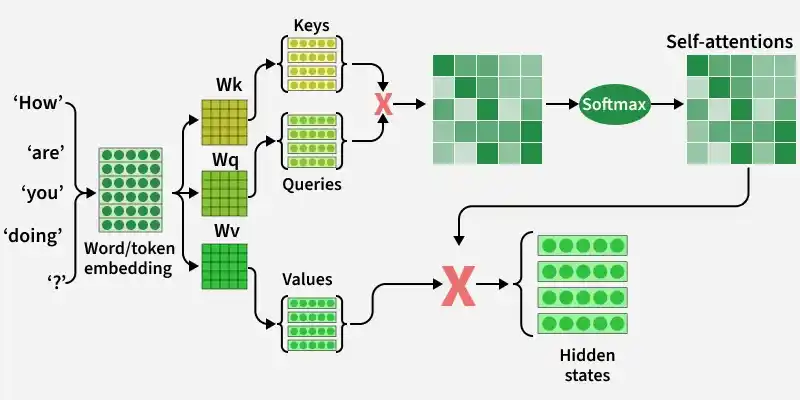
The self-attention mechanism transforms the input into three vectors: Query (Q), Key (K) and Value (V) using learned weight matrices.
- Linear Transformation: Each input word is converted into Query, Key and Value vectors using weight matrices W(Q), W(K), W(V).
- Query-Key Interaction: The query vector of a word is multiplied with the key vectors of all words to compute attention scores, indicating how much focus to give to each word.
- Scaling: The scores are scaled by dividing by
\sqrt{d_{k}} to prevent very large values and ensure stable training. - Softmax Normalization: The scaled scores are passed through a softmax function to convert them into probabilities.
- Weighted Sum of Values: These probabilities are multiplied with the value vectors to assign importance to each word.
- Final Output: All weighted value vectors are summed to produce the final representation for each word.
Understanding Multi-Head Self-Attention
Multi-head self-attention extends the self-attention mechanism by using multiple attention heads in parallel. Instead of relying on a single attention calculation, it allows the model to focus on different parts of the input sequence at the same time, capturing a wider range of relationships between words.
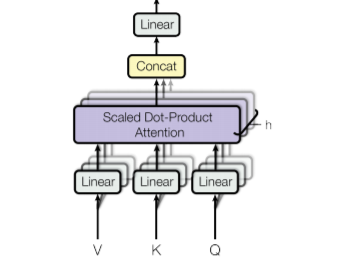
Mathematical Multi-head self-attention Representation as:
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \dots, \text{head}_h) W^{O}
Where each head is computed as:
\text{head}_i = \text{Attention}(Q W_i^Q, \; K W_i^K, \; V W_i^V)
Multi-head attention works by applying multiple attention operations in parallel to capture different relationships in the input sequence.
- Input Embeddings: Each word in the sentence is converted into an embedding vector.
- Multiple Attention Heads: The model creates multiple heads each with its own weight matrices WQ, WK, WV.
- Linear Projections: For each head, the input embeddings are transformed into Query (Q), Key (K), and Value (V) vectors.
- Apply Self-Attention: Each head independently applies the self-attention mechanism to compute contextual representations.
- Concatenation: Outputs from all attention heads are concatenated into a single matrix.
- Final Linear Transformation: The concatenated output is multiplied by a weight matrix WO to produce the final output.
Attention Layer in Transformer
The attention layer is the core component of the Transformer architecture. It allows the model to understand relationships between words in a sequence by focusing on relevant parts of the input and building context-aware representations.
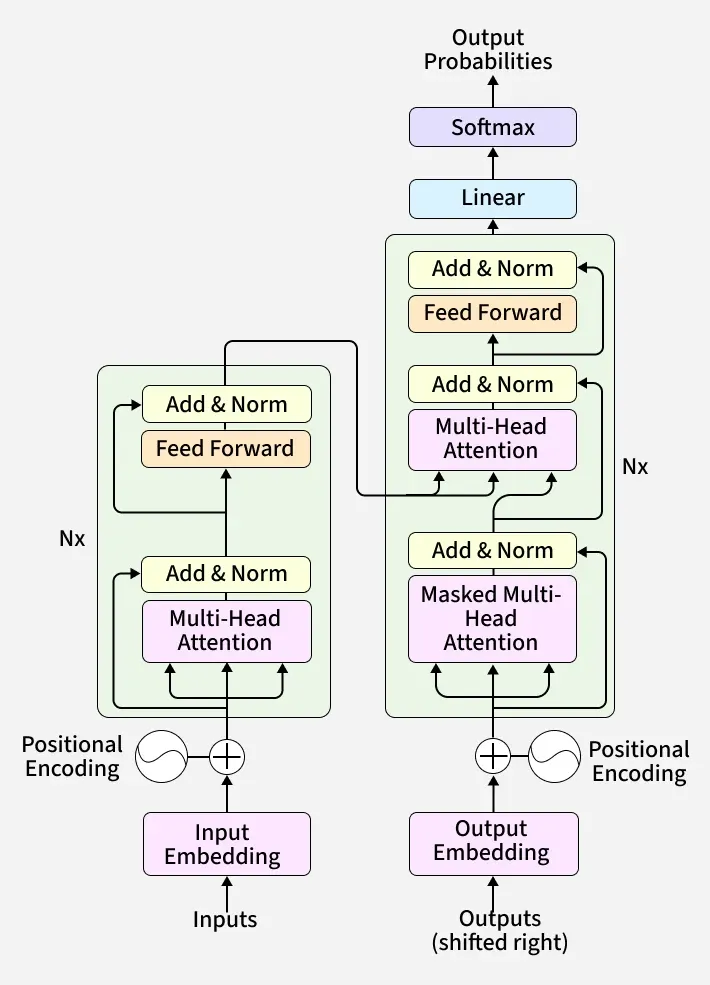
1. Multi-Head Attention in Encoder
In the encoder, multi-head attention is used to understand the full context of the input sentence by allowing each word to attend to all other words.
- Each word is converted into Query (Q), Key (K) and Value (V) vectors from the same input.
- Attention is computed across all words to capture relationships and context.
- Multiple heads run in parallel to learn different types of relationships.
2. Masked Multi-Head Attention in Decoder
In the decoder, masked multi-head attention ensures that the model generates output step by step without accessing future words.
- Queries, keys and values come from the decoder input sequence.
- A mask is applied so each position can only attend to current and previous words.
- This prevents information leakage from future tokens during training.
3. Multi-Head Attention in Decoder (Encoder–Decoder Attention)
This layer helps the decoder focus on relevant parts of the input sequence while generating output.
- Queries come from the decoder, while keys and values come from the encoder output.
- The decoder attends to all positions in the input sequence.
- This helps in aligning input and output sequences effectively.
Refer Article: Architecture and Working of Transformers in Deep Learning
Implementation
Here we can be implement Self-attention in Python using matrix operations. It computes relationships between all words in a sequence and generates context-aware representations.
- The input is a batch of sequences represented as embeddings (shape: batch_size × sequence_length × embedding_dim).
- Weight Matrices (Wq, Wk, Wv) transform the input embeddings into Query (Q), Key (K), and Value (V) vectors for computing attention.
- Compute Q, K, V by multiply the input embeddings with the respective weight matrices to obtain Q, K, and V.
- Calculate attention scores by taking the dot product between Q and KT then scale it by the square root of the key dimension(
\sqrt{d_{k}} ). - Apply softmax to the scores to get attention weights (probabilities).
- Multiply the attention weights with V to get the final output for each word in the sequence.
import numpy as np
def self_attention(X):
batch_size, seq_len, d_model = X.shape
d_k = d_model
W_q = np.random.randn(d_model, d_k)
W_k = np.random.randn(d_model, d_k)
W_v = np.random.randn(d_model, d_k)
Q = X @ W_q
K = X @ W_k
V = X @ W_v
scores = Q @ K.transpose(0, 2, 1) / np.sqrt(d_k)
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
output = attention_weights @ V
return output, attention_weights
np.random.seed(42)
X = np.random.rand(1, 3, 4)
output, weights = self_attention(X)
print("Output:\n", output)
print("\nAttention Weights:\n", weights)
Output
Output: [[[-1.00006959 -0.08691166 0.66098659 1.15282625] [-0.94070605 -0.15072265 0.6716722 1.07836487] [-0.94622694 -0.07915902 0.67950479 1.09794086]]] Attention Weights: [[[0.1910979...
Advantages
- Unlike sequential models, it allows full parallel processing, which speeds up training.
- Provides direct access to distant elements, making it easier to capture long-range dependencies.
- Each token’s representation is influenced by the entire sequence, integrating global context and improving accuracy.
- Attention maps can be visualized to see which parts of the input were most influential, making the model more interpretable.
- Scales well with longer sequences compared to RNNs, reducing the risk of vanishing gradients.
- Improves performance on diverse NLP tasks such as translation, summarization, and text generation.
Limitations
- Self-attention requires computing pairwise interactions between all input tokens, resulting in time and memory complexity of O(n2) which can be inefficient for long sequences.
- The large number of pairwise calculations consumes significant memory, especially for long sequences or large batch sizes.
- While it captures global dependencies effectively, it may struggle to capture local patterns, making it less efficient when local context is more important.
- Its ability to model complex relationships can lead to overfitting when trained on small datasets.
- High computational requirements make it challenging to deploy in resource-constrained environments.
- Training very deep models with self-attention can sometimes cause instability in optimization, requiring careful tuning of learning rates and regularization.