Reinforcement Learning (RL) agents learn optimal behaviors by maximizing cumulative rewards through experience. The way agents acquire and use data divides RL into two major paradigms: online and offline reinforcement learning.
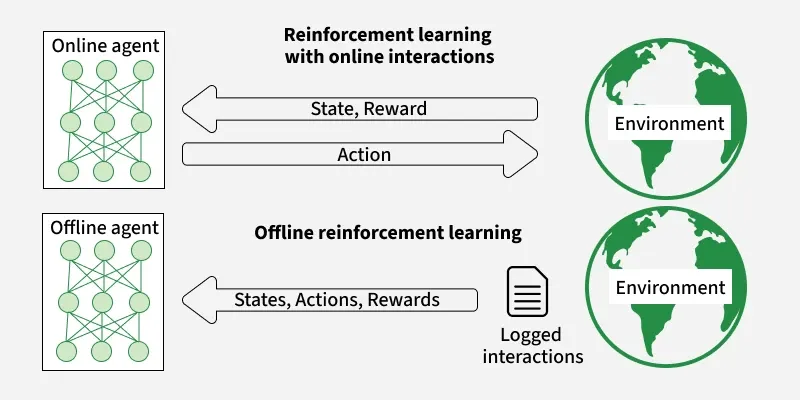
Online Reinforcement Learning
- Definition: In online RL, the agent actively interacts with the environment to collect new data as it learns. The agent updates its policy in real-time or after each episode, using the most recent experiences
- Data Collection: Data is generated live by the agent’s own actions and observations during training.
- Adaptivity: The agent can dynamically adapt to changes in the environment since it continually gathers fresh data.
Offline Reinforcement Learning
- Definition: In offline RL (also known as batch RL or fixed dataset policy optimization), the agent learns solely from a static, pre-collected dataset of experiences. It does not interact with the environment during training.
- Data Source: The dataset may come from previous agents, human demonstrations, or logs of past interactions.
- Learning Process: The agent optimizes its policy based on the distribution of states and actions in the dataset. No new data is collected during learning.
Hybrid Approaches
Online and offline RL are not mutually exclusive. Many modern systems combine both: starting with offline RL using historical data, then fine-tuning online to adapt to new situations or improve performance.
Advantages
- Safe: No risk of unsafe exploration, making it ideal for domains like healthcare or autonomous driving where live trial-and-error is impractical or dangerous.
- Flexible: Training can be done without real-time access to the environment, and resources can be allocated flexibly.
- Suitable for simulations or environments where live exploration is safe and feasible, such as robotics in controlled settings or online games.
Challenges
- Distribution Shift: The agent may encounter situations during deployment that are not well-represented in the dataset, leading to poor performance.
- Counterfactual Queries: The agent cannot reliably estimate outcomes for actions not present in the data, limiting exploration and generalization.
- Resource Requirements: Online RL often requires significant computational resources and, for real-world tasks, close integration with the environment for safe and efficient data collection.