A distributed cache stores data across multiple servers (nodes) instead of a single machine, allowing faster access and better scalability. It helps improve application performance by reducing the need to repeatedly fetch data from the database.
- Data is distributed across multiple nodes, each using its own memory for fast access.
- It scales easily and remains available even if some nodes fail.
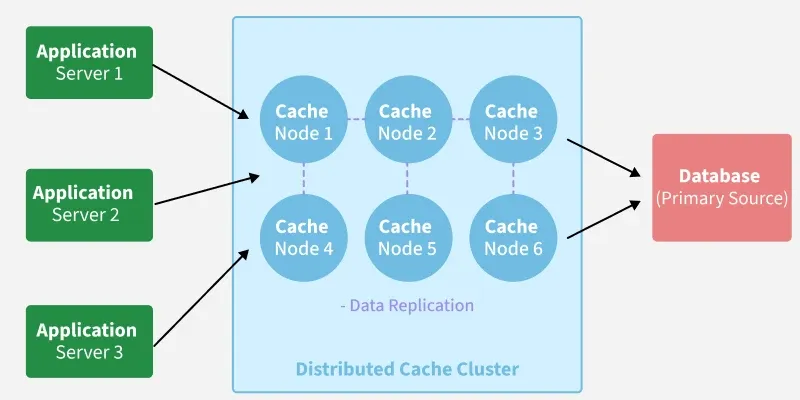
Working
This explains how a Distributed Cache typically works:
1. Data Storage: Each cache node uses RAM to store cached data, enabling fast reads and writes compared to disk-based storage.
2. Data Replication: Cached entries are duplicated across multiple nodes to ensure high availability and fault tolerance.
3. Cache Eviction: Automatically removes less valuable entries when memory limits are reached.
- LRU (Least Recently Used): Removes the data that has not been accessed for the longest time, assuming it is less likely to be used again.
- LFU (Least Frequently Used): Removes the data that is accessed the least number of times, keeping frequently used data in cache.
- TTL (Time To Live): Automatically deletes data after a fixed time duration to ensure outdated data is removed.
- FIFO (First In First Out): Removes the oldest data in the cache first, regardless of how often it is used.
4. Cache Invalidation: Expire or remove entries when underlying data changes to prevent stale reads.
5. Cache Coherency: Keeps all nodes’ copies synchronized so updates are reflected cluster-wide.
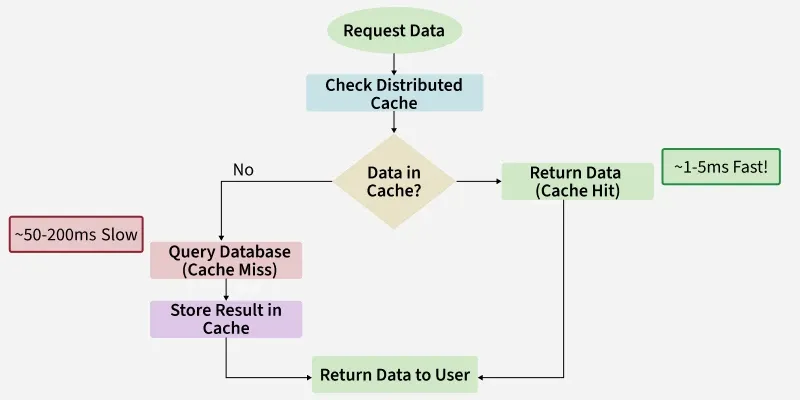
6. Cache Access: Applications use a simple API (GET/SET/DELETE) to retrieve or update data in the nearest cache node, minimizing latency.
Components
The key components of distributed Caching include:
- Cache Servers or Nodes: Cache servers are the primary components in a distributed caching system. They store temporary data across multiple machines or nodes, ensuring that the data is available close to where it’s needed.
- Cache Data: This is the actual data stored in the distributed cache system. It can include frequently accessed objects, database query results, or any other data that benefits from being stored in memory for fast access.
- Cache Client: Cache clients are used by applications to communicate with the distributed cache system. They offer an interface for saving, retrieving, and modifying cached data. The cache client makes it simpler for developers to include caching into their applications by abstracting away the complexities of cache management and communication with cache nodes.
- Cache API: The cache API provides a way for applications to interact with the cache system, allowing them to store, retrieve, update, and remove data.
- Cache Manager: The cache manager is responsible for coordinating cache operations and managing the overall behaviour of the distributed cache system.
Benefits
These are some of the core benefits of using a distributed cache methodology:
- Maintains frequently accessed data in memory, improving user experience and application speed of response.
- It is appropriate for applications needing high throughput since it can accommodate large data requests and add more nodes to the cluster, allowing applications to scale horizontally without affecting performance.
- Can replicate data across multiple nodes, ensuring that data is always available even if one or more nodes fail.
- Reduces the need for expensive hardware upgrades or additional database licenses, making it a cost-effective solution for scaling applications.
- Can store user session data, improving the performance and scalability of web applications.
Use Cases
There are many use cases for which an application developer may include a distributed cache as part of their architecture. These include:
- Application Performance Acceleration: Store frequently accessed data in memory to reduce database I/O bottlenecks and improve response times from hundreds of milliseconds to just a few milliseconds.
- Web Session Data Management: Enable user session data like shopping carts and preferences to be accessible across multiple application servers, ensuring seamless user experience regardless of which server handles the request.
- Network Traffic Optimisation: Cache data at multiple locations to reduce bandwidth consumption and data transfer costs, especially valuable in cloud environments with usage-based pricing.
- High Availability During Outages: Continue serving read requests even when primary databases become unavailable, ensuring critical application functions remain operational during database failures or maintenance.
- Geographic Data Distribution: Deploy cache clusters across different regions to serve global users with minimal latency, ensuring consistent performance worldwide.
Steps for Implementation
From selecting the best caching solution to customizing and implementing it in a distributed setting, there are multiple processes involved in setting up a distributed cache. The general step-by-step instructions are provided below:
- Step 1: Select a suitable distributed caching solution based on application requirements and infrastructure.
- Step 2: Install and configure the caching software on each node or server in the distributed system.
- Step 3: Define data partitioning and replication strategies to ensure efficient data distribution and high availability.
- Step 4: Integrate the caching solution with the application, ensuring that data reads and writes are directed to the cache.
- Step 5: Monitor and fine-tune the cache performance, adjusting configurations as needed for optimal results.
Distributed Caching solutions
Some of the popular distributed caching solutions are:
- Redis: A highly popular in-memory data store, Redis supports caching, databases, and message brokering. It’s known for speed and flexibility, and works well for distributed caching with built-in data replication and persistence options.
- Memcached: A lightweight, in-memory key-value store. Memcached is widely used for caching frequently accessed data and is easy to set up, though it lacks some advanced features like persistence and replication.
- Amazon ElastiCache: A fully managed service by AWS, it supports both Redis and Memcached, allowing you to use caching in a distributed cloud environment without managing the infrastructure yourself.
- Apache Ignite: An in-memory computing platform that offers distributed caching with advanced features like transactions and real-time streaming. It’s designed for high-performance computing scenarios.
- Hazelcast: A scalable in-memory data grid that provides distributed caching, data partitioning, and failover features. It’s often used in highly scalable enterprise applications.
Challenges
Some of the challenges with distributed caching are:
- Data Consistency: Keeping cache data in sync across multiple servers is hard. If one cache is updated but others aren’t, you get out of date or conflicting data.
- Cache Invalidation: Deciding when to remove or update cache is hard. If data stays in cache too long users get out of date info.
- Scalability: As you grow the system managing and coordinating cache across many servers gets harder and slows things down.
- Network Latency: Getting data from a distributed cache across multiple locations can introduce latency especially if servers are far apart.
- Fault Tolerance: If one cache server goes down the system needs to handle it without impacting performance or data availability. Balancing this across many servers is hard.