System design interviews evaluate your ability to design scalable and complex systems, focusing more on architecture and decision-making than coding. They are challenging due to their open-ended nature and lack of a single correct solution.
- Focuses on structuring systems, designing components, and explaining trade-offs clearly.
- Requires strong fundamentals to handle scalability, reliability, and real-world system challenges effectively.
If you’re preparing for this round, first focus on understanding core system design fundamentals. This will help you build a strong foundation before solving system design problems.
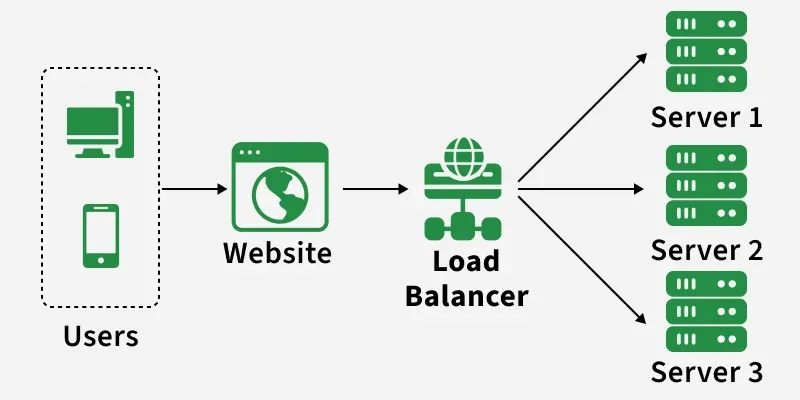
1. Load Balancing
A load balancer is a component that distributes incoming user requests across multiple servers to ensure no single server gets overloaded. When traffic exceeds a server’s capacity, performance drops or the system may fail, so load balancing helps maintain availability and efficiency. It acts as a traffic manager, improving throughput, reducing latency, and enabling scalability.
- Distributes incoming requests across multiple servers to enable horizontal scaling and prevent overload.
- Improves system availability and performance by reducing response time and balancing traffic efficiently.
Example: When you open Netflix, millions of users send requests at the same time. A load balancer distributes these requests across multiple servers so that video streaming remains smooth without crashes.
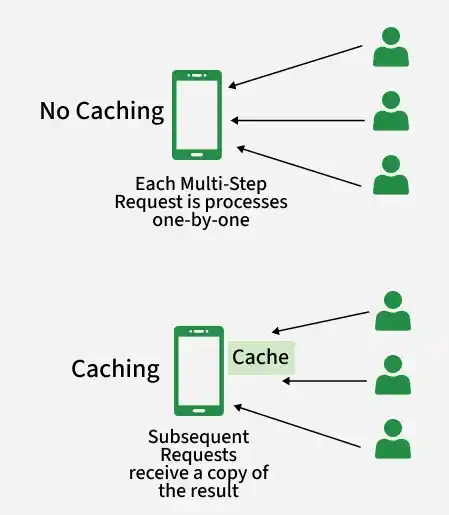
2. Caching
Caching stores frequently accessed data in faster memory for quick retrieval instead of repeatedly querying the database. It reduces database load and improves system performance. Commonly used data is kept readily available for faster access.
- Reduces database load by minimizing repeated queries and lowering unnecessary data access operations.
- Improves response time and overall performance by fetching data from faster memory (RAM) and reducing network calls.
Example: Platforms like YouTube use caching and CDNs to store videos, images, and static content closer to users, ensuring faster loading and smooth playback.
Cache Invalidation: Strategies like TTL (time-based expiry), write-through, or write-back ensure stale data is updated or removed, while also reducing unnecessary database load and improving overall read performance.
Consistency Challenges: Cached data may become outdated, so systems must carefully balance freshness vs performance using approaches like eventual consistency, cache refresh policies, and controlled invalidation mechanisms.
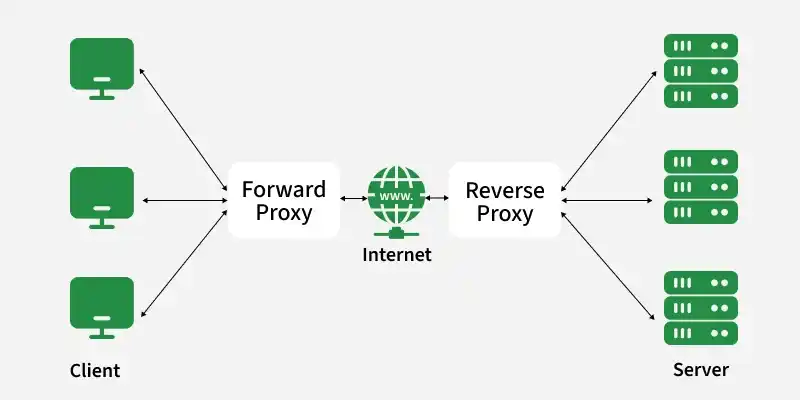
3. Proxies
A proxy server acts as an intermediary between a client and a server, managing requests and responses to improve performance, security, and control. It can hide identities, optimize traffic flow, and add an extra layer between users and servers in a system.
- Filters, logs, and transforms requests (e.g., headers, encryption, compression) while also optimizing and coordinating traffic for better performance.
- Enhances security by acting as a gatekeeper and hiding internal client/server details.
Example: When you access Netflix, a proxy layer may handle incoming requests, distribute traffic, and ensure smooth and secure streaming.
Forward Proxy: A forward proxy acts on behalf of the client, handling requests and hiding the user’s identity from the server. It is mainly used for privacy, access control, and filtering outgoing requests.
Reverse Proxy: A reverse proxy acts on behalf of the server, managing incoming requests and distributing them across backend servers. It helps improve performance, security, and scalability by acting as a gateway in front of servers.
4. CAP Theorem
CAP stands for Consistency, Availability, and Partition Tolerance. The theorem states that in a distributed system, you cannot fully achieve all three properties at the same time due to inherent trade-offs, so you must prioritize based on system requirements. For example, if you choose Availability and Partition Tolerance, you may need to accept some delay or inconsistency in data.
- Traditional relational databases are generally a natural fit for CA (Consistency + Availability) systems.
- Most non-relational (NoSQL) database engines are designed to support either AP (Availability + Partition Tolerance) or CP (Consistency + Partition Tolerance) depending on their architecture and use case.
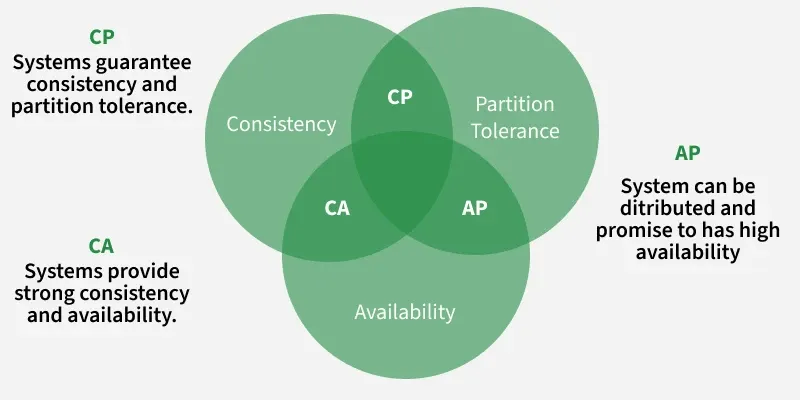
- Consistency means that any read request will return the most recent write. Data consistency is usually “strong” for SQL databases and for NoSQL databases consistency may be anything from “eventual” to “strong”.
- Availability means that a non-responding node must respond in a reasonable amount of time. Not every application needs to run 24/7 with 99.999% availability but most likely you will prefer a database with higher availability.
- Partition tolerance means the system will continue to operate despite network or node failures.
The CAP theorem helps in choosing between Consistency, Availability, and Partition Tolerance in distributed systems. Since partition tolerance is essential, systems usually trade off between consistency (CP) and availability (AP). Availability is preferred for systems that must stay always online, while consistency is critical for financial or transactional systems. CA systems are only possible in single-node environments, so the choice depends on use case needs.
5. Databases
Databases store and manage application data, and in system design interviews you’re often asked to design schemas, define primary keys, and choose the right storage type (SQL or NoSQL). A well-designed database ensures efficient data access and scalability for large systems.
- Defines data structure using tables/collections and relationships while influencing how data is organized and accessed.
- Choice between relational and non-relational databases based on use case, impacting performance, scalability, and consistency.
Example: In Instagram, databases store user profiles, posts, comments, and relationships between users.
1. Indexing
Indexing is a technique used to speed up data retrieval by creating a separate data structure that points to actual records. Instead of scanning entire tables, indexes allow faster lookups using efficient search methods.
- Improves query performance by avoiding full table scans and using indexed access for faster data retrieval.
- Uses sorted data structures (like binary search) for quick searching but adds extra storage and slight overhead on write operations.
Example: In LinkedIn, indexing on user names or skills helps quickly search profiles from millions of records.
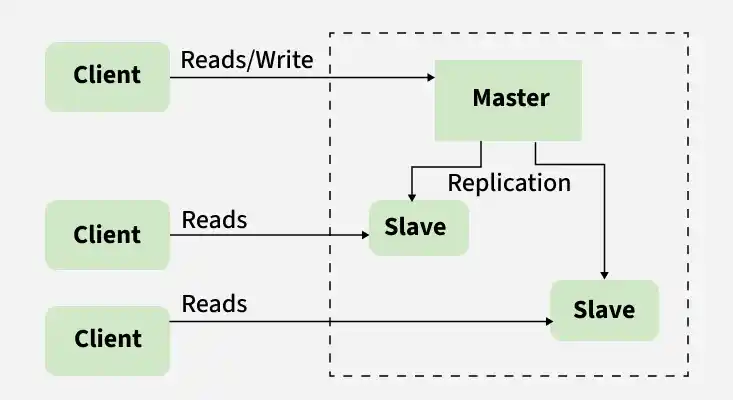
2. Replication
Replication involves creating multiple copies of a database to improve availability and handle high traffic. If one database fails, others can continue serving requests, ensuring system reliability.
- Enhances availability and fault tolerance while supporting read scaling through the use of replicas.
- Replication can be synchronous (strong consistency) or asynchronous (better performance depending on system needs).
Example: In Facebook, replication ensures users can still access data even if some database servers go down.
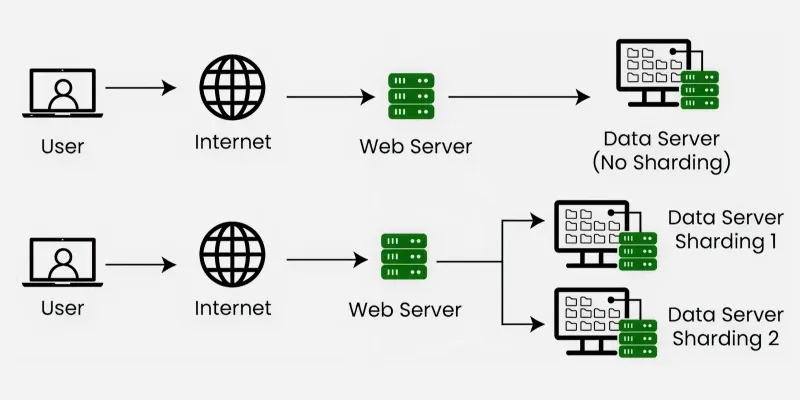
3. Sharding
Sharding is the process of splitting a large database into smaller pieces (shards) distributed across multiple servers. Each shard handles a portion of the data, helping scale systems horizontally.
- Distributes data across multiple servers to handle massive scale and reduce load on a single database.
- Requires careful shard key selection to ensure balanced distribution and efficient querying.
Example: In Twitter, user data is sharded across multiple servers so the platform can handle millions of active users efficiently.
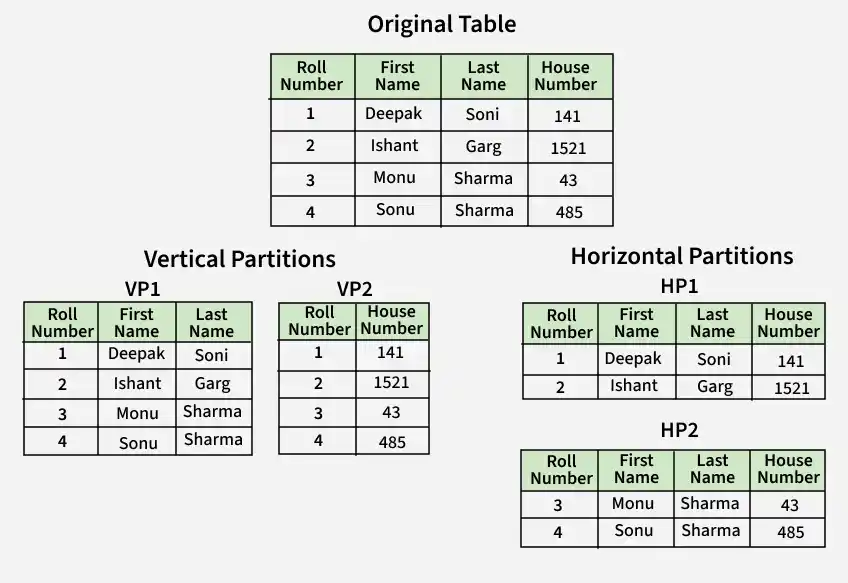
4. Partitioning
Partitioning is the process of dividing a large database into smaller parts within the same server to improve query performance and manageability. It helps in organizing data efficiently without distributing it across multiple machines.
- Improves query performance by scanning smaller, more targeted data chunks instead of the entire dataset.
- Keeps data logically separated (e.g., by date or region) while operating within a single database or server.
Example: In Twitter, tweets may be partitioned by date so recent data can be accessed faster.