Recommender Systems are tools that suggest items to users based on their behaviour, preferences or past interactions. They help users find relevant products, movies, songs or content without manually searching for them. They are widely used in platforms like YouTube, Amazon and Netflix.
- Suggest items automatically
- Use user behaviour and patterns
- Improve content discovery
- Common in e-commerce and entertainment apps
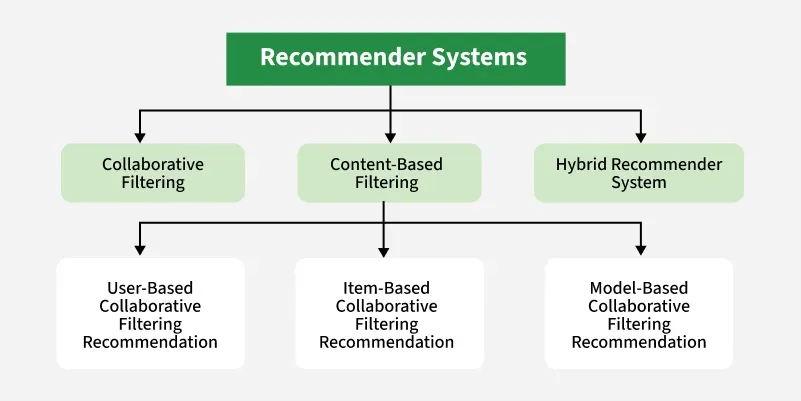
Types of Recommender Systems
Let's see the various types:
1. Content-Based Filtering: Content-based filtering recommends items similar to those a user liked earlier by analyzing item features and user preference profiles.
- Useful when users have strong, consistent preferences.
- Seen in movie apps suggesting films of the same genre or style.
- Advantage: Personalization without needing other users data.
- Limitation: Lack of novelty because it focuses on similar items only.
2. Collaborative Filtering: Collaborative filtering identifies similarities in user behavior and recommends items based on patterns derived from many users.
- Works well with large datasets of user interactions.
- Used in Amazon’s “Users who bought this also bought” and Netflix suggestions.
- Advantage: Discovery of new items outside a user’s past history.
- Limitation: Cold-start issues with new items or new users.
3. Hybrid Recommendation Systems: Hybrid systems combine collaborative and content-based methods to offer more accurate and robust recommendations.
- Useful where both user behavior and item features provide value.
- Seen in platforms like Netflix that blend metadata and viewing patterns.
- Advantage: Reduced weaknesses and better overall performance.
- Limitation: Increased complexity and higher computational cost.
4. Knowledge-Based Recommendation Systems: Knowledge-based systems use explicit domain knowledge and user requirements rather than historical behavior to suggest items.
- Ideal for high-involvement domains like real estate or financial products.
- Seen in travel planning apps or loan product matchers.
- Advantage: No need for past interactions.
- Limitation: Effort required to build domain-specific rules.
5. Context-Aware Recommendation Systems: These systems use contextual information such as time, location, device or mood to personalize recommendations.
- Effective in mobile and location-based applications.
- Seen in restaurant suggestions based on time of day or location.
- Advantage: Higher relevance through situational awareness.
- Limitation: Complexity in capturing and processing contextual data.
Working
Let's see how a recommender system works,
- Data Collection: Collect ratings, clicks, views, purchases, searches and item metadata.
- Data Preprocessing: Clean data, handle missing values and prepare user–item matrices.
- Feature Engineering: Transform user and item characteristics into meaningful vectors.
- Model Training / Similarity Computation: Use algorithms like collaborative filtering, content-based models or deep learning.
- Prediction: Generate relevance scores for unseen items based on learned patterns.
- Ranking & Recommendation: Sort items by predicted relevance and recommend the top ones.
- Feedback Loop: Update the model continuously as new user interactions arrive.
Implementation
Let's see how a recommendation system works with an example of movie recommender system,
The used dataset can be downloaded from here.
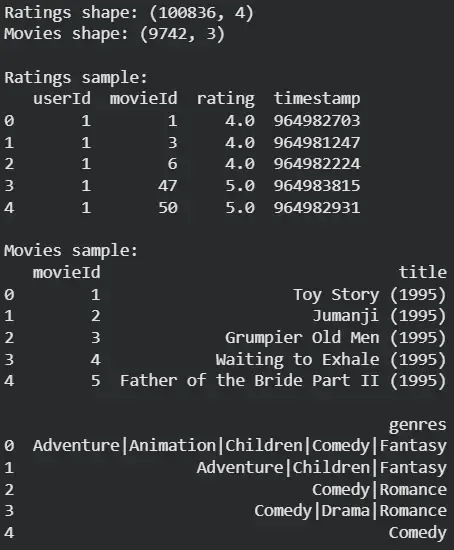
Step 1: Load and Inspect Dataset
We will load the dataset and inspect the dataset,
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
DATA_PATH = ""
ratings = pd.read_csv(DATA_PATH + "ratings.csv")
movies = pd.read_csv(DATA_PATH + "movies.csv")
print("Ratings sample:")
print(ratings.head())
print("\nMovies sample:")
print(movies.head())
Output:
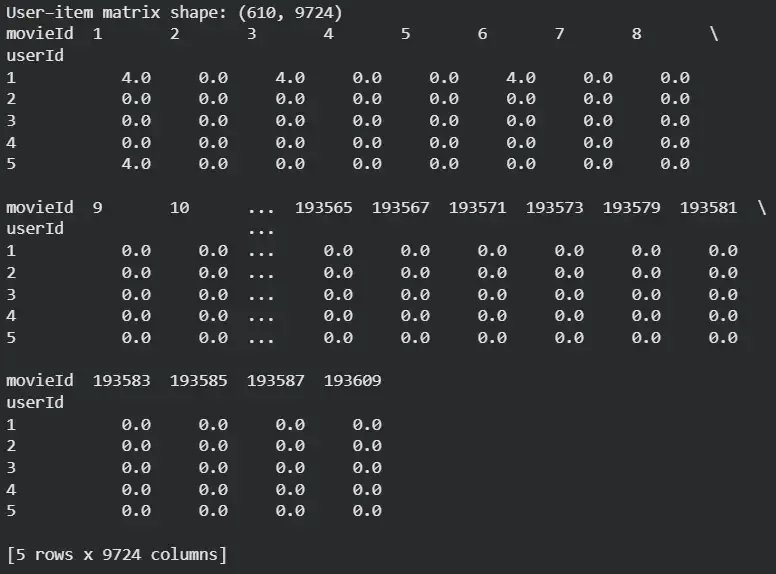
Step 2: Build User–Item Rating Matrix
- Converts raw data into a matrix required for collaborative filtering.
- Missing values (no rating) are replaced with zero.
ratings_matrix = ratings.pivot_table(
index="userId",
columns="movieId",
values="rating"
)
ratings_matrix = ratings_matrix.fillna(0)
print(ratings_matrix.head())
Output:
Step 3: Compute Item–Item Similarity
- Treats each movie as a vector of user ratings.
- Computes cosine similarity between movies.
item_vectors = ratings_matrix.T
item_similarity = cosine_similarity(item_vectors)
item_similarity_df = pd.DataFrame(
item_similarity,
index=item_vectors.index,
columns=item_vectors.index
)
Step 4: Build the Recommendation Function
- Predicts movie scores using weighted similarity with movies the user rated.
- Excludes already-rated items from recommendations.
def get_item_based_recommendations(user_id, ratings_matrix, item_similarity_df, top_n=10):
user_ratings = ratings_matrix.loc[user_id]
rated_movies = user_ratings[user_ratings > 0].index
if len(rated_movies) == 0:
return None
scores = pd.Series(0.0, index=ratings_matrix.columns)
sim_sums = pd.Series(0.0, index=ratings_matrix.columns)
for movie_id in rated_movies:
sim_vector = item_similarity_df[movie_id]
scores += sim_vector * user_ratings[movie_id]
sim_sums += sim_vector.abs()
predicted_scores = scores / sim_sums.replace(0, np.nan)
predicted_scores[rated_movies] = np.nan
return predicted_scores.sort_values(ascending=False).head(top_n)
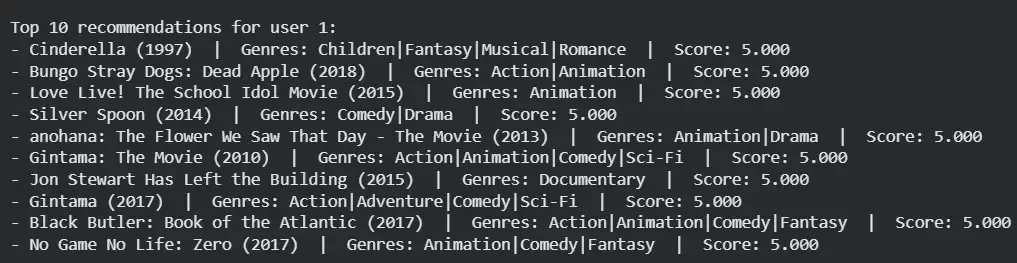
Step 5: Display Recommendations with Movie Titles
- Joins predicted IDs with titles and genres.
- Prints a clean, ready-to-use recommendation list.
def pretty_print_recommendations(user_id, top_n=10):
top_recs = get_item_based_recommendations(
user_id,
ratings_matrix,
item_similarity_df,
top_n
)
if top_recs is None:
print("No recommendations available.")
return
movie_lookup = movies.set_index("movieId")
rec_movies = movie_lookup.loc[top_recs.index]
rec_movies["score"] = top_recs.values
print(f"\nTop {top_n} Recommendations for User {user_id}:")
for _, row in rec_movies.iterrows():
print(
f"- {row['title']} | Genres: {row['genres']} | Score: {row['score']:.3f}")
pretty_print_recommendations(user_id=1, top_n=10)
Output:
Deep Learning Models Used in Recommender Systems
Let's see the various types of deep learning models that are used in recommender systems,
1. Neural Collaborative Filtering (NCF)
- Learns non-linear and complex user–item interaction patterns using multilayer neural networks.
- Offers better flexibility than traditional matrix factorization by learning interactions directly from data.
2. Autoencoders
- Encode sparse user–item matrices into dense latent embeddings and reconstruct missing values.
- Useful for denoising, dimensionality reduction and generating more accurate rating predictions.
3. Recurrent Neural Networks (RNNs)
- Model sequential user behavior by capturing the order of interactions (e.g., the next movie or product a user is likely to consume).
- Effective for session-based and time-dependent recommendation tasks.
4. Convolutional Neural Networks (CNNs)
- Extract deep feature representations from images, text or audio to support content-based recommendations.
- Common in scenarios like recommending visually similar products or tagging video content.
5. Transformer Models
- Use attention mechanisms to understand long-range dependencies in user interaction sequences.
- Provide state-of-the-art performance in next-item prediction and context-aware recommendation.
6. Wide & Deep Models / DeepFM
- Combine memorization (feature interactions) and generalization (deep neural networks) for large-scale recommendation problems.
- Widely adopted in advertising and e-commerce platforms due to strong performance with structured data.
Importance
Let's see the importance of recommender systems,
- Improve user satisfaction by providing relevant and personalized recommendations.
- Reduce information overload by efficiently filtering large volumes of content.
- Increase user engagement by helping users discover items they are likely to enjoy.
- Boost conversions and revenue through targeted and data-driven suggestions.
- Enhance customer retention by delivering consistent, personalized interactions.