Machine learning classification algorithms are essential tools used to categorize data into predefined classes based on learned patterns. From simple linear models to advanced neural networks, these algorithms are used in applications like spam detection, image recognition, sentiment analysis and medical diagnosis.
- Includes Logistic Regression, Decision Trees, Random Forest, SVM, KNN, Naive Bayes and more
- Each algorithm has unique strengths suited for different datasets and problem types
- Widely used across AI systems for fast, accurate and scalable prediction tasks
Let's see a few of the top Machine Learning Classification algorithms.
1. Logistic Regression
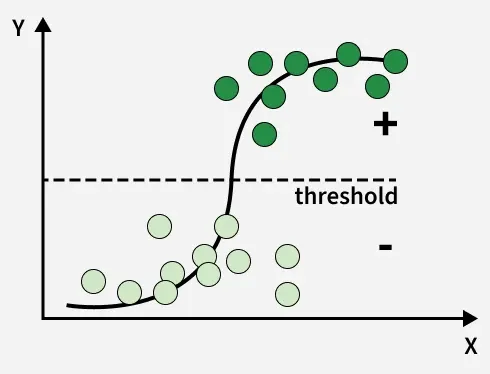
Logistic Regression is a linear classification algorithm that estimates the probability of a data point belonging to a particular class using the sigmoid function. Despite its name, it is primarily used for classification tasks, especially binary classification problems. It models the relationship between input features and the probability of a class label.
- Uses a logistic (sigmoid) function to map outputs to probabilities.
- Works well when classes are linearly separable.
- Outputs probabilities rather than direct class labels.
- Simple and computationally efficient.
Advantages
- Easy to implement and interpret.
- Performs well on linearly separable data.
- Less prone to overfitting with regularization.
- Probabilistic output helps in decision-making.
Limitations
- Struggles with non-linear relationships.
- Sensitive to outliers.
- Assumes linear relationship between features and log-odds.
2. K-Nearest Neighbors (KNN)
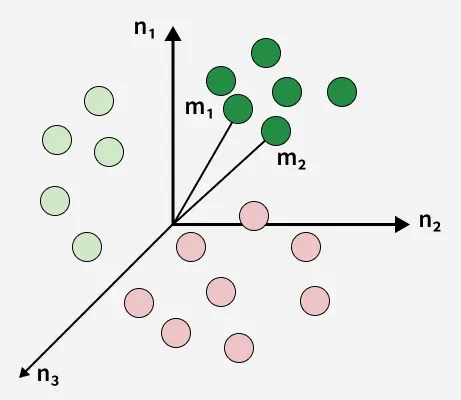
K-Nearest Neighbors is a distance-based classification algorithm that assigns a class to a data point based on the majority class among its nearest neighbors. It is a lazy learning algorithm, meaning it does not build an explicit model during training.
- Uses distance metrics such as Euclidean or Manhattan distance.
- No training phase, predictions made at runtime.
- Sensitive to feature scaling.
- Works well with small datasets.
Advantages
- Simple and intuitive approach.
- No assumptions about data distribution.
- Effective for multi-class classification.
Limitations
- Computationally expensive for large datasets.
- Sensitive to noise and irrelevant features.
- Requires careful selection of K value.
3. Decision Tree
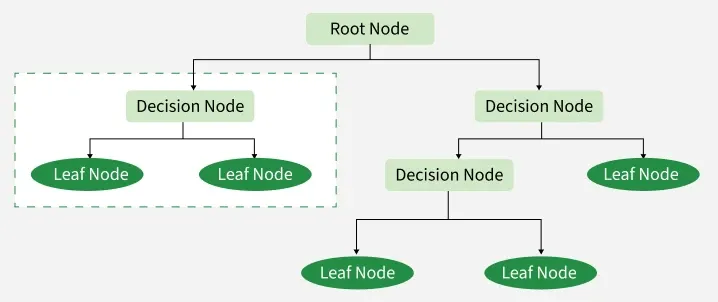
Decision Tree is a tree-structured classification algorithm where internal nodes represent feature tests, branches represent decision rules and leaf nodes represent class labels. It mimics human decision-making logic.
- Uses entropy or Gini index for splits.
- Handles both numerical and categorical data.
- Produces interpretable tree structures.
- No need for feature scaling.
Advantages
- Easy to visualize and interpret.
- Handles non-linear relationships.
- Works well with mixed data types.
Limitations
- Prone to overfitting.
- Sensitive to small changes in data.
- Can become complex with deep trees.
4. Support Vector Machine (SVM)
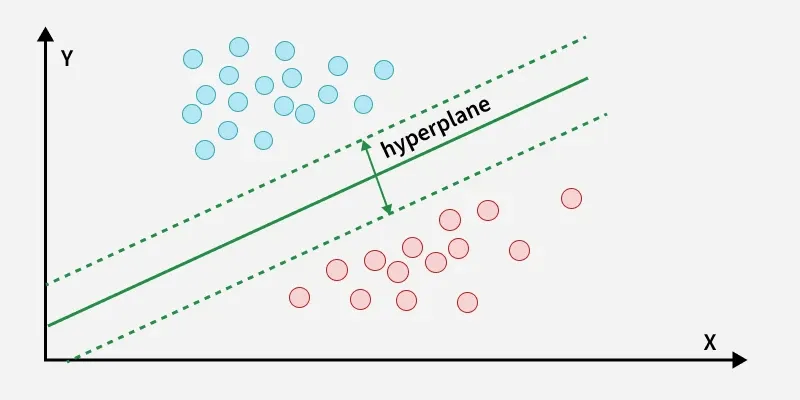
Support Vector Machine constructs an optimal hyperplane that maximizes the margin between different classes. It can handle both linear and non-linear classification using kernel functions.
- Uses kernel tricks for non-linear data.
- Maximizes margin for better generalization.
- Effective in high-dimensional spaces.
- Robust to overfitting in many cases.
Advantages
- High accuracy for complex datasets.
- Works well with small to medium datasets.
- Flexible kernel selection.
Limitations
- Computationally expensive.
- Difficult to interpret.
- Requires careful parameter tuning.
5. Naive Bayes
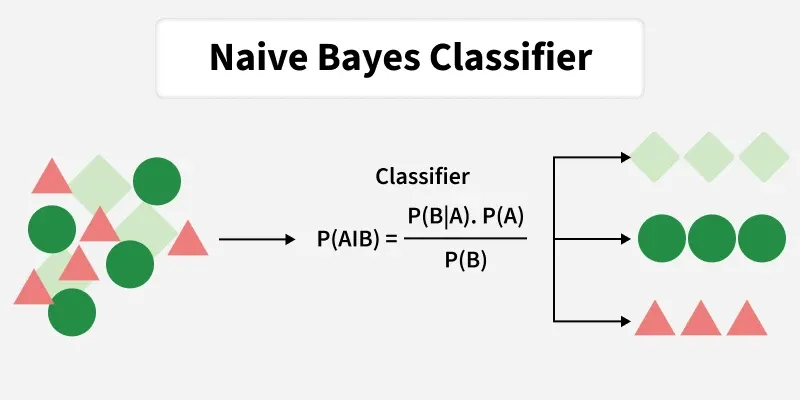
Naive Bayes is a probabilistic classification algorithm based on Bayes’ Theorem, which calculates the probability of a class given the input features. It assumes that all features are conditionally independent given the class label, which simplifies computation.
- Uses probability distributions.
- Assumes feature independence.
- Fast and memory-efficient.
- Works well with high-dimensional data.
Advantages
- Very fast training and prediction.
- Performs well on text and spam classification.
- Handles large datasets efficiently.
Limitations
- Independence assumption rarely holds true.
- Poor performance with correlated features.
- Less accurate than complex models.
6. Random Forest
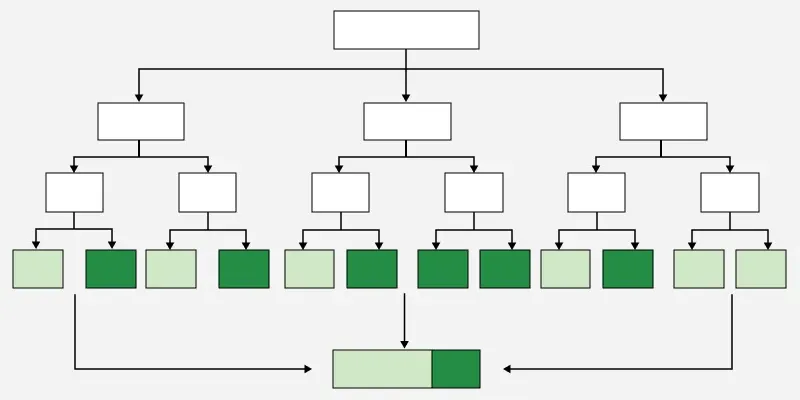
Random Forest is an ensemble classification algorithm that builds multiple decision trees using random subsets of data and features and combines their predictions through majority voting. By aggregating the results of many weak learners, Random Forest improves predictive accuracy and reduces overfitting commonly seen in single decision trees.
- Uses bagging technique.
- Reduces variance of decision trees.
- Handles missing values effectively.
- Provides feature importance scores.
Advantages
- High accuracy and robustness.
- Handles large datasets well.
- Reduces overfitting compared to single trees.
Limitations
- Less interpretable than decision trees.
- Computationally intensive.
- Large models consume more memory.
Comparison of Classification Algorithms
Let's compare the various algorithms,
| Algorithm | Type | Non-Linear Capability | Interpretability | Training Cost | Typical Use |
|---|---|---|---|---|---|
| Logistic Regression | Linear | No | High | Low | Binary problems |
| KNN | Instance-based | Yes | Medium | Low | Small datasets |
| Decision Tree | Rule-based | Yes | Very High | Medium | Explainable models |
| SVM | Margin-based | Yes | Low | High | High-dimensional data |
| Naive Bayes | Probabilistic | Limited | Medium | Very Low | Text analytics |
| Random Forest | Ensemble | Yes | Medium | High | High-accuracy tasks |