Data processing in machine learning involves converting raw, unstructured data into a well-organized and usable format for analysis and modeling. Effective data processing improves the performance and reliability of machine learning algorithms allowing them to detect patterns, generate accurate predictions and provide actionable insights.
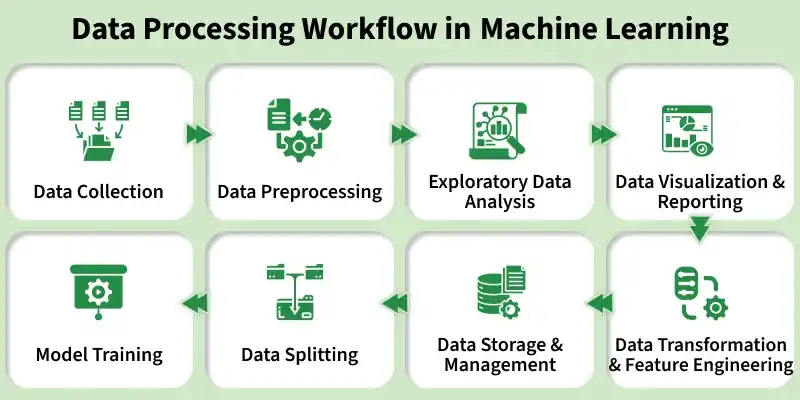
Data Processing Workflow in Machine Learning
1. Data Collection
Data processing starts with collecting relevant data from sources such as databases, files, APIs and sensors. The data, including features, labels or target variables, is integrated into a consistent format while ensuring quality, completeness and legal compliance.
2. Data Preprocessing
Data preprocessing prepares raw data for analysis by cleaning, filtering and transforming it into a consistent and usable format. This step ensures that machine learning algorithms can learn effectively and produce accurate results. It includes
- Handling Missing Values: Impute using mean, median or mode or remove affected rows/columns.
- Normalizing Data: Scale numerical features to a standard range for uniformity.
- Encoding Categorical Variables: Convert categories into numeric form using techniques like one-hot or label encoding.
- Handling Outliers: Detect outliers using statistical methods or box plots and remove or transform them.
- Balancing Data: Adjust class distributions in imbalanced datasets through oversampling, undersampling or synthetic data generation.
3. Exploratory Data Analysis
Exploratory Data Analysis (EDA) involves examining cleaned data to understand its structure, behavior and key patterns. It helps uncover insights, validate assumptions and support decisions for feature engineering and model selection.
- Analyze distributions of variables to understand data spread and variability
- Identify relationships and correlations among features
- Detect trends, anomalies and potential biases in the data
4. Data Visualization and Reporting
Analytical results are interpreted and communicated in a clear and actionable manner. Visual representations make complex findings easier to understand for stakeholders.
- Present results using graphs, charts and dashboards
- Highlight important trends and anomalies
- Improve interpretability of analytical outcomes
5. Data Transformation and Feature Engineering
Data transformation and feature engineering convert cleaned data into a form suitable for machine learning models while extracting or creating meaningful features to improve performance. This step ensures models can learn efficiently and capture the most relevant information from the dataset. Key Techniques include:
- Feature Scaling: Normalize or standardize numerical data for models sensitive to feature magnitudes.
- Data Augmentation: Expand datasets artificially for images or text to enhance model learning.
- Feature Selection: Identify and retain the most relevant features using methods like Recursive Feature Elimination (RFE) or mutual information.
- Feature Extraction: Generate new features or reduce dimensionality using techniques such as Principal Component Analysis (PCA).
- Domain Expertise: Leverage knowledge of the problem domain to create meaningful, model-relevant features.
6. Data Storage and Management
Processed data and results are stored securely to enable future access and reuse. Proper storage ensures data reliability, scalability and protection against loss.
- Store data in databases, cloud platforms or data warehouses
- Implement security and access control mechanisms
- Apply backup and recovery strategies
7. Data Splitting
Processed data is divided into separate subsets to ensure unbiased training and evaluation. This step helps assess model performance on unseen data and avoids overfitting.
- Split data into training, validation and testing sets
- Ensure random and representative sampling
- Prevent data leakage between datasets
8. Model Training
In this step, machine learning algorithms are applied to the prepared data to learn patterns and relationships. The model adjusts its parameters using training data to improve prediction accuracy.
- Select an appropriate algorithm based on the problem type
- Train the model using the training dataset
- Optimize model parameters to minimize error
Advantages
Data processing plays a crucial role in improving the overall effectiveness of machine learning models by preparing data in a structured and meaningful way.
- Improves model performance by transforming raw data into a format suitable for learning
- Enables better data representation, allowing models to capture underlying patterns more effectively
- Increases accuracy by ensuring data is clean, consistent and reliable
Limitation
Despite its benefits, data processing can introduce certain challenges that impact efficiency and outcomes.
- Can be time-consuming and resource-intensive, especially when handling large datasets
- May be error-prone if done manually or using improperly configured tools, leading to bias or information loss
- Can reduce understanding of original data if excessive processing removes meaningful context.