Recurrent Neural Networks (RNNs) are designed for sequential data such as text, speech and time series. Unlike traditional neural networks, RNNs use an internal memory (hidden state) so the output depends on both current and previous inputs.
- Handles sequential and time-dependent data
- Uses hidden states to store information from previous time steps
- Captures temporal dependencies across sequences
- Uses Backpropagation Through Time (BPTT) for learning
- Learns complex sequential patterns from data
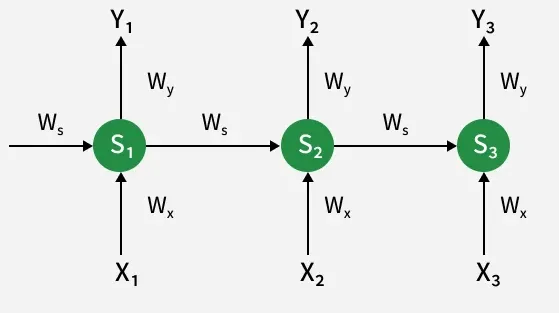
RNN Architecture
At each timestep
S_t = g_1(W_x X_t + W_s S_{t-1})
S_t represents the hidden state (memory) at timet .X_t is the input at timet. Y_t is the output at timet. W_s, W_x, W_y are weight matrices for hidden states, inputs and outputs, respectively.
Y_t = g_2(W_y S_t)
where
Error Function at Time t=3
To train the network, we measure how far the predicted output
E_t = (d_t - Y_t)^2
At
E_3 = (d_3 - Y_3)^2
This error quantifies the difference between the predicted output and the actual output at time 3.
Updating Weights Using BPTT
Backpropagation Through Time (BPTT) updates the weights
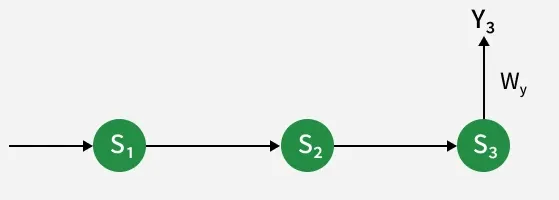
1. Adjusting Output Weight W_y
The output weight
Using the chain rule:
\frac{\partial E_3}{\partial W_y} = \frac{\partial E_3}{\partial Y_3} \times \frac{\partial Y_3}{\partial W_y}
E_3 depends onY_3 , so we differentiateE_3 w.r.t.Y_3 .Y_3 depends onW_y , so we differentiateY_3 w.r.t.W_y .
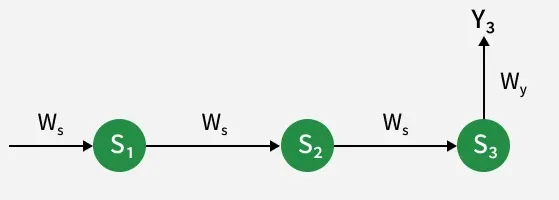
2. Adjusting Hidden State Weight W_s
The hidden state weight
\frac{\partial E_3}{\partial W_s} = \sum_{i=1}^3 \frac{\partial E_3}{\partial Y_3} \times \frac{\partial Y_3}{\partial S_i} \times \frac{\partial S_i}{\partial W_s}
Gradient Flow Through Hidden States
- Start with the error gradient at output
Y_3 . - Propagate gradients back through all hidden states
S_3, S_2, S_1 since they affectY_3 . - Each
S_i depends onW_s , so we differentiate accordingly.
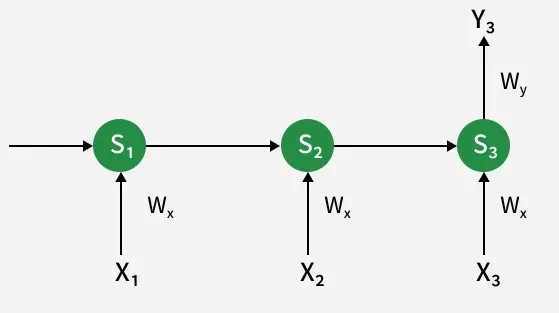
3. Adjusting Input Weight W_x
Similar to
\frac{\partial E_3}{\partial W_x} = \sum_{i=1}^3 \frac{\partial E_3}{\partial Y_3} \times \frac{\partial Y_3}{\partial S_i} \times \frac{\partial S_i}{\partial W_x}
The process is similar to
Advantages
- Captures temporal dependencies across time steps
- Learns how past inputs influence future outputs
- Forms the foundation for training LSTMs and GRUs
- Supports learning from variable-length sequences
Limitations
- Gradients may become very small (vanishing gradients), making long-term dependencies difficult to learn
- Gradients may grow excessively large (exploding gradients), causing unstable training and updates