Machine Learning Lifecycle is a structured process used to develop, train, deploy and maintain machine learning models efficiently. It includes multiple stages such as data collection, preprocessing, model training, evaluation and monitoring to ensure accurate and reliable predictions.
- Provides a systematic workflow for building scalable and reliable ML models
- Helps continuously improve model performance through monitoring and retraining
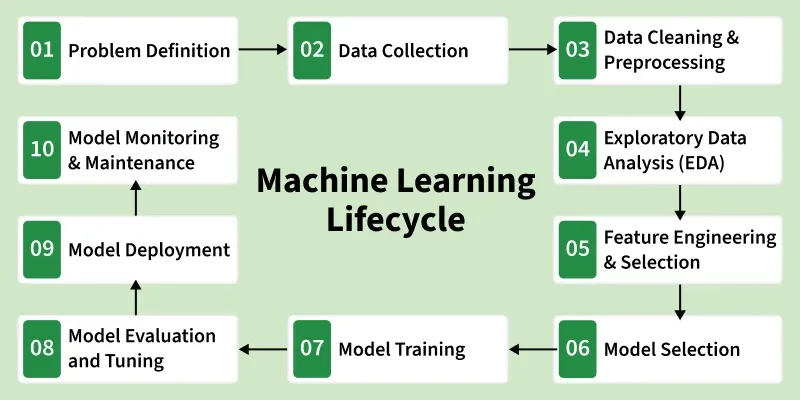
Step 1: Problem Definition
The first step is clearly defining the problem that needs to be solved. A well-framed problem provides the foundation to determine the project goals, expected outcomes and the type of solution required.
- Ensures alignment between business needs and technical solutions
- Define project objectives, scope and success criteria
- Ensure clarity in desired outcomes
Step 2: Data Collection
Data Collection phase involves systematic collection of datasets that can be used as raw data to train model. The quality and variety of data directly affect the model’s performance.
Here are some basic features of Data Collection:
- Relevance: Collect data should be relevant to the defined problem and include necessary features.
- Quality: Ensure data quality by considering factors like accuracy and ethical use.
- Quantity: Gather sufficient data volume to train a robust model.
- Diversity: Include diverse datasets to capture a broad range of scenarios and patterns.
Step 3: Data Cleaning and Preprocessing
Raw data is often messy and unstructured and if we use this data directly to train then it can lead to poor accuracy. We need to do data cleaning and preprocessing which often involves:
- Data Cleaning: Address issues such as missing values, outliers and inconsistencies in the data.
- Data Preprocessing: Standardize formats, scale values and encode categorical variables for consistency.
- Data Quality: Ensure that the data is well-organized and prepared for meaningful analysis.
Step 4: Exploratory Data Analysis (EDA)
To find patterns and characteristics hidden in the data Exploratory Data Analysis (EDA) is used to uncover insights and understand the dataset's structure. During EDA patterns, trends and insights are provided which may not be visible by naked eyes. This valuable insight can be used to make informed decision.
Here are the basic features of Exploratory Data Analysis:
- Exploration: Use statistical and visual tools to explore patterns in data.
- Patterns and Trends: Identify underlying patterns, trends and potential challenges within the dataset.
- Insights: Gain valuable insights for informed decisions making in later stages.
- Decision Making: Use EDA for feature engineering and model selection.
Step 5: Feature Engineering and Selection
Feature engineering and selection is a transformative process that involve selecting only relevant features to enhance model efficiency and prediction while reducing complexity.
Here are the basic features of Feature Engineering and Selection:
- Feature Engineering: Create new features or transform existing ones to capture better patterns and relationships.
- Feature Selection: Identify subset of features that most significantly impact the model's performance.
- Domain Expertise: Use domain knowledge to engineer features that contribute meaningfully for prediction.
- Optimization: Balance set of features for accuracy while minimizing computational complexity.
Step 6: Model Selection
For a good machine learning model, model selection is a very important part as we need to find model that aligns with our defined problem, nature of the data, complexity of problem and the desired outcomes.
Here are the basic features of Model Selection:
- Complexity: Consider the complexity of the problem and the nature of the data when choosing a model.
- Decision Factors: Evaluate factors like performance, interpretability and scalability when selecting a model.
- Experimentation: Experiment with different models to find the best fit for the problem.
Step 7: Model Training
With the selected model the machine learning lifecycle moves to model training process. This process involves exposing model to historical data allowing it to learn patterns, relationships and dependencies within the dataset.
Here are the basic features of Model Training:
- Iterative Process: Train the model iteratively, adjusting parameters to minimize errors and enhance accuracy.
- Optimization: Fine-tune model to optimize its predictive capabilities.
- Validation: Rigorously train model to ensure accuracy to new unseen data.
Step 8: Model Evaluation and Tuning
Model evaluation involves rigorous testing against validation or test datasets to test accuracy of model on new unseen data. It provides insights into model's strengths and weaknesses. If the model fails to acheive desired performance levels we may need to tune model again and adjust its hyperparameters to enhance predictive accuracy.
Here are the basic features of Model Evaluation and Tuning:
- Evaluation Metrics: Use metrics like accuracy, precision, recall and F1 score to evaluate model performance.
- Strengths and Weaknesses: Identify the strengths and weaknesses of the model through rigorous testing.
- Iterative Improvement: Initiate model tuning to adjust hyperparameters and enhance predictive accuracy.
- Model Robustness: Iterative tuning to achieve desired levels of model robustness and reliability.
Step 9: Model Deployment
Now model is ready for deployment for real-world application. It involves integrating the predictive model with existing systems allowing business to use this for informed decision-making.
Here are the basic features of Model Deployment:
- Integrate with existing systems
- Enable decision-making using predictions
- Ensure deployment scalability and security
- Provide APIs or pipelines for production use
Step 10: Model Monitoring and Maintenance
After Deployment models must be monitored to ensure they perform well over time. Regular tracking helps detect data drift, accuracy drops or changing patterns and retraining may be needed to keep the model reliable in real-world use.
Here are the basic features of Model Monitoring and Maintenance:
- Track model performance over time
- Detect data drift or concept drift
- Update and retrain the model when accuracy drops
- Maintain logs and alerts for real-time issues