Latent Semantic Analysis (LSA) is a technique used to find hidden relationships and meanings in text data. It analyzes how words appear in different documents and helps computers understand the context of words instead of only matching exact words.
- Converts text into a document-term matrix.
- Uses mathematical methods to reduce unnecessary data.
- Finds relationships between similar words and documents.
- Helps in search engines and text analysis tasks.

Working of Latent Semantic Analysis
Latent Semantic Analysis (LSA) first creates a Document-Term Matrix (DTM) to show word frequencies in different documents. It then uses Singular Value Decomposition (SVD) to reduce dimensions, remove less important information and find hidden relationships between words and documents based on meaning.
1. Document term matrix
The first step in LSA is creating a Document-Term Matrix (DTM).
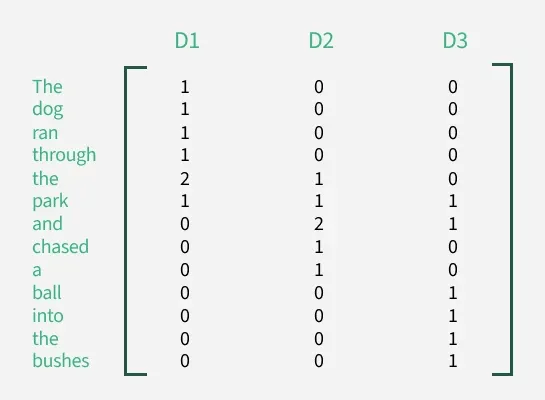
- Each row represents a word.
- Each column represents a document.
- Each cell shows how many times a word appears in a document.
- Sometimes, TF-IDF scores are used instead of normal word counts to give more importance to meaningful and less common words.
- This matrix helps identify patterns and relationships between words and documents.
2. Dimensionality Reduction
After creating the Document-Term Matrix , the matrix becomes very large and sparse. To simplify it, Latent Semantic Analysis uses Singular Value Decomposition (SVD), which breaks the matrix into smaller matrices and keeps only the most important components.

- SVD reduces unnecessary data and noise.
- It keeps the most meaningful patterns in the text.
- Only the top k components are selected.
- This helps identify hidden relationships between words and documents.
3. Analyse Semantic Relationships
After dimensionality reduction, words and documents are represented in a smaller semantic space based on important topics and patterns.
- Words used in similar contexts appear closer together.
- Latent Semantic Analysis can identify similar meanings between different words.
- It helps detect semantic and conceptual relationships in text.
4. Document comparison
After converting documents into semantic form, they can be compared easily using measures like cosine similarity.
- Similar documents appear closer together.
- Documents with different words but similar meaning can still be matched.
- Useful for search engines, document clustering and grouping similar articles.
Applications
- Improves search engines by finding documents based on meaning instead of exact keywords.
- Groups similar documents together based on common topics and content.
- Detects paraphrased or reworded content by comparing semantic meaning between documents.
- Helps question-answering systems find the most relevant answers based on semantic similarity.
Advantages
- Helps find hidden relationships and meanings between words and documents.
- Can identify similar words and understand different meanings based on context.
- Reduces noise by keeping only the most important patterns in the data.
- Improves search and information retrieval by matching content based on meaning, not just keywords.
Limitations
- Ignores word order and grammar because it treats text as a bag of words.
- SVD computation on large datasets requires high time and memory.
- Uses a fixed semantic space, so it does not adapt well to new contexts.
- Not suitable for real-time systems or streaming data processing.