Syntax Analysis, also called Parsing, is the second stage of a compiler and takes place after Lexical Analysis. In the first stage, the source code is broken into small pieces called tokens. Syntax analysis then checks how these tokens are arranged.
The main goal of syntax analysis is to make sure that the tokens are placed in a correct and meaningful order, according to the grammar rules of the programming language. If the structure is correct, the parser creates a Parse Tree or an Abstract Syntax Tree (AST), which shows the program’s structure in a clear, hierarchical way and helps the compiler understand the code better.
Role of Syntax Analysis
- Takes tokens produced by the lexical analyzer as input
- Verifies the grammatical structure of the program
- Detects syntax errors such as missing semicolons or unmatched parentheses
- Builds a parse tree or AST for further compiler phases
Concepts for Syntax Analysis in Compiler Design
1. Context-Free Grammars (CFG)
A Context-Free Grammar (CFG) defines the syntax rules of a programming language. It consists of production rules that describe how valid strings (token sequences) are formed.
CFGs are powerful enough to represent:
- Nested structures
- Balanced parentheses
- Block-structured programming constructs
Because of this, CFGs are widely used to specify the syntax of programming languages.
2. Derivations
A derivation is the step-by-step process of applying grammar rules to start from the start symbol and finally produce a valid string of tokens.
It helps the parser build a parse tree, which visually shows how the grammar rules are applied to form the structure of the program.
3. Concrete Syntax Tree (CST)
Represents the complete grammatical structure of the source code, including all grammar symbols and punctuation.
4. Abstract Syntax Tree (AST)
A simplified version of the CST that removes unnecessary details and keeps only the essential syntactic structure.
ASTs are preferred in later compiler phases because they are easier to analyze and optimize.
5. Ambiguity
A grammar is called ambiguous when the same input string can be parsed in more than one way, producing multiple parse trees.
This can confuse the compiler and lead to incorrect interpretation of the program, so programming languages are designed using unambiguous grammars.
Features of Syntax Analysis
Syntax Tree Construction
Syntax analysis creates a syntax tree, which is a hierarchical representation of the program. This tree shows how different parts of the code—such as statements, expressions, and operators—are related to each other.
Grammar-Based Validation
The parser uses context-free grammar (CFG) rules to check whether the program follows the correct syntax of the programming language. These grammar rules define how valid programs should be written.
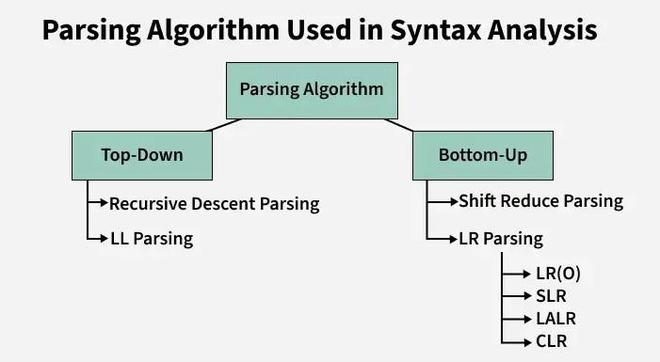
Top-Down and Bottom-Up Parsing
Syntax analysis can be performed using two main parsing techniques:
- Top-Down Parsing: Builds the syntax tree starting from the root and moving toward the leaves.
- Bottom-Up Parsing: Builds the syntax tree starting from the leaves and moving upward to the root.
Error Detection
Syntax analysis detects syntax errors in the program, such as missing semicolons or incorrect statement structure. When an error is found, the parser reports it clearly so the programmer can fix it.
Context-Free Grammar (CFG)
A Context-Free Grammar (CFG) provides a powerful way to define programming languages by handling structures that regular expressions cannot. Unlike regular expressions, CFGs can represent complex and nested patterns, such as:
- Properly balanced parentheses
- Functions with nested blocks
CFGs describe context-free languages, which are more expressive than regular languages. They use production rules to show how symbols can be replaced to form valid programs, making CFGs well-suited for defining the syntax of programming languages.
Parse Tree
A parse tree, also called a syntax tree, is a tree-shaped diagram that shows how a string is formed using the rules of a Context-Free Grammar (CFG). It visually explains how the parser starts from the grammar’s start symbol and applies production rules to generate the input string.
- The root of the tree represents the start symbol of the grammar.
- Internal nodes represent non-terminal symbols, which are expanded using grammar rules.
- Leaf nodes represent terminal symbols, which correspond to the actual tokens in the input.
Example: Suppose Production rules for the Grammar of a language are:
S -> cAd
A -> bc|a
And the input string is “cad”.
Now the parser attempts to construct a syntax tree from this grammar for the given input string. It uses the given production rules and applies those as needed to generate the string. To generate string “cad” it uses the rules as shown in the given diagram:
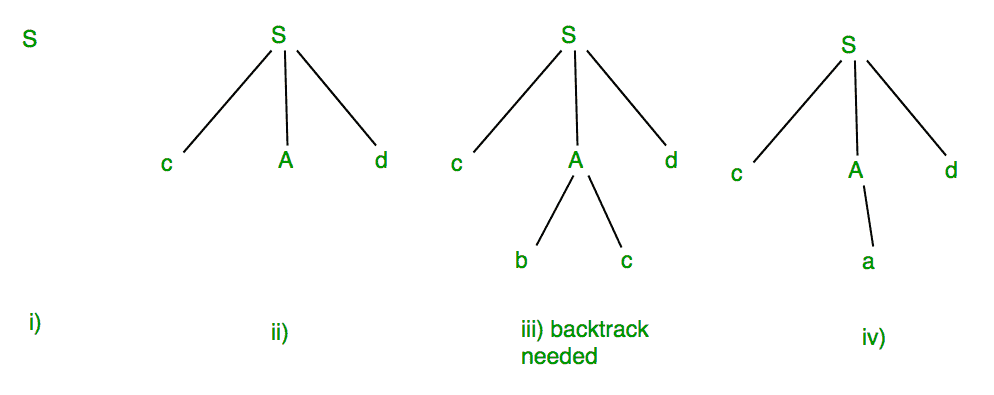
In step (iii) above, the production rule A->bc was not a suitable one to apply (because the string produced is “cbcd” not “cad”), here the parser needs to backtrack, and apply the next production rule available with A which is shown in step (iv), and the string “cad” is produced.
Thus, the given input can be produced by the given grammar, therefore the input is correct in syntax. But backtrack was needed to get the correct syntax tree, which is really a complex process to implement.
Steps in Syntax Analysis Phase
The Syntax Analysis phase, also known as Parsing, checks whether the structure of the source code follows the grammar rules of the programming language.
Parsing
- The parser takes the tokens produced by the lexical analyzer and checks them against the grammar rules. If the structure is valid, it constructs a parse tree or an Abstract Syntax Tree (AST) that represents the hierarchical structure of the program.
Error Handling
- If the source code contains syntax errors, the parser detects them and reports meaningful error messages, often indicating the location of the error so the programmer can correct it.
Symbol Table Interaction
- During parsing, information about identifiers such as their names and scopes is recorded and updated in the symbol table, which is later used by other compiler phases.