The role of social media in public opinion has been profound and evident since it started gaining attention. Social media allows us to share information in a great capacity and on a grand scale. Just after the news of a possible Russia-Ukraine war netizens from across the globe started flooding the platform with their opinions. Analysis of these opinions can help us to understand the thinking of the public on different events before and during the war with the aim of understanding the sentiment of people from all over the world during these events.
In this article we are going to see how we can perform the Twitter sentiment analysis on the Russia-Ukraine War using Python.
1. Importing Libraries
Here we will import pandas, scikit learn, NLTK and RegEx.
import pandas as pd
import re
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report, accuracy_score
import nltk
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
import nltk
nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
2. Loading Dataset
We will loads the CSV dataset and displays the first few rows to understand its structure. You can download daaset from here.
file_path = 'filename.csv'
df = pd.read_csv(file_path)
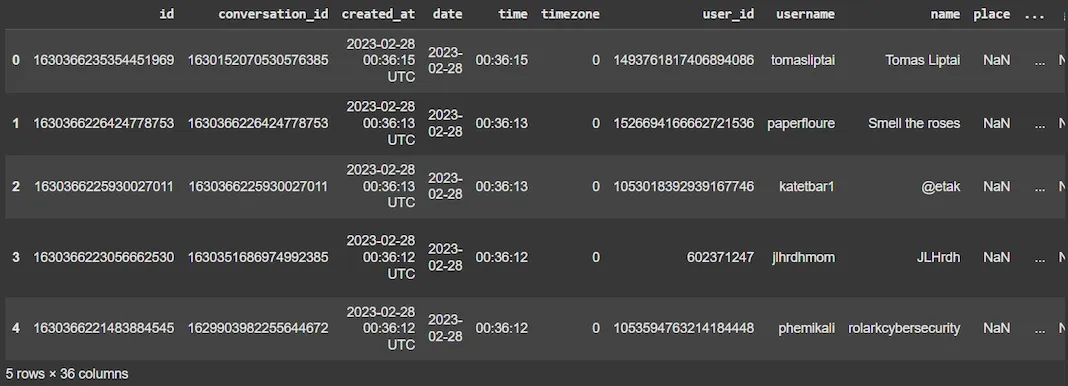
df.head()
Output:
3. Data Cleaning
We will cleans the dataset by removing unnecessary columns, handling missing values and dropping duplicates to ensure the data is ready for analysis.
df.drop(columns=[]): Removes specified columns from the DataFrame.df.dropna(subset=['tweet']): Removes rows where the 'tweet' column has missing values.df.drop_duplicates(subset=['tweet']): Removes duplicate rows based on the 'tweet' column.df_cleaned.info(): Displays the cleaned dataset information to verify the changes.
df_cleaned = df.drop(columns=['place', 'geo', 'source', 'user_rt_id', 'user_rt', 'retweet_id',
'retweet_date', 'translate', 'trans_src', 'trans_dest',
'quote_url', 'thumbnail', 'near', 'reply_to'])
df_cleaned = df_cleaned.dropna(subset=['tweet'])
df_cleaned = df_cleaned.drop_duplicates(subset=['tweet'])
df_cleaned.info()
Output:

4. Text Preprocessing
We will perform text preprocessing on the tweets including converting to lowercase, removing URLs and special characters and normalizing spaces.
re.sub(r'http\S+|www\S+', '', text): Removes URLs from the text.re.sub(r'[^a-zA-Z\s]', '', text): Removes non-alphabetic characters and numbers.' '.join(text.split()): Removes extra spaces by splitting the text into words and joining them back together.df_cleaned['tweet'].apply(alternative_preprocess_text): Applies the preprocessing function to each tweet in the DataFrame.
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
def alternative_preprocess_text(text):
text = text.lower()
text = re.sub(r'http\S+|www\S+', '', text)
text = re.sub(r'[^a-zA-Z\s]', '', text)
text = ' '.join(text.split())
return text
df_cleaned['cleaned_tweet'] = df_cleaned['tweet'].apply(alternative_preprocess_text)
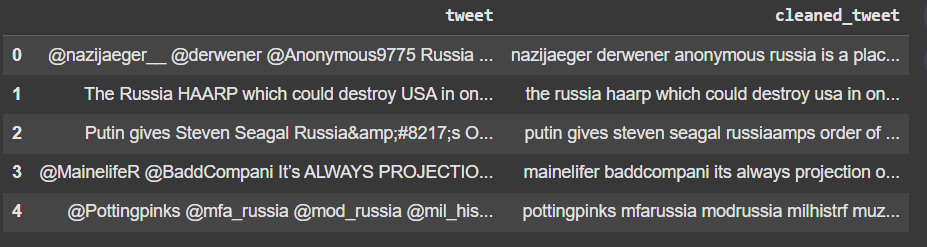
df_cleaned[['tweet', 'cleaned_tweet']].head()
Output:
5. Sentiment Categorization Using VADER
We will use VADER for sentiment analysis to classify the sentiment of each tweet into Positive, Negative or Neutral.
SentimentIntensityAnalyzer(): Initializes the VADER Sentiment Analyzer.sia.polarity_scores(text)['compound']: Returns the compound sentiment score for the text.categorize_sentiment(): Classifies the sentiment based on VADER's compound score (Positive if score > 0.05, Negative if score < -0.05, else Neutral).df_cleaned['cleaned_tweet'].apply(categorize_sentiment): Applies the sentiment classification function to each cleaned tweet.
sia = SentimentIntensityAnalyzer()
def categorize_sentiment(text):
score = sia.polarity_scores(text)['compound']
if score > 0.05:
return 'Positive'
elif score < -0.05:
return 'Negative'
else:
return 'Neutral'
df_cleaned['sentiment'] = df_cleaned['cleaned_tweet'].apply(categorize_sentiment)
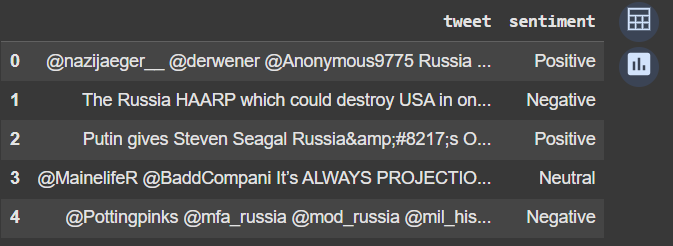
df_cleaned[['tweet', 'sentiment']].head()
Output:
6. Model Training and Evaluation
We will prepare the data for model training, trains a Naive Bayes classifier and evaluates its performance.
train_test_split(X, y): Splits the data into training and testing sets.TfidfVectorizer(max_features=5000): Converts the text data into numerical features using TF-IDF (with a limit of 5000 features).classifier.fit(X_train_tfidf, y_train): Trains the Naive Bayes classifier on the training data.accuracy_score(y_test, y_pred): Calculates the accuracy of the classifier on the test data.classification_report(y_test, y_pred): Generates a detailed classification report including precision, recall, and F1-score.
X = df_cleaned['cleaned_tweet']
y = df_cleaned['sentiment']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
vectorizer = TfidfVectorizer(max_features=5000)
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
classifier = MultinomialNB()
classifier.fit(X_train_tfidf, y_train)
y_pred = classifier.predict(X_test_tfidf)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:")
print(report)
Output:
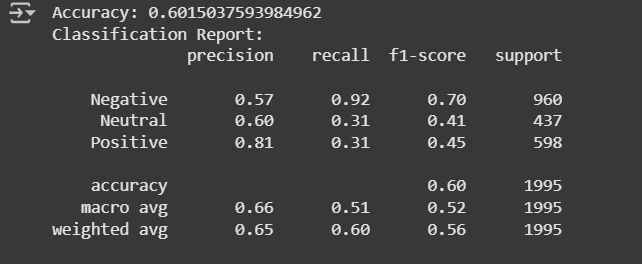
Model has an accuracy of 60.15%. It performs well in detecting Negative tweets (high recall) but struggles with Neutral and Positive tweets (low recall). Precision for Positive tweets is high, but recall is low, meaning many positive tweets are missed. Wed can further fine tune it.
7. Classifying New Tweets
def classify_new_tweet(tweet):
cleaned_tweet = alternative_preprocess_text(tweet)
tweet_tfidf = vectorizer.transform([cleaned_tweet])
sentiment = classifier.predict(tweet_tfidf)[0]
return sentiment
new_tweet = "War should stop now"
print(f"Sentiment of the new tweet: {classify_new_tweet(new_tweet)}")
Output:
Sentiment of the new tweet: Positive
We can see that our model is working fine.
Sentiment analysis offers valuable insights into understanding public opinion and emotions from text data. By using machine learning techniques we can effectively classify sentiments expressed in tweets or other social media content. While the current model provides a strong foundation continuous improvements and exploration of more advanced methods will enhance its ability to accurately classify sentiments across diverse contexts making it a powerful tool for various applications including social media monitoring, customer feedback analysis and brand sentiment tracking.