Cosine similarity measures the similarity between two non-zero vectors by calculating the cosine of the angle between them. It is widely used in machine learning and data analysis, especially in text analysis, document comparison, search queries, and recommendation systems.
- Similarity measure calculates the distance between data objects based on their feature dimensions in a dataset.
- A smaller distance indicates a higher similarity, while a larger distance indicates a lower similarity.
Cosine similarity is a metric, helpful in determining, how similar the data objects are irrespective of their size. We can measure the similarity between two sentences in Python using Cosine Similarity. In cosine similarity, data objects in a dataset are treated as a vector.
The formula to find the cosine similarity between two vectors is -
S_C (x, y) = x . y / ||x||\times ||y||
where,
- x . y = product (dot) of the vectors 'x' and 'y'.
- ||x|| and ||y|| = length (magnitude) of the two vectors 'x' and 'y'.
- ||x||
\times ||y|| = regular product of the two vectors 'x' and 'y'.
Example
Consider an example to find the similarity between two vectors - 'x' and 'y', using Cosine Similarity. The 'x' vector has values, x = { 3, 2, 0, 5 } The 'y' vector has values, y = { 1, 0, 0, 0 } The formula for calculating the cosine similarity is :
x . y = 3*1 + 2*0 + 0*0 + 5*0 = 3
||x|| = √ (3)^2 + (2)^2 + (0)^2 + (5)^2 = 6.16
||y|| = √ (1)^2 + (0)^2 + (0)^2 + (0)^2 = 1
∴S_C (x, y) = 3 / (6.16 * 1) = 0.49
The dissimilarity between the two vectors 'x' and 'y' is given by -
∴
D_C (x, y) = 1 -S_C (x, y) = 1 - 0.49 = 0.51
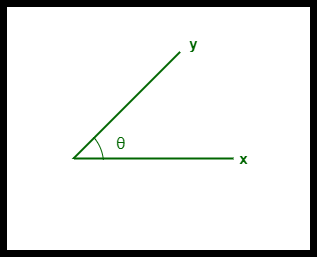
- The cosine similarity between two vectors is measured in 'θ'.
- If θ = 0°, the 'x' and 'y' vectors overlap, thus proving they are similar.
- If θ = 90°, the 'x' and 'y' vectors are dissimilar.
Some of the popular similarity measures are given below:
- Euclidean Distance
- Manhattan Distance
- Jaccard Similarity
- Minkowski Distance
- Cosine Similarity
Advantages
- The cosine similarity is beneficial because even if the two similar data objects are far apart by the Euclidean distance because of the size, they could still have a smaller angle between them. Smaller the angle, higher the similarity.
- When plotted on a multi-dimensional space, the cosine similarity captures the orientation (the angle) of the data objects and not the magnitude.
Disadvantages
- Sensitive to Sparse Data: Ineffective for sparse data with many zero components; other similarity measures may work better.
- Ignores Magnitude: Considers only the angle between vectors, missing differences in magnitude.
- Symmetric: Cannot distinguish the order of comparison, which may be undesirable in some tasks.