RankLLM is an advanced reranking framework designed to improve the relevance and accuracy of retrieval-augmented generation (RAG) systems. When integrated with LangChain, it allows large language models (LLMs) to not only retrieve context but also intelligently reorder (rerank) documents based on semantic similarity, coherence and contextual fit to the query. This ensures that the top-ranked documents are the most meaningful for the model’s reasoning and final answer generation.
- It enhances retrieval accuracy in LangChain-based workflows.
- Operates using listwise ranking with either large language models or cross-encoders.
- Integrates smoothly with FAISS, ChromaDB and other vector stores.
- Supports multiple reranking backends like HuggingFace and OpenAI/Gemini.
- Commonly used to boost RAG quality in question answering, chatbots and document retrieval tasks.
Implementation
Step 1: Install dependencies
We will install necessary packages for vector storage, embeddings and reranking.
!pip install langchain-community faiss-cpu sentence-transformers cohere pandas transformers
Step 2: Import Libraries
We need to import the required libraries such as langchain community, pandas, pipeline.
from langchain_community.vectorstores import FAISS
from langchain_community.docstore.document import Document
from langchain.embeddings import HuggingFaceEmbeddings
from sentence_transformers import CrossEncoder
from transformers import pipeline
import pandas as pd, random
Step 3: Add the Documents
We will be using sample documents here which can be replaced by real documents as per our need.
docs = [
Document(page_content="Deep learning enables neural networks to analyze complex data like images and speech."),
Document(page_content="Applications of deep learning include NLP, robotics, and medical imaging."),
Document(page_content="Convolutional networks are used for image recognition and computer vision tasks."),
Document(page_content="Recurrent neural networks are suitable for sequential data like text or time series."),
Document(page_content="Transformers like BERT and GPT revolutionized NLP with self-attention mechanisms."),
Document(page_content="Deep learning improves automation, prediction, and optimization in various industries."),
Document(page_content="Unsupervised deep learning discovers hidden data patterns without labels."),
Document(page_content="AI systems powered by deep learning can outperform humans in many cognitive tasks."),
Document(page_content="Optimization algorithms like Adam and SGD help train deep neural networks efficiently."),
Document(page_content="Deep learning models require large datasets and GPU power for effective training."),
]
Step 4: Initialize FAISS Vector Store
- The embedding model converts each document into a dense vector.
- FAISS stores these vectors for quick similarity-based retrieval.
- HuggingFace embeddings are lightweight yet semantically rich.
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = FAISS.from_documents(docs, embeddings)
Output:
Step 5: Retrieve Top Documents for a Query
Retrieves the top 10 most similar documents from FAISS using cosine similarity. The retrieved results are still “unordered” in terms of deep relevance.
query = "What are real-world applications of deep learning?"
retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
retrieved_docs = retriever.get_relevant_documents(query)
Step 6: Apply Reranker
Here,
- The CrossEncoder model evaluates each (query, document) pair directly.
- It outputs a relevance score, capturing semantic alignment between query and content.
- The model "ms-marco-MiniLM-L-6-v2" is trained for reranking and performs efficiently on CPUs/GPUs.
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
pairs = [(query, doc.page_content) for doc in retrieved_docs]
scores = reranker.predict(pairs)
Output:
Step 7: Rank and Display Results
Now,
- Combine retrieved docs with their relevance scores.
- Sorts them in descending order of semantic similarity.
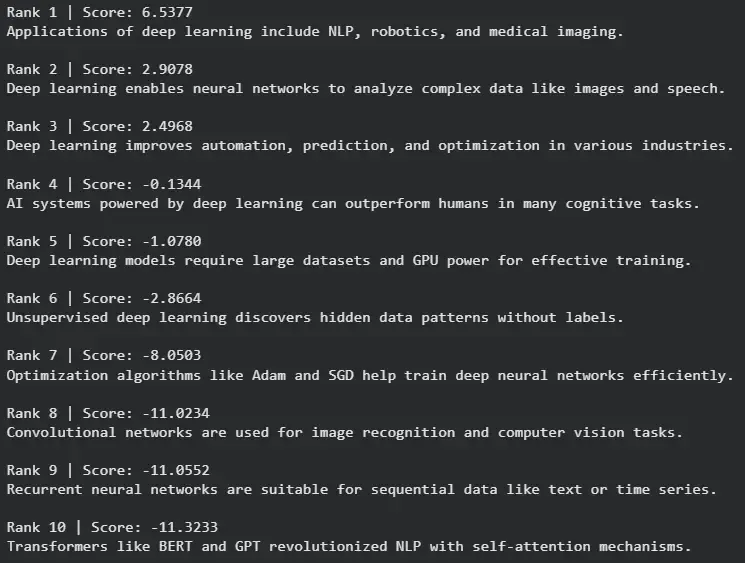
- Displays the reranked results, where Rank 1 is the most relevant.
results = list(zip(scores, retrieved_docs))
results.sort(key=lambda x: x[0], reverse=True)
for i, (score, doc) in enumerate(results, 1):
print(f"Rank {i} | Score: {score:.4f}\n{doc.page_content}\n")
Output:
Step 8: Summarization of Top Results
Here the model,
- Collects the top 3 ranked documents.
- Uses a summarization model (BART-large-CNN) to generate a concise summary.
- This mimics how RAG pipelines condense the most relevant context before final generation.
top_texts = " ".join([doc.page_content for _, doc in results[:3]])
summary_prompt = f"Summarize the key idea of these top documents:\n{top_texts}"
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
summary = summarizer(summary_prompt, max_length=100,
min_length=30, do_sample=False)[0]['summary_text']
print("\n--- Summary of Top Results ---")
print(summary)
Output:
--- Summary of Top Results ---
Deep learning enables neural networks to analyze complex data like images and speech. Deep learning improves automation, prediction, and optimization in various industries. Applications of deep learning include NLP, robotics, and medical imaging.
Source code can be downloaded from here.
Applications
- Retrieval-Augmented Generation (RAG): Improves the relevance of context fed to LLMs in QA systems.
- Search Engines: Enhances ranking of search results beyond keyword matching.
- Document Intelligence: Boosts accuracy in corporate document retrieval or compliance tools.
- Chatbots: Provides more meaningful answers by selecting the most contextually correct sources.
- Academic & Legal Research: Ensures the most relevant citations and case laws are prioritized.
Advantages
- Higher Accuracy: Improves retrieval precision by reordering documents based on LLM understanding.
- Plug-and-Play with LangChain: Easy integration with FAISS, ChromaDB or Pinecone.
- Model-Agnostic: Works with HuggingFace, OpenAI, Gemini or Cohere rerankers.
- Efficient: Cross-encoder rerankers provide strong performance even on moderate hardware.
- Customizable: We can fine-tune the reranker or switch models for domain-specific use.
Limitations
- High computational cost: Large reranker models require significant GPU memory and processing power.
- Latency overhead: The reranking step adds extra inference time, slowing down response generation.
- Limited scalability: Performance drops as the number of candidate documents increases.
- Dependence on pretrained models: Accuracy and relevance rely heavily on the quality and domain fit of the underlying model.