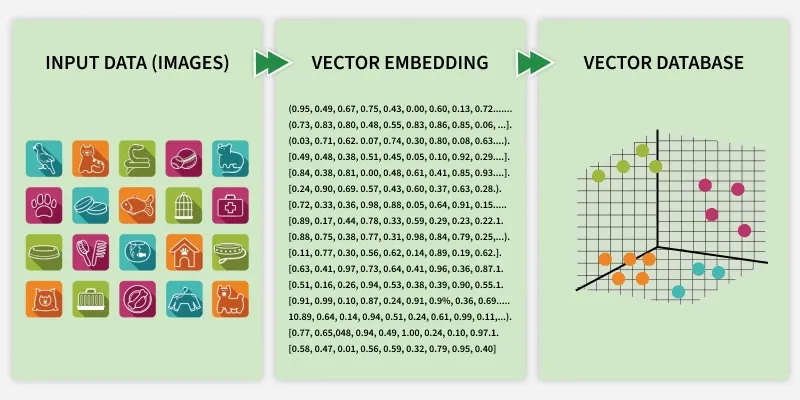
Milvus is an open-source vector database designed for managing and searching large-scale embedding data efficiently. It is widely used in AI, machine learning and semantic search applications where similarity search and retrieval play a key role.
Key Features
- Scalability: Supports a distributed architecture capable of handling billions of vectors.
- Multiple Index Types: Integrates advanced similarity search algorithms like IVF, HNSW and ANNOY.
- Hybrid Search: Combines vector search with scalar filters (metadata).
- Multi-Modality: Works with embeddings from text, audio, video and images.
- Multiple Language Support: It provides APIs for Python, Java and REST, making it easy to use in production systems.
Architecture
Milvus’s architecture is modular and distributed. It consists of several components:
- Proxy: Manages requests from clients and handles authentication.
- Coordinator: Controls query, data and index nodes ensuring consistency.
- Data Node: Handles insert and delete operations.
- Index Node: Builds and manages vector indexes.
- Query Node: Executes search and retrieval operations.
- Storage Layer: Uses object storage like MinIO or AWS S3 for persistent data.
Implementation of Milvus
Step 1: Install Dependencies
We will install the required dependencies,
!pip install pymilvus==2.4.5
Step 2: Connect to Milvus
We will connect to Milvus Lite:
- Uses Milvus Lite which stores data in a local file (milvus.db) in Colab.
- No need to specify host or port, the database runs embedded in our notebook.
from pymilvus import connections
connections.connect("default", uri="milvus.db")
print("Connected to Milvus Lite")
Output:
Connected to Milvus Lite
Step 3: Create Collection
Defines a collection like a table with an auto-generated primary key (id) and a vector field (embedding). The vector field dimension (dim=128) must match our embedding size.
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
fields = [
FieldSchema(name="id", dtype=DataType.INT64,
is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, description="Demo vector collection")
collection = Collection(name="demo_collection", schema=schema)
print("Collection created successfully")
Output:
Collection created successfully
Step 4: Insert Sample Data
Creates synthetic vector data for demonstration. Each row is a 128-dimensional vector, typical for embeddings (e.g., sentence or image embeddings).
import numpy as np
vectors = np.random.random((100, 128)).astype(np.float32)
collection.insert([vectors])
print("Inserted 100 vectors")
Output:
Inserted 100 vectors
Step 5: Create an Index for Faster Search
Here:
- Indexes accelerate vector search by clustering data.
- IVF_FLAT is a fast and commonly used algorithm for approximate nearest neighbor (ANN) search.
index_params = {
"metric_type": "L2",
"noindex_type": "IVF_FLAT",
"params": {"nlist": 64}
}
collection.create_index(
field_name="embedding",
index_params=index_params
)
print("Index created successfully")
Output:
Index created successfully
Step 6: Load Collection and Perform a Search
Here:
- Loads the collection into memory before searching.
- Searches for the top 5 most similar vectors using L2 distance.
- Prints the IDs and their similarity scores (lower = more similar for L2).
collection.load()
query_vector = np.random.random((1, 128)).astype(np.float32)
results = collection.search(
data=query_vector,
anns_field="embedding",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=5,
output_fields=["id"]
)
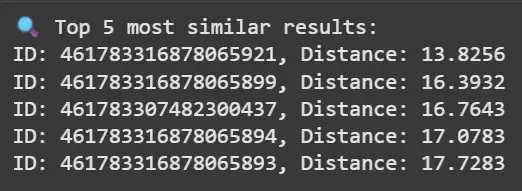
print("🔍 Top 5 most similar results:")
for res in results[0]:
print(f"ID: {res.id}, Distance: {res.distance:.4f}")
Output:
Milvus vs. Other Vector Databases
Let's compare milvus with other vector databases,
| Feature / Database | Milvus | Pinecone | Weaviate | Chroma | FAISS |
|---|---|---|---|---|---|
| Open Source | Yes | No | Yes | Yes | Yes |
| Scalability | High (distributed) | Very High (managed cloud) | High | Moderate | Limited |
| Index Types | IVF, HNSW, ANNOY, DiskANN | Proprietary | HNSW | HNSW | IVF, Flat |
| Hybrid Search | Yes | Yes | Yes | No | No |
| Metadata Filtering | Yes | Yes | Yes | Yes | No |
| Deployment Options | On-prem / Cloud | Cloud only | Both | Local | Local |
| Integration with ML Tools | Excellent (LangChain, PyMilvus) | Moderate | Excellent | Good | Good |
| Best For | Production-grade AI systems | Enterprise SaaS | Semantic search | Lightweight RAG setups | Research and offline search |
Use Cases
- Semantic Search: Enables similarity search over text embeddings from models like OpenAI, Cohere or SentenceTransformers.
- Recommendation Systems: Matches user embeddings to item embeddings for personalized recommendations.
- Image & Video Retrieval: Finds visually similar content using feature embeddings from CNNs or CLIP models.
- Anomaly Detection: Identifies unusual data points in high-dimensional feature space.
- Generative AI & RAG Systems: Integrates with LangChain, LlamaIndex and LLMs for embedding-based retrieval augmentation.
Advantages
- Open Source and Community-Driven: Regular updates and strong community support.
- Scalable and Distributed: Handles billions of vectors across nodes.
- High Performance: Millisecond-level query latency with optimized indexing.
- Flexible Indexing: Supports multiple ANN algorithms for trade-offs between speed and accuracy.
- Hybrid Search: Combines metadata and vector search seamlessly.
- Rich Ecosystem: Integrates easily with AI frameworks like TensorFlow, PyTorch and LangChain.
Limitations
- Operational Overhead: Requires setup and management of multiple components in production.
- Resource Intensive: High memory and storage requirements for very large datasets.
- Index Tuning Needed: Performance depends on careful tuning of index parameters.
- Learning Curve: Understanding architecture and optimizing search performance may take time.