
Planet Python
Last update: June 29, 2026 07:47 PM UTC
June 29, 2026
Mike Driscoll
Python eBook and Course Summer Sale
It’s officially summer, and I am bringing you some HOT Python deals today! Get 33% off almost all my books and courses on Gumroad today using the following H5N5F7K
You can start learning the basics of Python with Python 101, or get more targeted learning with my book, Python Logging. If you want to create a user interface, then you might enjoy Creating TUI Applications with Textual and Python.
I have over a DOZEN Python books to choose from! Check them out today: https://driscollis.gumroad.com/
Plus even more that aren’t pictured here!
The post Python eBook and Course Summer Sale appeared first on Mouse Vs Python.
Python Software Foundation
Packaging Council Inaugural Election Dates
With the recent approval of PEP 772 – Packaging Council governance process, a new Python Packaging Council (PPC) is being established with broad authority over packaging specifications and the mandate to coordinate Python packaging efforts. The election of the inaugural PPC will be held in parallel to the 2026 Python Software Foundation (PSF) Board election.
What is the Python Packaging Council?
The PPC will be the technical decision making body for the interoperability specifications affecting how Python packages are built, distributed, and installed.
The council will also serve as a coordinating body for the Python packaging ecosystem, working with many stakeholders from the wider Python community toward an ever-improving packaging user experience. This will include the maintainers of various packaging tools like the Python Packaging Authority (PyPA), the Python core team, the Python Steering Council, and the PSF.
Election Overview
The 2026 inaugural election fills all five seats on the PPC. The two candidates receiving the highest number of votes shall be designated Cohort A with a two-year term, and the three candidates receiving the next highest number of votes shall be designated Cohort B with a one-year term.
In future elections, each cohort will be elected for a full two-year term in alternating years, so that roughly half of the PPC turns over each cycle.
Election Timeline
The PPC election follows the same timeline as the PSF Board election:
Nominations open: Tuesday, July 28th, 2:00 pm UTC
Nomination cut-off: Tuesday, August 11th, 2:00 pm UTC
Announce candidates: Thursday, August 13th
Voter affirmation cut-off: Tuesday, August 25th, 2:00 pm UTC
Voting start date: Tuesday, September 1st, 2:00 pm UTC
Voting end date: Tuesday, September 15th, 2:00 pm UTC
Voting
You must be a Contributing, Supporting, or Fellow member by August 25th and affirm your intention to vote to participate in this election.
Check out the PSF membership page to learn more about membership classes and benefits. You can affirm your voting intention by following the steps in the PSF’s video tutorial:
Log in to psfmember.org
Choose “Your Memberships” page at the top right to check your eligibility to vote (You must be a Contributing, Supporting, or Fellow member)
Choose “Voting Affirmation” page at the top right
Select your preferred intention for voting in 2026 (which now includes a second affirmation regarding your intention to vote in the PPC election)
Click the “Submit” button
Like the PSF Board elections, casting a vote in a PPC election will automatically affirm your intention to participate in the next PPC election.
If you have questions about membership, please email pc-elections@python.org.
Election communications from psfmember.org
PSF Members should review their communication preferences on psfmember.org if you would like to opt in or out of receiving emails about the PSF Board, PPC elections, or both. Here’s how:
Log in to psfmember.org
Navigate to your “Profile” page
Click the “Name and Address” tab
Scroll down, designate your preferences
Click submit
If you had previously opted out of communications from the PSF through psfmember.org and would like to review or change your preference, we encourage you to update them using the instructions above. The PSF only sends a handful of election and fundraising related communications every year via psfmember.org.
Running for the Packaging Council
Do you have a vision for improving the Python packaging experience? Do you make the tools used to build and consume Python packages? Are you passionate about building communities, consensus, and standards focused on the user experience? If these resonate with you, and you have the time to attend regular meetings and participate in the standardization process, you should consider running for the inaugural PPC!
We're looking for candidates who can build bridges between projects and communities, who enjoy working with a very large community of passionate volunteers, and have a willingness to represent the wider community ahead of any single tool, project, or employer. We also welcome candidates who have a diverse set of skills and experiences, including open-governance experience, community stewardship, fundraising knowledge, and (of course!) technical expertise in Python packaging and distribution.
PEP 772 does provide non-binding operational suggestions, which hint at how the council could function. As this is the inaugural PPC, the individuals serving on it will be establishing the initial operating procedures, scope, interests, and agenda that future councils will build upon. Notably, "establishing specific processes for [the] Packaging Council and PyPA relationship" is something that the inaugural Packaging Council is expected to do.
You can nominate yourself or someone else. If you're nominating someone else, we'd encourage you to reach out to them first to make sure they're excited about the opportunity and give them a heads up that they'll need to submit their own nomination statement too. Nominations open on Tuesday, July 28th, 2:00 pm UTC, so you have time to talk with potential nominees, research the role, and craft a nomination statement for yourself or others. Remember, nominees must themselves be PSF voting members, and nomination statements must include information about the nominee’s relevant affiliations.
Seth Michael Larson
United Nations Open Source Week 2026
I was among the delegation of “open source experts” invited to the UN Open Source Week 2026 in New York City by the Sovereign Tech Agency. Thank you to the Sovereign Tech Agency for inviting and supporting my stay and travel for the event. Thanks to Alpha-Omega for sponsoring my position at the Python Software Foundation.
UN Open Source Week is a week-long event with a different focus for each day. In order, the focuses were: Maintain-a-thon (UN Tech Over), Open Source × AI, Digital Public Infrastructure Day, OSPOs for Good, and Community Day. The event is structured into a series of presentations, panels, parallel sessions, interactive break-outs that start in the morning and carry on through into the evening at local partnered events.
Themes
After speaking with many folks and attending a week of sessions, there were themes that carried through the entirety of the event:
- Power, resources, and talent around LLM technologies are currently concentrated into the control and geographical borders of few. Many countries and organizations are struggling with access to these technologies. A substantial portion of the answer is Open Source software and models of various definitions, but compute and talent are more difficult problems. Better efficiencies, distributed training and inference, sharing compute resources, and programs to transfer skills to other communities were among discussed solutions.
- LLMs are changing many of the social norms for Open Source participation which disrupts processes that have been in place for decades. Upstream and downstream processes will need to be developed to handle these changes.
- There were acknowledgements that many people were on edge or scared, that the metaphorical “tomorrow” was less clear to see than it was a few years ago.
There was also plenty of hope in the sessions, too. Similar to last year, I left feeling that Open Source was a critical component for overcoming the challenges ahead and that organizations around the world knew this acutely.
Multiple speakers asked those involved with Open Source projects to see how their projects aligned with the 17 Sustainable Development Goals, including quality education, clean energy, industry and infrastructure, and many more. Having done this exercise, I highly recommend others do so, too.
Maintain-a-thon 2.0
The Sovereign Tech Agency was the partner hosting the second “Maintain-a-thon” as a part of the first day of UN Open Source Week. This year the day was split into two parallel tracks: “Technical Maintenance” and “Capacity & Stewardship”.

Giving context for LLMs and vulnerability reports for the Python programming language.
Mirko Swillus and I hosted a session in the Technical Maintenance track titled “The Vulnerability Flood: Open Source Security in the Age of LLMs”. The session would discuss how LLMs were affecting vulnerability handling and security teams and how we might better plan for potential futures. We began the session by setting context around how LLMs were already changing security, such as:
- publicly available models are able to discover vulnerabilities.
- LLMs can detect whether patches are security-relevant, regardless of whether an advisory is published (embargoes are less useful).
- time-to-exploit for vulnerabilities is decreasing.
- “AI slop” vulnerability reports and how in recent months quality has improved.
- how projects like the Python programming language are thinking today about “steering” these LLM-assisted contributions in a positive direction through security policies and threat models.
The session proceeded into an interactive exercise to draw potential topics for deeper small-group discussions from participants using sticky notes. The three topic-clusters ended up being “People”, “Process”, and unsurprisingly “AI”.
The “People” group discussed offering mental health programs for Open Source maintainers to better handle stress, burnout, and succession planning and highlighted the difficulties in defining what it even means to be a maintainer in terms of a “job description”.
The “AI” group discussed the critical junction for handling unmaintained software in a world of agents and faster time-to-exploits, focusing on the question: “Fix or rewrite?”. Clearly rewrites should be a last-resort and are fraught with challenges, such as introducing more bugs and security issues due to a large volume of new code. The group highlighted challenges and potential solutions around LLM use for Open Source projects in handling the flood of security reports.
The “Process” group discussed the weakening value of secrecy when it comes to vulnerability reports discovered using LLMs. Historically secrecy was kept to protect users, but if public models are able to find issues then who does this aspect of coordinated-vulnerability disclosure actually help? (Attackers). The Linux kernel is already experimenting with having less secrecy involved in vulnerability handling.
Notes from the AI group Small python dep that keeps getting reports, is there a point where it should get rebuilt (with AI), rewrite it in rust for memory safety, identify the jenga block Is it so bad that it needs a complete overhaul, how is the architecture? (pre-ai assumption) Programme Bench (ai benchmark, does an ai rewrite something reliably) Depends on the size of the project, often 90% isn’t used What happens when there are no maintainers? Is the project well maintained enough? Does it have governance model that lets ai take over? We’ve seen ai rewrites that also change licenses at the same time When you make something from the ground up you learn it better, if you take something over, learning all the edge cases can be more work that rewriting from scratch. In any case, whoever takes over, new maintainers have to learn the edge cases and understanding. You could feed all git history into a model to ensure it learns all the failures and fixes over time. If we believe that AI is good enough to do an AI rewrite properly Rewrites are hard, introduces more problems that were there anymore Project moved in a direction from paid hosted models to free self hosted models, dealing with resource constraints. Easier to pitch AI projects from an ethics POV if it’s using self-hosted “open source” ai models. Feels better and better perceived about using “open source” models, but worried about how it scales. Choosing to engage with AI can cross red lines with committers and users that causes lots of issues. Pitching OSS projects as “AI powered” often upsets users. Getting users past “it has AI in the name” Resource constraints can make it needed to use AI because there are no people and no funding, locally run ai powered approaches come across more reasonably. Humanitarian sectors are slow to adopt this technology and generally slower moving in general. Airflow - Big open source projects - big number of incoming requests, hard to tell if incoming is human or agents. Processing issue trackers using AIs, ensuring things are triage and keeping them up to date. More process == more overhead. Having experienced developers looking at the triage process rather than the initial untrusted issues. Reducing the friction of adoption of AI - generation vs assistive Calling “ai” things - Machine learning to be clear if it’s generative llms. Can fix faster be useful for accessibility of using software where there user previously never had any software experience
Notes from the People group Mental Health Programme for FOSS Maintainers How do we create awareness, so that people sign up for this? Outspoken and explicit “Job Descriptions” for single maintainers so that is easier to understand which functions can be trained and educated Clear path for becoming a mentor Sunsetting Projects Support structures for sunsetting projects & find replacements Ment or Students Learn from best practices (french DINUM, 2-3 years)
Open Source × AI Day Reception
At the reception for Open Source × AI Day there was an additional panel session focusing on LLMs and security. One of the most interesting talking points of this panel was the restrictions being placed on “Frontier” models with cybersecurity capabilities. Earlier in the week, GLM-5.2, an open weights model had been released and folks already had begun testing the model’s cybersecurity capabilities and found them to be already quite capable.
The panel noted how open weights models appear to be fast-following “Frontier” capabilities with a delay between 6-12 months, implying that we may not need to wait long for an open weights model with Mythos-like capabilities to become available. This is based on speculation, but there are many implications for this are... interesting, to put it lightly. :)
Thanks for reading ♥ I would love to hear your thoughts! Contact me via Mastodon, Bluesky, or email. Browse the blog archive. Check out my blogroll.
June 28, 2026
"Michael Kennedy's Thoughts on Technology"
What the pls?
tl;dr; The pls package on PyPI is an abandoned Python version (last released as v6.0.0 in 2023). The actively-developed pls was rewritten in Rust and now lives at pls-rs/pls. If you installed it with uv tool install pls or pipx install pls, you have the wrong one. Uninstall it and install the Rust build instead (e.g. brew install pls-rs/pls/pls).
You may have heard me sing the praises of pls. I really love the icons and colors to disambiguate files and provide more information about them, the developer workflow, and more. Here’s an example in the Warp terminal for my jinja-partials package.

But installing and managing this package is weird and kinda deceiving to say the least. pls was originally pure Python (up to v6.0.0 in 2023). It’s listed on PyPI here. So it looks like that is just the latest, right? After all, if it was rewritten in Rust, it can still be installed via PyPI and in particular, via uv tool install pls.
But no.
There are a few funky things about the PyPI listing that give it away:
- The homepage 404s. The homepage link on the PyPI page goes nowhere. A bit sus.
- The GitHub repo is a silent redirect. The repo seems alive, but the link https://github.com/dhruvkb/pls silently redirects to https://github.com/pls-rs/pls. Clicking the link in PyPI seems to reference the Rust/latest version. But this happens only because GitHub does the redirect.
How do I install the correct, Rust-based pls?
To get the actively-developed version, don’t let PyPI fool you. There are two steps:
- Uninstall the Python version if you installed it via Python:
uv tool uninstall pls(orpipx uninstall pls). - Then install the Rust version directly. I use Homebrew, so it’s
brew install pls-rs/pls/pls. See their getting started page for the option that works best for you.
Should you switch from the PyPI version of pls?
Yes - if you installed it with a Python tool, switch to the Rust version. Normally, I’d just chalk this up to standard package / open source drift and carry on with my life. But I’ve recommended pls to enough people that I feel I should call a bit of attention here. So if you’re using pls and you used Python tools to install it, like uv, uninstall that version and jump over to the Rust-based one.
Python Insider
Packaging Council Inaugural Election Dates
A new Python Packaging Council (PPC) is being established, with their election of the inaugural PPC will be held in parallel to the 2026 PSF Board election.
June 27, 2026
Go Deh
Sparse Ranges
Implementing sparse_range: From a Python Discuss Idea to a Sieve Stress Test
I found an interesting thread over on the Python Discuss forum titled "Possibility to exclude ranges from range". The initial discussion revolved around a common (?), developer need of : how to cleanly skip specific blocks of ints in a range of ints without writing clunky, nested if/continue logic, and without doing something memory-heavy like casting everything into a massive set.
The consensus was that Python's native range is beautiful because it’s a lightweight, memory-efficient arithmetic engine. It doesn't store numbers in RAM; it just calculates them on the fly. But the moment you need to punch holes in it—say, "give me all numbers from 1 to 1000, except for multiples of 5, and except for the block from 200 to 300"—you lose that structural elegance.
This inspired me to build a clean, production-grade abstraction to solve this kind of thng: sparse_range.
The Architectural Concept
The core idea began with a simple mathematical definition: a Sparse range instance is created by a set of (python) ranges S_in that hold possible output values and a set of ranges S_ex that exclude possible output values. A Sparse_range instance can be called with a start, stop, and step argument that generate trial output candidates that are checked against S_in and S_ex to see if they are allowed/filtered. An item is eligible for the final output if its value is present in at least one of our permitted baseline ranges S_in, unless that value happens to be intercepted by one of our forbidden exclusion ranges S_ex. On top of that structure, the outer sparse_range wrapper behaves like a native Python range—it accepts its own outer start, stop, and step constraints, matching the target window requested by the user.
To make the evaluation stateless and fast(?), the engine must evaluate values on the fly. However, native Python range objects are immutable and opaque; they don't natively maintain operational iteration states, nor do they know how to coordinate with one another.
To bridge this gap, the engine internally upgrades every raw Python range passed to collections S_in and S_ex into custom RangePointers.
Why We Need RangePointer and Direction Alignment
When the outer loop steps through values, the internal component ranges must follow along. If the outer loop is counting upwards (step > 0), all internal evaluation cursors must track upwards. If the outer loop reverses direction and counts downwards (step < 0), every single internal range must generate the same values, but in the reverse order, and without using up extra memory for storing values.
If they don't match directions, the leapfrogging logic breaks. A forward-running pointer cannot efficiently tell a backward-running outer loop where the next valid alignment boundary is without wasting CPU cycles scanning dead space or whatever.
Therefore, when a sparse_range instance is invoked, the engine inspects the outer step direction and enforces a unified traversal direction across every single internal S_in and S_ex sequence. If an internal range's native direction opposes the outer loop, it must be completely mathematically inverted.
The Range Reversal Formula
Reversing an arithmetic progression isn't as simple as swapping the start and stop boundaries. Because Python ranges stop before reaching the termination boundary, reversing a range requires recalculating its new alignment based on its exact step constraints.
To reverse a range mathematically, the engine computes:
New Step: The step sign is flipped (
-step).New Start: The final valid item generated by the original range becomes the new starting point. This is computed using the remainder of the length of the sequence:
new_start = start + (length - 1) × stepNew Stop: The original
startboundary shifts out by one step inverted to act as the non-inclusive terminal wall:new_stop = start - step
By normalizing all RangePointer instances to track in the exact same direction as the outer loop, the engine can efficiently step through candidate numbers, skipping blocks of excluded data in O(1) or O(K) time (where K is the number of active ranges), keeping the memory footprint at absolute zero.
The code
sparse_range.py
A run of included tests
Running Factory Pattern Limits Verification Suite (-1000 to +1000)...
✅ PASS: Standard positive crawl -> args: (0, 200, 2)
✅ PASS: Negative direction crawl -> args: (400, -400, -5)
✅ PASS: Large step slice jump -> args: (-1000, 1000, 25)
✅ PASS: Completely out of bounds window -> args: (600, 900, 1)
✅ PASS: Empty S_in Edge Case -> args: (0, 50, 1)
Test Summary: 5/5 passed successfully.
The Ultimate Stress Test: A Declarative Sieve
It's easy to write a basic range filter that skips a static block of numbers. But to prove that this RangePointer inversion and alignment math is completely airtight across dozens of concurrent boundaries, I decided to implement a completely declarative Sieve of Eratosthenes.
Instead of allocating a large mutable array of booleans in memory and procedurally striking out composites, we can use pure sequence logic:
The Permitted Range S_in: Our baseline pool of candidate of ints starting at 2:
[range(2, limit + 1)].The Exclusion ranges S_ex: A list of independent arithmetic progression ranges tracking the composites for every factor m up to √(limit).
Each exclusion range/stream starts at m × m (instead of m × 2). Any composite smaller than m × m has a prime factor smaller than m, meaning it has already been intercepted by an earlier stream. For example by the time m=5 runs, numbers like 10, 15, and 20 are already masked out by the ranges/streams for 2 and 3. The first unseen composite is 5 × 5 = 25.
Putting it to the Test
Although the module sparse_range.py has its own tests, to further verify the integrity of the design I put together a test module called sparse_range_sieve_test.py. It packages the sieve creation into an isolated factory function and validates the output against a traditional, trusted array sieve across both a forward sweep and a reversed backward pass.
The Verdict
When running forward, the generator's internal pointers march sequentially alongside the main consumer loop.
The true architectural challenge happens during the backward traversal pass (step = -1). When executing prime_sieve_factory(limit, 1, -1), the engine must manage 13 independent composite exclusion ranges simultaneously (for m = 2, 3, ..., 14). Each sub-range pointer must instantly compute its upper boundary, snap precisely to its maximum valid multiple less than or equal to 200, and step backward in perfect synchronization without dropping or skipping values.
The execution checks out perfectly:
Beginning Sparse Range Sieve Evaluation Suite (N = 200)...
----------------------------------------------------------------
👉 Running Forward Traversal Validation...
✅ PASS: Forward matching. Found 46 primes.
👉 Running Backward Traversal Validation...
✅ PASS: Backward matching. Reversed sequences match perfectly.
If you are following the Python Discuss thread, this demonstrates that handling arbitrary sequence exclusions cleanly and statelessly via pure index-pointer stream math isn't just an elegant idea—it's highly reliable even under heavy algorithmic stress.
Disclosure
I used Gemini AI to help in this. I was able to state algorithms and get Gemini to fill in with implementations, state changes and get Gemini to implement those too. I am used to creating algorithms without AI, this time I was able to state what I wanted in some detail and have Gemini add yet more detail. I could show python, pseudo-code, r textual descriptions as needed and get Gemini to fill in. The tests went from my description to code by Gemini - the sieve example test idea and spec, and debug was by me with Gemini improving my limit on m from m*2 to m*m for example before implementing as told.
June 26, 2026
Talk Python to Me
#553: All of our tools
This episode is a fun crossover from our Python news and tips podcast, Python Bytes. We have had some big changes over there. Brian Okken has moved on and Calvin Hendryx-Parker has joined the show as the new co-host. To kick off this new era, we decided to do a longer and more personal episode called "All Our Tools". The idea is both of us talk about some of our most useful day-to-day developer and business owner tools that we think you all would find useful. It was so well received, that I'm bringing it to you all as a crossover episode. Enjoy and we hope you find something new and awesome to help you with your software and data science day to day.<br/> <br/> <strong>Episode sponsors</strong><br/> <br/> <a href='https://talkpython.fm/sentry'>Sentry Error Monitoring, Code talkpython26</a><br> <a href='https://talkpython.fm/devopsbook'>Python in Production</a><br> <a href='https://talkpython.fm/training'>Talk Python Courses</a><br/> <br/> <h2 class="links-heading mb-4">Links from the show</h2> <div><strong>@calvinhp@sixfeetup.social</strong>: <a href="https://sixfeetup.social/@calvin?featured_on=talkpython" target="_blank" >sixfeetup.social</a><br/> <strong>@calvinhp.com</strong>: <a href="https://bsky.app/profile/calvinhp.com?featured_on=talkpython" target="_blank" >bsky.app</a><br/> <strong>calvinhp.com</strong>: <a href="https://calvinhp.com?featured_on=talkpython" target="_blank" >calvinhp.com</a><br/> <br/> <strong>Original airing on Python Bytes</strong>: <a href="https://pythonbytes.fm/episodes/show/484/all-our-tools?featured_on=talkpython" target="_blank" >pythonbytes.fm</a><br/> <br/> <strong>pi</strong>: <a href="https://pi.dev/?featured_on=talkpython" target="_blank" >pi.dev</a><br/> <strong>superpowers</strong>: <a href="https://github.com/obra/superpowers/tree/main?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Warp.dev</strong>: <a href="http://Warp.dev?featured_on=talkpython" target="_blank" >Warp.dev</a><br/> <strong>OhMyZSH</strong>: <a href="https://ohmyz.sh/?featured_on=talkpython" target="_blank" >ohmyz.sh</a><br/> <strong>Commandbookapp.com</strong>: <a href="http://Commandbookapp.com?featured_on=talkpython" target="_blank" >Commandbookapp.com</a><br/> <strong>Blink</strong>: <a href="https://blink.sh/?featured_on=talkpython" target="_blank" >blink.sh</a><br/> <strong>kitty</strong>: <a href="https://sw.kovidgoyal.net/kitty/?featured_on=talkpython" target="_blank" >sw.kovidgoyal.net</a><br/> <strong>mosh</strong>: <a href="https://mosh.org/?featured_on=talkpython" target="_blank" >mosh.org</a><br/> <strong>tmux</strong>: <a href="https://github.com/tmux/tmux?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Claude code</strong>: <a href="https://www.anthropic.com/product/claude-code?featured_on=talkpython" target="_blank" >www.anthropic.com</a><br/> <strong>Claude.md</strong>: <a href="http://Claude.md?featured_on=talkpython" target="_blank" >Claude.md</a><br/> <strong>MacWhisper</strong>: <a href="https://goodsnooze.gumroad.com/l/macwhisper?featured_on=talkpython" target="_blank" >goodsnooze.gumroad.com</a><br/> <strong>Handy</strong>: <a href="https://handy.computer?featured_on=talkpython" target="_blank" >handy.computer</a><br/> <strong>Tailscale</strong>: <a href="https://tailscale.com/?featured_on=talkpython" target="_blank" >tailscale.com</a><br/> <strong>Talk Python episode with Alex</strong>: <a href="https://talkpython.fm/episodes/show/546/self-hosting-apps-for-python-people" target="_blank" >talkpython.fm</a><br/> <strong>Telescopo</strong>: <a href="https://www.telescopo.app?featured_on=talkpython" target="_blank" >www.telescopo.app</a><br/> <strong>Typora markdown</strong>: <a href="https://typora.io/?featured_on=talkpython" target="_blank" >typora.io</a><br/> <strong>formal documentation for many of my open source packages</strong>: <a href="https://mkennedy.codes/docs/?featured_on=talkpython" target="_blank" >mkennedy.codes</a><br/> <strong>Great Docs</strong>: <a href="https://posit-dev.github.io/great-docs/?featured_on=talkpython" target="_blank" >posit-dev.github.io</a><br/> <strong>Statement on the US government directive to suspend access to Fable 5 and Mythos 5</strong>: <a href="https://www.anthropic.com/news/fable-mythos-access?featured_on=talkpython" target="_blank" >www.anthropic.com</a><br/> <strong>No second date</strong>: <a href="https://x.com/pr0grammerhum0r/status/2063078450311598430?s=12&featured_on=talkpython" target="_blank" >x.com</a><br/> <br/> <strong>Watch this episode on YouTube</strong>: <a href="https://www.youtube.com/watch?v=wgKF3yvpxPU" target="_blank" >youtube.com</a><br/> <strong>Episode #553 deep-dive</strong>: <a href="https://talkpython.fm/episodes/show/553/all-of-our-tools#takeaways-anchor" target="_blank" >talkpython.fm/553</a><br/> <strong>Episode transcripts</strong>: <a href="https://talkpython.fm/episodes/transcript/553/all-of-our-tools" target="_blank" >talkpython.fm</a><br/> <br/> <strong>Theme Song: Developer Rap</strong><br/> <strong>🥁 Served in a Flask 🎸</strong>: <a href="https://talkpython.fm/flasksong" target="_blank" >talkpython.fm/flasksong</a><br/> <br/> <strong>---== Don't be a stranger ==---</strong><br/> <strong>YouTube</strong>: <a href="https://talkpython.fm/youtube" target="_blank" ><i class="fa-brands fa-youtube"></i> youtube.com/@talkpython</a><br/> <br/> <strong>Bluesky</strong>: <a href="https://bsky.app/profile/talkpython.fm" target="_blank" >@talkpython.fm</a><br/> <strong>Mastodon</strong>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" ><i class="fa-brands fa-mastodon"></i> @talkpython@fosstodon.org</a><br/> <strong>X.com</strong>: <a href="https://x.com/talkpython" target="_blank" ><i class="fa-brands fa-twitter"></i> @talkpython</a><br/> <br/> <strong>Michael on Bluesky</strong>: <a href="https://bsky.app/profile/mkennedy.codes?featured_on=talkpython" target="_blank" >@mkennedy.codes</a><br/> <strong>Michael on Mastodon</strong>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" ><i class="fa-brands fa-mastodon"></i> @mkennedy@fosstodon.org</a><br/> <strong>Michael on X.com</strong>: <a href="https://x.com/mkennedy?featured_on=talkpython" target="_blank" ><i class="fa-brands fa-twitter"></i> @mkennedy</a><br/></div>
The No Title® Tech Blog
Just updated - Optimize Images v2.1.0
Optimize Images 2.1.0 brings native WebP support, a generalized format-conversion system, on-demand image inspection with EXIF reporting, and a new in-memory API for working with image bytes directly. It is a focused, fully backwards-compatible step forward for the command-line tool and its public API.
Bob Belderbos
There Is No Magic: An AI Agent in 60 Lines of Python
Everybody talks about agents, and a lot of people assume they're some new kind of model. They aren't. An agent is a small amount of plumbing around an LLM you already understand. Let's build one from scratch in Python and see exactly what that plumbing is.
The formula
An agent is: Model + Instructions + Memory + Tools + Execution Loop.
Five parts. None of them is magic. The model is a brain in a jar: useful, fast, but stateless. It generates text; the code around it decides what to do with that text. That second half is the entire job and it's code we can reason about.
I made the same argument about the control layer being the real product. Here it is as a program.
Start with the model. A real one calls an LLM API; we use a fake one that satisfies the same interface:
from dataclasses import dataclass
from typing import Protocol
@dataclass(frozen=True)
class Say:
text: str
@dataclass(frozen=True)
class Call:
tool: str
arg: str
Reply = Say | Call
class Model(Protocol):
def respond(self, system: str, history: list[str]) -> Reply: ...The Model protocol has a single method, respond, which takes the system prompt and the conversation history and returns a Reply. It's a Protocol, so any object with a matching respond method counts as a Model, no inheritance required.
For this minimal agent, the Reply type captures the two actions we support: say something to the user, or call a tool with an argument. The model is free to return either one, and the agent will execute it. (Real models can also emit plans, ask clarifying questions, or request several tool calls at once; we keep it to two to stay legible.)
The agent's entire decision space is those two variants. The match in the loop below reads as a clean two-way branch, one case per reply, instead of a tangle of flags.
from dataclasses import dataclass, field
from typing import Callable
Tool = Callable[[str], str]
@dataclass
class Agent:
model: Model # 1. Model
system: str # 2. Instructions
history: list[str] = field(default_factory=list) # 3. Memory
tools: dict[str, Tool] = field(default_factory=dict) # 4. ToolsIn this example, a tool is a function taking a string and returning a string. The agent holds the other four parts as plain fields:
- The model is any object satisfying the
Modelprotocol: a fake model goes in for testing and a real one for production. - The system prompt is a string that tells the model what to do.
- The history is the agent's working memory: the conversation and tool outputs that get replayed back into the model. Real agents often add retrieval, summarization, or external state on top, because context windows are finite.
- The tools field is a mapping of tool names to functions that implement them.
The loop is the agent
The part that turns a well-instructed chatbot into something agent-like is the fifth piece: an execution loop that lets the model observe outcomes and decide what to do next. Observe, think, act, check, repeat. Greatly simplified, of course, but this is the piece that does the work.
Because the model is stateless, the agent must keep track of what happened and feed the history back into the model until the model decides the job is done.
def run(self, user_input: str) -> str:
self.history.append(f"user: {user_input}")
while True: # real agents cap the iterations; see termination guards below
match self.model.respond(self.system, self.history):
case Say(text):
self.history.append(f"agent: {text}")
return text
case Call(tool, arg):
fn = self.tools.get(tool)
result = fn(arg) if fn else f"no such tool: {tool}"
self.history.append(f"tool[{tool}]: {result}")
# loop again: the model sees the result and decides what's nextRead it as the cycle:
- Observe: append the input.
- Think: ask the model.
- Act: if it asked for a tool, run the tool.
- Check and repeat: feed the result back into the history and loop, so the model sees what happened and decides whether it needs another tool or can finally answer.
There is no separate "check" block in the code. The check happens implicitly when the loop restarts and calls respond again with the new history. That step is the one that matters, because a model has no native sense of when a job is finished, and nothing stops it from asking for one more tool forever. The loop keeps going until the model returns Say instead of Call.
To run the whole thing without an API key, swap in a fake model and a real tool:
from pathlib import Path
def read_file(path: str) -> str:
try:
return f"{len(Path(path).read_text())} bytes"
except OSError as e:
return f"error: {e}"
class FakeModel:
def respond(self, system: str, history: list[str]) -> Reply:
last = history[-1] if history else ""
if last.startswith("tool["):
return Say(f"Done: {last}")
if last.startswith("user: read "):
return Call("read_file", last.removeprefix("user: read ").strip())
return Say("I can read files. Try: read <path>")Wire it into a small main that builds the agent, reads a line, calls agent.run, and prints the reply:
def main() -> None:
agent = Agent(
model=FakeModel(),
system="You can read files.",
tools={"read_file": read_file},
)
while True:
try:
line = input("> ")
except EOFError:
break
print(agent.run(line.strip()))
if __name__ == "__main__":
main()Now you can talk to it with no API key. Run it with python agent.py and type at the prompt:
> read pyproject.toml
Done: tool[read_file]: 76 bytesThat one exchange is a complete agent loop: the model asked for a tool, the loop ran it, fed the byte count back, and the model wrapped up on the second pass. The main thing standing between it and a real one is replacing FakeModel.respond with an HTTP call that returns the same Reply.
The whole thing as one runnable file is here as a GitHub gist. Save it, run python agent.py, and type at the prompt.
What this earns you
Sure, this is a simplified example, and the hard parts are exactly what FakeModel stubs out: prompt design, retries, tool schemas, context compaction, error recovery, and termination guards that stop the loop when a model keeps hallucinating tools. But the core of an agent is 60 lines and easy to reason about. The engineering lives in the control layer around the model.
Build the loop by hand once and frameworks stop feeling magical. LangChain's agent executor, AutoGen's shared memory, a coding agent's plan mode are all variations on these same five parts: engineering tradeoffs, not magic.
Keep reading
- The control layer is the product
- How an AI expense agent is actually structured
- Building an AI Agent in 6 Weeks (and Finally Understanding How They Work)
June 25, 2026
Artem Golubin
Hexora v0.3: New features and improvements
Recently, I've improved my Python library, hexora. I wrote it to detect malicious Python code using static analysis.
In the new v.0.3.0 release, I've added new detections, and we now also use a simple machine learning model to analyze the whole file. The machine learning model uses code structure features, semantic features, and static code analysis to assess the entire Python file.
Although the model can detect malicious code without any detections coming from static analysis, its main use case is to filter false positives.
I've been testing it against newly published PyPI packages and it detects 2-10 new malicious packages each day.
Due to the number of published packages, before the machine learning model, I was getting around 5-10 false positives for 1[......]
Django Weblog
How the Django Software Foundation Became a CNA
Why the DSF pursued CNA status
Django has a long history of responsible security practices: a dedicated, private security mailing list, clear advisory policies, and predictable security releases. Even so, we relied on external organizations to assign CVE IDs (Common Vulnerabilities and Exposures). This sometimes introduced administrative delays and extra coordination overhead.
Becoming a CNA (CVE Numbering Authority) allows the DSF to:
- Assign CVEs ourselves for vulnerabilities in Django and selected community projects.
- Publish advisories more efficiently and in closer alignment with Django's established release workflow.
- Maintain strong independence in how Django handles security incidents.
The initial exploration
The process began with internal discussions within the DSF Board and Django Security Team. We evaluated:
- Whether our existing security process already met CNA expectations.
- Whether we had the organizational stability to take on long term responsibility for CVE assignment.
- The scope of projects we would cover.
- How to ensure we could meet the operational requirements without overloading volunteers and Django Fellows.
After confirming that our policies were mature and that the administrative workload would be manageable, we initiated the CNA application with MITRE.
Preparing the application
MITRE requires that new CNAs document their security processes and demonstrate that they can meet CNA obligations. Our preparation included:
-
Reviewing and updating the Django Security Policy.
-
Mapping our existing workflows to MITRE's CNA rules, including:
- How reports are received.
- How vulnerabilities are validated.
- How advisories are produced.
- How CVEs will be assigned and published.
-
Defining the scope of the CNA:
- Django itself as the core product.
- A small, clearly bounded set of related ecosystem projects.
-
Ensuring we had private communication channels and documented procedures for confidential handling.
-
Drafting the required procedural documentation for MITRE.
Most of the work here was not about creating new processes but about articulating long standing Django practices in the format MITRE expects.
Training and review
Once our initial documentation was accepted, MITRE scheduled us for CNA onboarding training. This covered:
- CNA rules and responsibilities.
- Required data fields for CVE Records.
- Expectations for coordination with reporters and downstream consumers.
- The publication workflow for CVE Records.
We also completed MITRE's required CNA onboarding exercises. As part of this process, we worked through sample security reports and demonstrated how we would determine CVE assignments, including cases where multiple CVEs may or may not be warranted for a single report.
Approval and onboarding
After MITRE approved our documentation, training, and exercise submissions, the DSF was formally granted CNA status. The announcements steps were:
- MITRE published our CNA scope on the official CNA directory.
- MITRE issued a press release.
- The DSF published a blog post announcing our new CNA status.
Lessons learned
A few procedural insights for other projects considering CNA status:
- If your project already has a mature and documented security process, becoming a CNA is mostly about formalizing what you already do.
- The documentation and validation steps take time. Most delays come from ensuring that all fields conform to the CVE schema. The whole process took about four months.
- The training is detailed and helpful. It clarifies exactly what CNAs are expected to produce and how CVE Records flow through the broader ecosystem.
- It is worth being explicit about scope early. Defining the boundary of responsibility reduces ambiguity later.
What changes for Django users
For most contributors and users, nothing changes. Django will continue to follow its established process for receiving reports, coordinating fixes, and publishing security releases.
The difference is that the DSF can now assign CVE IDs directly, which simplifies coordination and allows us to publish advisories with fewer external dependencies.
Acknowledgments
This work was led by Django Fellows Natalia Bidart and Jacob Walls, with support from the Django Security Team and the DSF Board. We are grateful to MITRE for their guidance during the onboarding process.
If you have questions about Django's CNA scope or security process, contact the Django Security Team.
PyCharm
Explicit Lazy Imports Are Coming to Python 3.15
A while ago at PyCon US 2026, I had the pleasure of listening to the Python Steering Council give updates about new features that are being added in Python 3.15. One that stood out was explicit lazy imports (via PEP 810), which defer module loading until first use. I am curious to see how this new feature works, and I want to benchmark its performance with PyCharm. Let’s take a look together.
Overview of explicit lazy imports
PEP 810 introduces an explicit syntax for lazy imports, allowing you to defer the loading and execution of modules until their attributes are actually accessed, unlike standard eager imports that execute immediately. This feature aims to significantly reduce startup latency and memory consumption. Explicitly marking modules as `lazy` can deliver substantial improvements in initial responsiveness and baseline resource usage in large-scale applications and command-line tools.
Because the implementation approach uses proxy objects within the module’s namespace instead of modifying Python’s fundamental dictionary structures, it preserves critical interpreter optimizations.
This mechanism defers both the finding and the loading of the module to maximize efficiency, especially in environments with high-latency filesystems. To manage potential side effects and ensure backward compatibility, the proposal includes global control flags and a transitional variable for progressive adoption across different Python versions.
In short, Python 3.15 will let you optimize application performance by significantly reducing startup latency and memory consumption, as the loading and execution of modules are deferred until their attributes are actually accessed.
Trying them out in Python 3.15.0b1
At the time this is being written, Python 3.15.0b1 is already out, so we can give this new feature a try. You can build it from source at the CPython GitHub repo, but since getting Python 3.15.0b1 is easy when using `uv` or `pyenv`, we will do that instead.
Make sure you have the latest version of `uv` or `pyenv`, and then download Python 3.15.0b1 via either of the following commands:
- `uv python install 3.15.0b1`
- `pyenv install 3.15.0b1`
After that, select the new interpreter in your project in PyCharm.
Now you will need to reinstall the dependencies for your project. You may have to build some of the libraries from source, as most of the libraries will not have a Python 3.15 wheel for download.
Profiling against normal imports
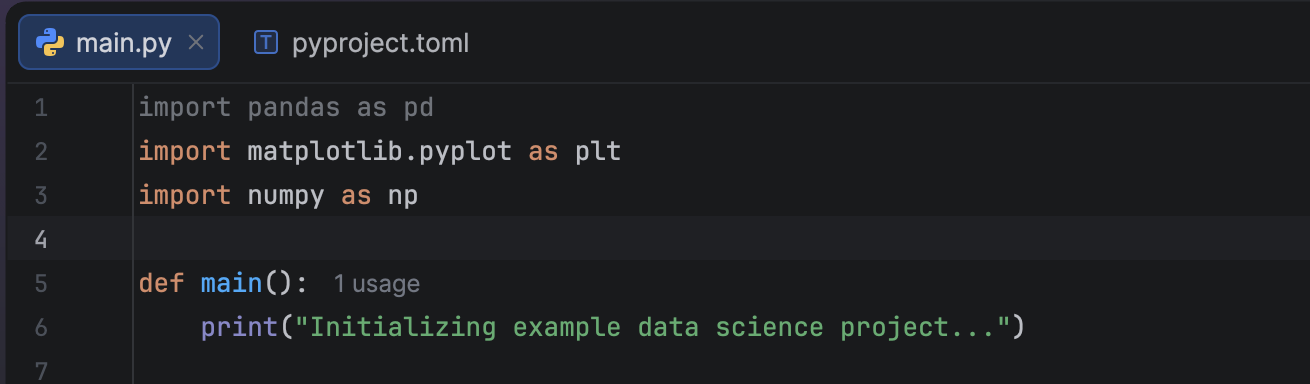
It is a common joke that the first thing data scientists will do is type `import pandas as pd` and `import numpy as np`, even if they are not actually going to use them. Let’s assume this is the case, and you received a script like this from your colleague:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def main():
print("Initializing example data science project...")
# Generate some dummy data
data = {
'x': np.linspace(0, 10, 100),
'y': np.sin(np.linspace(0, 10, 100)) + np.random.normal(0, 0.1, 100)
}
# Plotting
plt.figure(figsize=(10, 6))
plt.plot(data['x'], data['y'], label='Sine Wave with Noise')
plt.title('Sample Visualization')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.legend()
# Save the plot instead of showing it (since this is non-interactive)
plt.savefig('sine_wave.png')
print("Project executed successfully. Plot saved as sine_wave.png.")
if __name__ == "__main__":
main()
As you see, PyCharm highlights the unused pandas import for you, so removing it would be straightforward. However, for our experiment here, we’ll keep it.
To get a better visualization of import profiles, install a tool from PyPI called tuna.
You can profile your script by setting a custom run script with this script text:
python -X importtime main.py 2> import_log.txt; tuna import_log.txt
When you use it, a new browser window will pop up with the import graph.
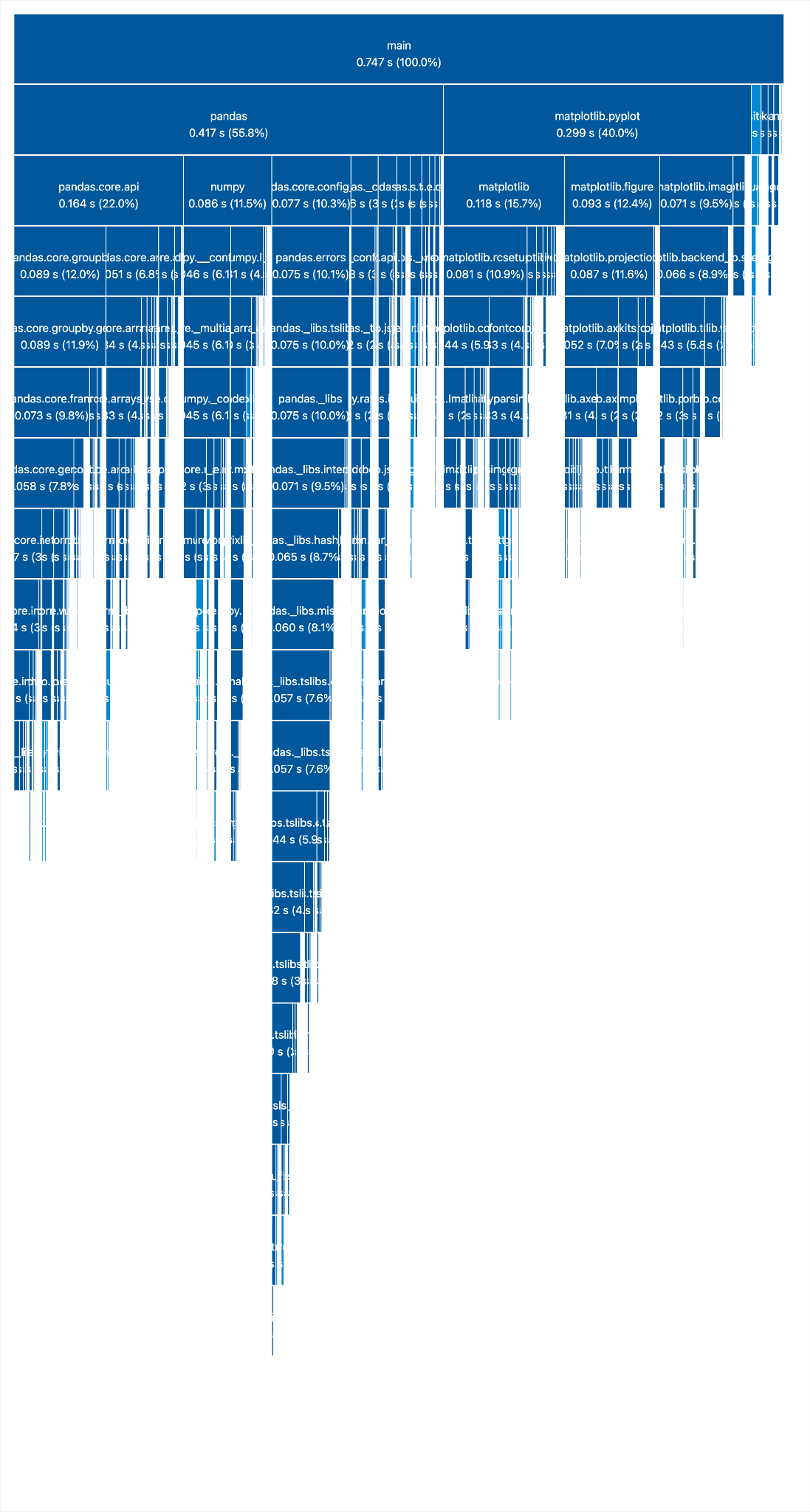
As you see, importing pandas accounts for half of the time it takes to load all the modules, and we never use it!
Now let’s add `lazy` to all the imports.
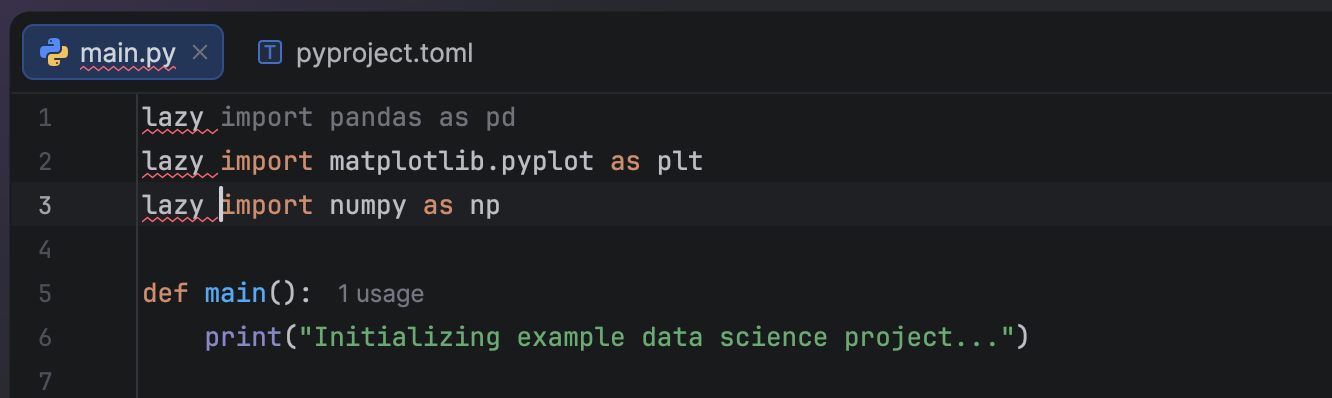
Don’t worry about the syntax highlighting. PyCharm just doesn’t recognize it yet since `lazy` is a new keyword that has not been officially released.
Let’s profile the script again.
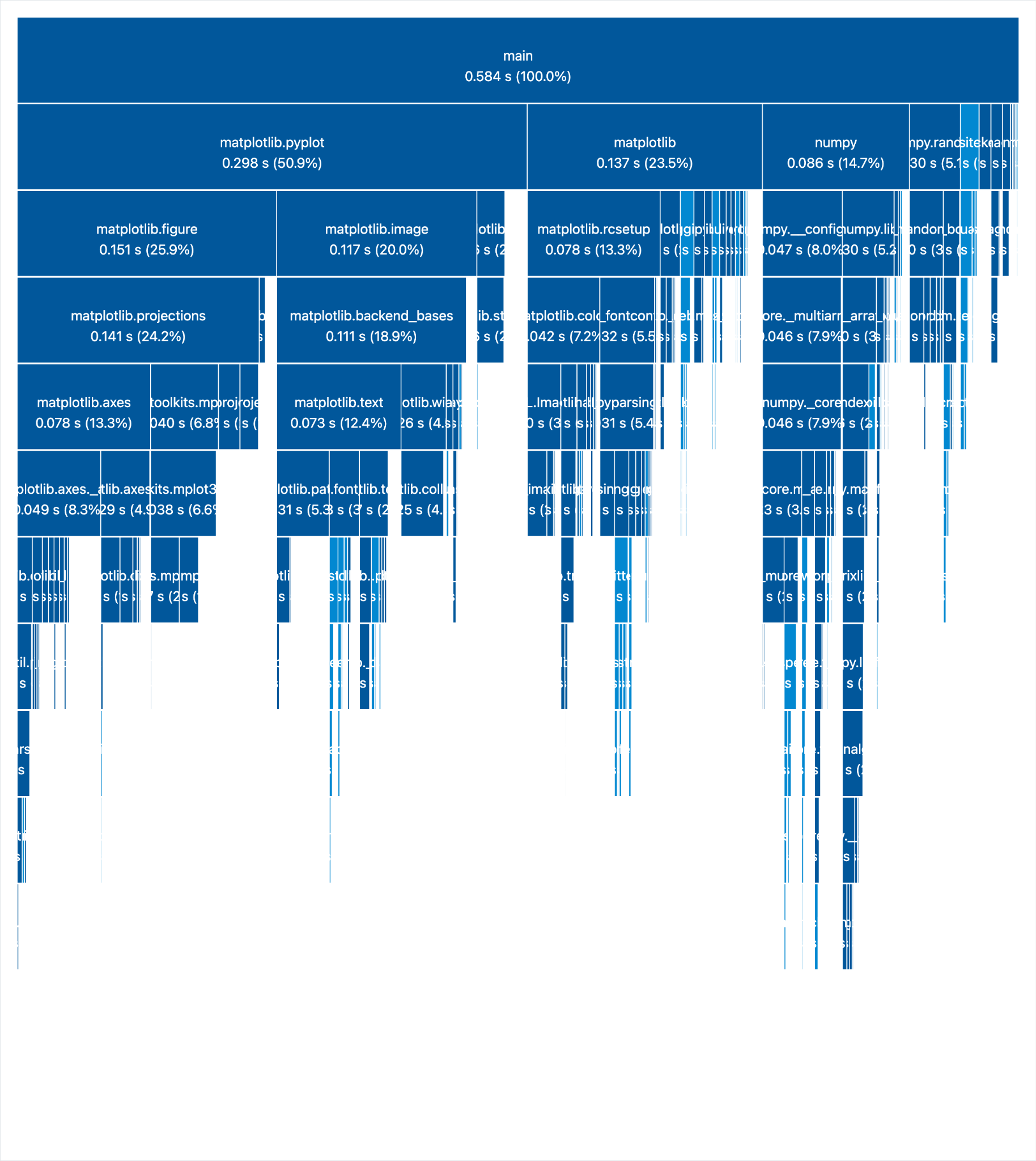
Now we see the pandas import is gone, and loading everything takes way less time.
So, if you have a script that imports a lot of large libraries, and some of them are only used in certain conditions (e.g. in if-else clauses), lazy import can save time by loading modules only when they are first used.
Checking the inner workings with lazy imports
Let’s see how lazy imports are handled internally.
When a module is imported “lazily”, meaning `__lazy_import__` is called instead of `__import__`, a `types.LazyImportType` proxy object will be created. The module name will then be listed in `sys.lazy_modules` instead of `sys.modules`. (See the Lazy import mechanism section in PEP 810.)
When a lazy object is used, it needs to be reified. CPython will try resolving the import at that point and replacing the proxy object with the actual module itself. In this process, `__import__` is called to resolve the import. At the same time, the module is removed from `sys.lazy_modules`.
If there’s an error during reification, AKA importing the module, the lazy object is not reified or replaced. The next time the lazy module is used, the import will try again. The exception raised during reification will also show both where the lazy import was defined and where it was accessed. (See the Reification section in PEP 810.)
To experiment with it ourselves, let’s add some breakpoints with `pdb` and check what’s happening in the code:
import pdb pdb.set_trace() lazy import pandas as pd lazy import matplotlib.pyplot as plt lazy import numpy as np pdb.set_trace() …
And
# Generate some dummy data
data = {
'x': np.linspace(0, 10, 100),
'y': np.sin(np.linspace(0, 10, 100)) + np.random.normal(0, 0.1, 100)
}
pdb.set_trace()
# Plotting
plt.figure(figsize=(10, 6))
pdb.set_trace()
…
Now run the script in the console:
python main.py
Note that PyCharm 2026.1 does not yet support Python 3.15, so using the Run or Debug button to run a script using lazy import may result in unexpected behavior.
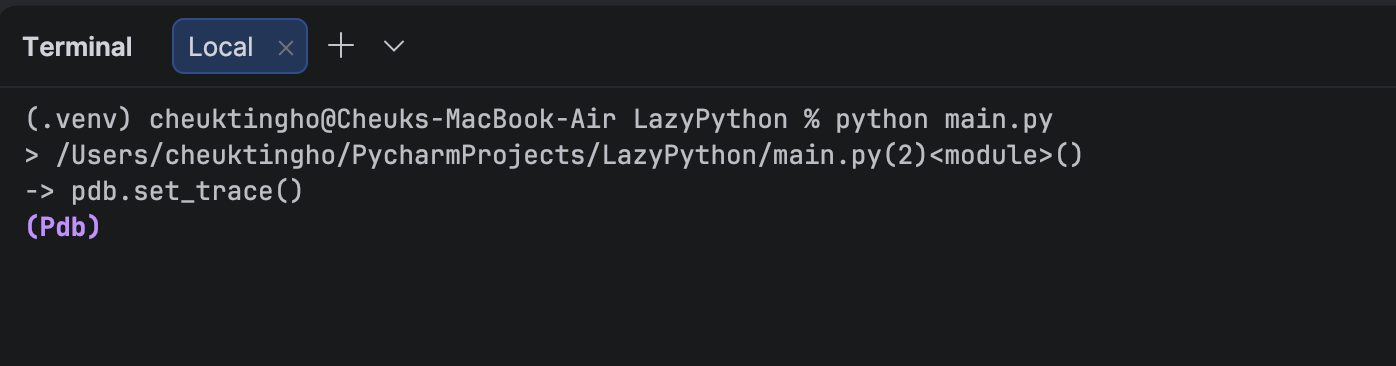
When it hits the first line of ` pdb.set_trace()` at the top, there should not be any module loaded in. Let’s check:
(Pdb) import sys (Pdb) sys.lazy_modules
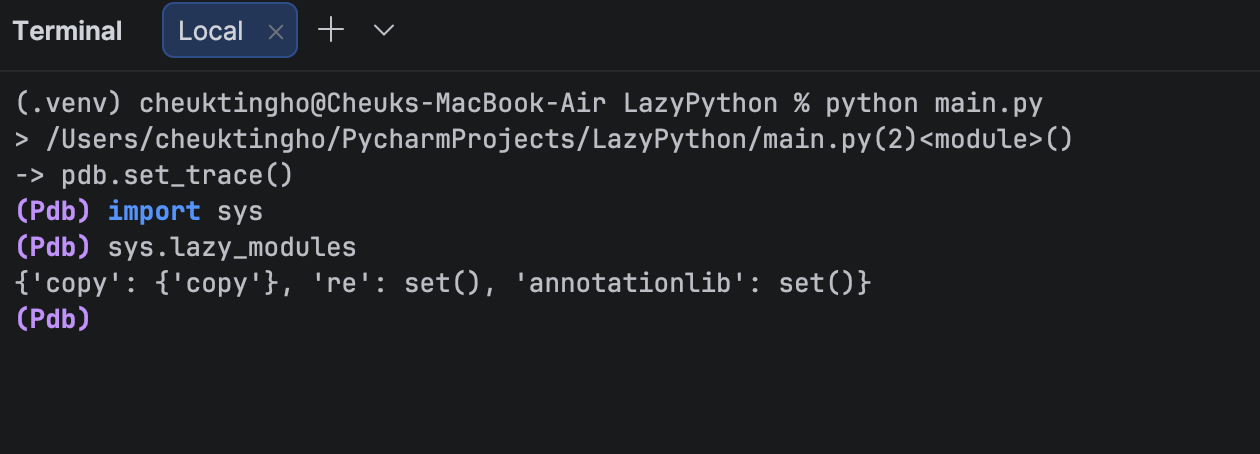
As expected, none of our libraries – pandas, numpy, and matplotlib – are listed.
Now, let’s continue running the program and let it stop at the next breakpoint. In the console, type `continue` and once it stops, we can check by typing `sys.lazy_modules` again:
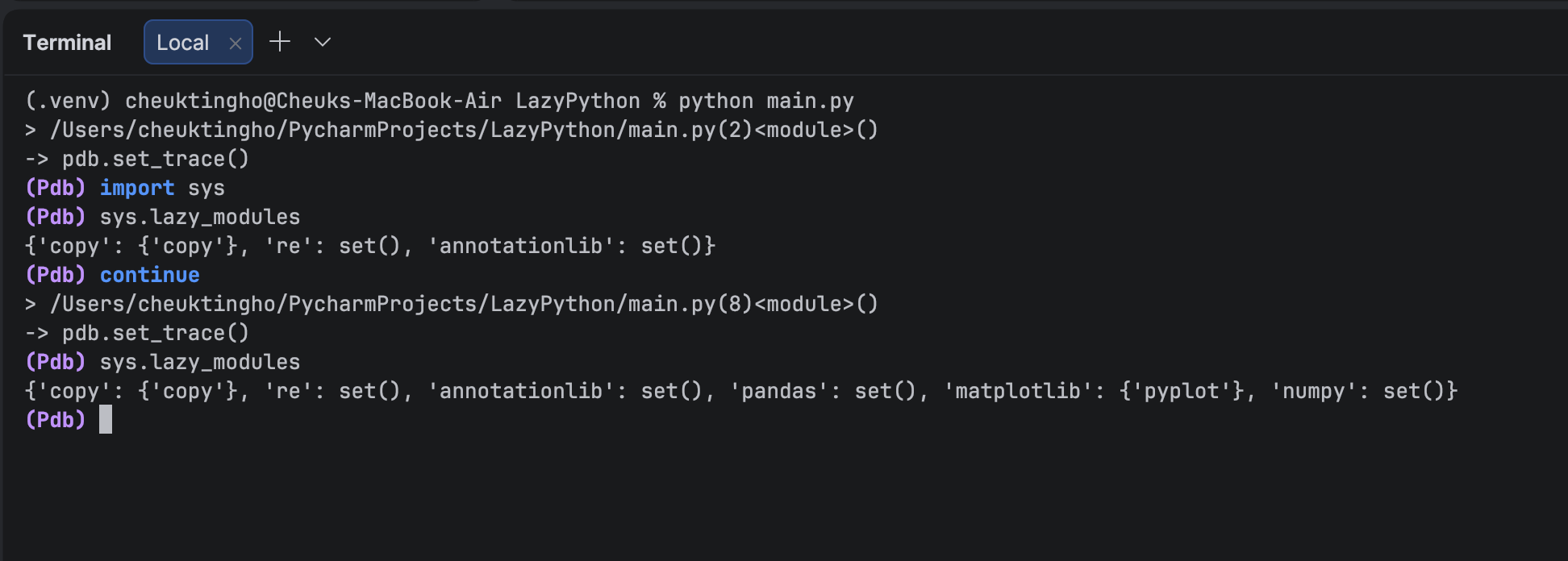
Here, we see that all of our modules are in `lazy_modules`. Let’s check whether pandas is in `sys.modules`:
(Pdb) 'pandas' in sys.modules
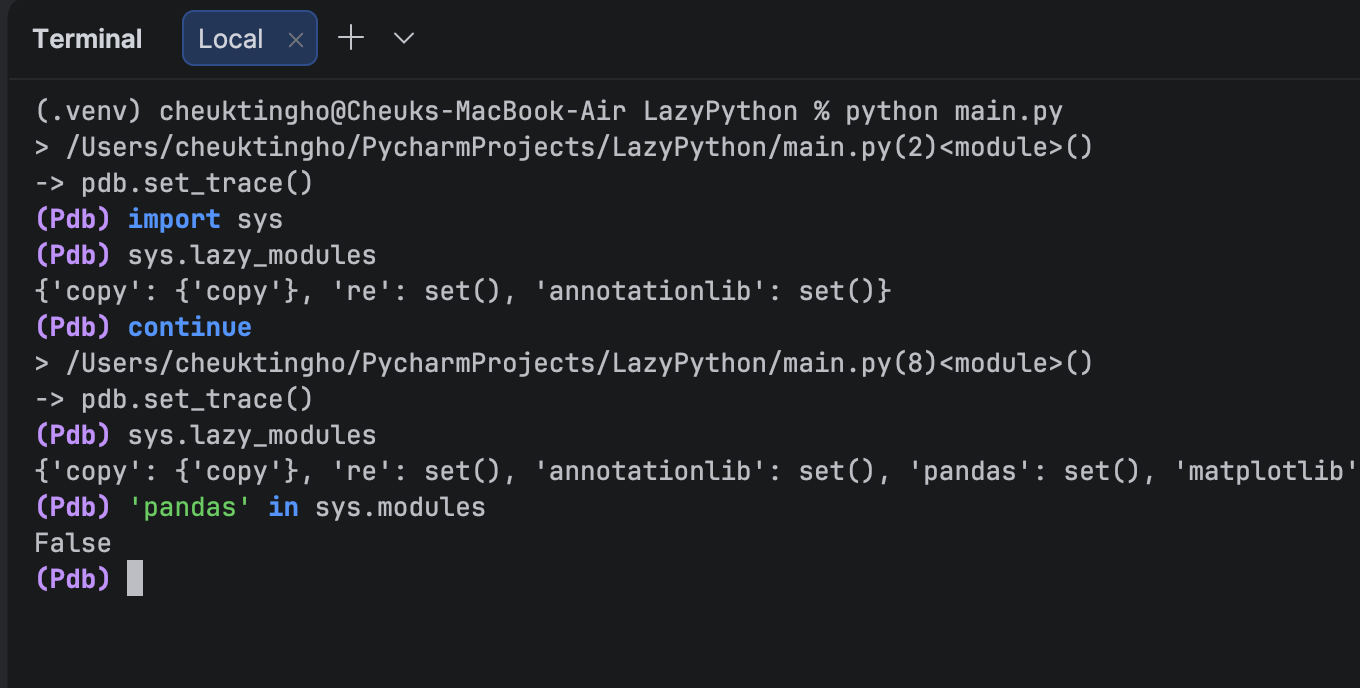
Nope, it’s not. You can try with numpy and matplotlib, and you will see that neither of those is in `sys.module`.
Now let’s type `continue` again and reach the next breakpoint, which occurs after numpy is used. Check `sys.lazy_module` again, and you’ll see that numpy is no longer on the list. When we check whether it is in `sys.module`, we get `True` this time.
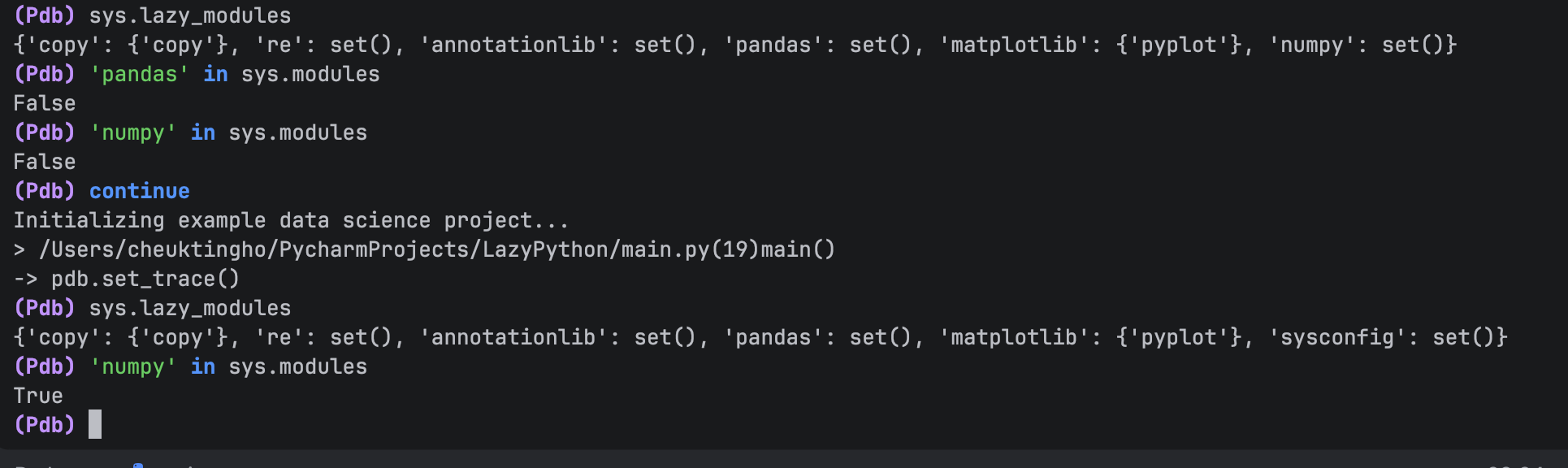
However, pandas and matplotlib are still not in `sys.modules`.

When you check the next breakpoint, you’ll see that matplotlib is similarly removed from `sys.lazy_modules` and added to `sys.modules` after it is used.

Trying it yourself with PyCharm
Download the latest version of PyCharm to experiment with Python 3.15.0b1 and experience firsthand how explicit lazy imports can optimize your application’s performance by significantly reducing startup latency and memory consumption.
Bob Belderbos
Python Is Not Enough: Why Pythonistas Love Rust (Podcast)
I joined Bas Steins and Michal Martinka on their complexity.fm show to talk about why Pythonistas are picking up Rust, what AI really does to how we learn, and why vibe coding is a myth. The conversation ran for over an hour because there was a lot to unpack.
Watch the full episode on YouTube:
Highlights from the episode
-
Why Pythonistas reach for Rust
- A lot of tooling is created and rewritten in Rust (Ruff, uv, Polars, Pydantic core).
- Rust's strictness offers better guardrails for non-deterministic agents. Open Python vs closed Rust (mutability opt-in, single owner, compiler rejects skipped cases).
- Fighting the borrow checker changes how you write Python.
- Related: Learning Rust made me a better developer and The Rust compiler as an AI coding agent guardrail
-
You can get far with Python's type checkers
- We discuss how for business logic and when performance is not essential, Python + type checkers gets you far.
- What Rust still gives you though is exhaustive enum matching enforced by the language.
- The tooling got a lot better: Modern Python tooling: uv, ruff and ty
-
Vibe coding is a slot machine
- Real dopamine effect, working with multiple agents has a lot of context switching, which is bad for productivity (and your brain).
- The real speed up number: not 10x, more like ~1.2-2x. You get a prototype in an hour, but then the iteration/judgment/cleanup often takes days.
- The rubber-stamping risk: code that looks plausible, but you miss the 50 lines duplicated three times, because you didn't feel the pain of producing the code.
-
Timeless coaching that outlives the hype
- All project-based, it's the best way to learn holistically, but noticing a shift from greenfield (2020) to more brownfield and AI hardening these days.
- Ryan's Payroll SaaS case study: tools changed, TDD/guardrails mindset didn't and stemmed from the coaching years ago ("don't give the fish, teach how to fish"). More on this: AI coding tools fundamentals case study.
Where to go from here
Michal ends on a positive note:
I think the world is actually starting to heal. I think there will be a lot of adjustment with all this AI hype.
And it's something I am coming back to as well: yes, we have a powerful set of new tools, but they are only as good as the knowledge and judgment you bring to them. The hype is deflating into something more honest, and the tools aren't going anywhere, but neither is the need for engineers with deep skills.
If you want to further develop this skill set, check out how I help engineers level up.
June 24, 2026
Brett Cannon
Why I wrote PEP 832 -- virtual environment discovery
While I decide what to do with PEP 832 after polling folks on their opinion, I thought I would write out why I&aposm even bothering with any of this.
I&aposm going to talk from the perspective of VS Code and its Python extensions, but you could just as easily substitute "VS Code" for your editor of choice or even "AI agent" and it wouldn&apost change the problem: it isn&apost necessarily easy for tools like VS Code to know what workflow (tool) you&aposre using and thus where you&aposre putting your (virtual) environment(s) (I&aposm going to say "environment" as a stand-in for virtual environments, conda environments, etc.). Knowing where the environment lives is important in order to know how to run your code (as the environment will have a Python interpreter that you can use), analyze your dependencies (so linting, auto-complete, etc. do the right thing), etc. So having a way to communicate to VS Code where to find the environment is important.
The problems
First time seeing a project
When you first open a project in VS Code, you may have just done a git checkout, so nothing is set up yet. How is VS Code to know what workflow tool you prefer for creating an environment? Do you prefer Hatch? Poetry? uv? No preference? Some custom solution you have just for you (my-tool)? VS Code could guess maybe based on some tool table in pyproject.toml, but that requires having a known list of tools to look for. And while I know some people will say, "just assume uv", I&aposve been doing this long enough to know not everyone uses that tool and it isn&apost guaranteed to be the tool of choice forever (I remember when pipenv was what everyone recommended). Right now there is no way to know what tool a project wants to see used. Same goes for if you have a personal preference when a project has no reason to care. VS Code could have you specify such a preference in your settings or in .vscode/settings.json for a project, but that would then be VS Code-specific and would only work for supported workflow tools that were hard-coded (sorry, my-tool).
What if you ran git checkout , ran your workflow tool to create the environment, and then opened the project in VS Code? There might be an extra hint about which tool was used if VS Code is able to find the environment on its own, but that assumes VS Code even knew where to look for an environment for that hard-coded list of tools. This also has the same issue of needing VS Code to know where various tools put their environments as well as tie the environment back to the project. And that sort of thing is typically an implementation detail, and thus prone to change unexpectedly.
Finding all the environments
Tying into finding the environments, how do you know which environments are meant for the project? Some tools keep environments locally with the project files, but some keep them in a global location. And when that happens you need specific knowledge to map the environments back or hope the tool has a CLI call that returns a list of the environments in a way that never changes.
And then there&aposs the added wrinkle of workflow tools that never tie an environment to one project. Tools like virtualenvwrapper and conda let you name an environment so they can be shared across projects. But then that means VS Code can&apost know what environment to use without asking. And when someone has 700 or more environments (and that number is from actual experience; it isn&apost an exaggeration), it doesn&apost make is easy to know what environments to suggest.
Possible solutions
Let&aposs work backwards from already having an environment to figuring out what workflow tool to run.
The simplest thing is when there&aposs a virtual environment in a .venv directory. It&aposs easy to discover and can thus be quickly used. It doesn&apost help you modify the environment as you don&apost know what workflow tool was used and whether it cares that it is used to make any changes to the environment, but at least you can run code and analyze the environment.
Solving for when an environment is kept outside of a project or if there is more than one can be done with a file that records such details. Right now I&aposm proposing a .python-envs file which is just a newline-delimited list of paths to environments, with the last one being the one to use by default if the user doesn&apost want to have to choose (FYI what&aposs in the PEP as of this writing is out-of-date).
Knowing what workflow tool a project wants you to use is currently suggested to be done by a [workflow] table in pyproject.toml. That would specify how to launch a workflow tool in a server mode implementing the workflow server protocol (WSP, which has a nice connotation for whitespace in grammar definitions). That would let the tool communicate via JSON-RPC over stdin/stdout with VS Code about what environments there are, creating environments, etc. VS Code would provide a way to specify a fallback tool for when a project doesn&apost have a preference, but there currently isn&apost any thinking about how to make specifying a fallback a standard.
An alternative I have proposed in the past is having some naming convention for CLI tools and then they return the necessary details. This could still use WSP or come up with some CLI standard that tools implement, but it would help solve the issue of not knowing what fallback to use.
Why I care about any of this
VS Code is used across the experience spectrum: from first-time programmers to senior programmers with decades of experience. One common theme across experience levels is no one likes having to set something up. Another theme is no one likes dealing with environments. As such, I&aposm trying to find as much of a solution as people will agree to that makes getting started as easy as possible and hides environments as much as possible. And I want to do all of this in a way that isn&apost specific to VS Code if it doesn&apost have to be.
On top of that, people often don&apost want to leave VS Code to do any workflow stuff. That makes VS Code a user of the workflow tool rather than a peer. Thus VS Code uses the workflow tools as middleware which they aren&apost usually designed to do. With no tool-to-tool communication standard you end up with bespoke support like the Hatch extension which uses public APIs from the Python environments extension, which means it doesn&apost easily scale to help other tools. It&aposs great for VS Code users that extension exists, but other editors don&apost get that benefit. As well, the extension takes effort and that takes away from what could have been a general solution for any editor.
Django Weblog
Django 6.1 beta 1 released
Django 6.1 beta 1 is now available. It represents the second stage in the 6.1 release cycle and is an opportunity to try out the changes coming in Django 6.1.
Django 6.1 offers a harmonious mélange of new features and usability improvements, which you can read about in the in-development 6.1 release notes.
Only bugs in new features and regressions from earlier Django versions will be fixed between now and the 6.1 final release. Translations will be updated following the "string freeze", which occurs when the release candidate is issued. The current release schedule calls for a release candidate in about a month, with the final release scheduled roughly two weeks later on August 5.
Early and frequent testing from the community will help minimize the number of bugs in the release. Updates on the release schedule are available on the Django forum.
As with all alpha and beta packages, this release is not for production use. However, if you'd like to try some of the new features or help find and fix bugs (which should be reported to the issue tracker), you can grab a copy of the beta package from our downloads page or on PyPI.
The PGP key ID used for this release is Jacob Walls: 131403F4D16D8DC7
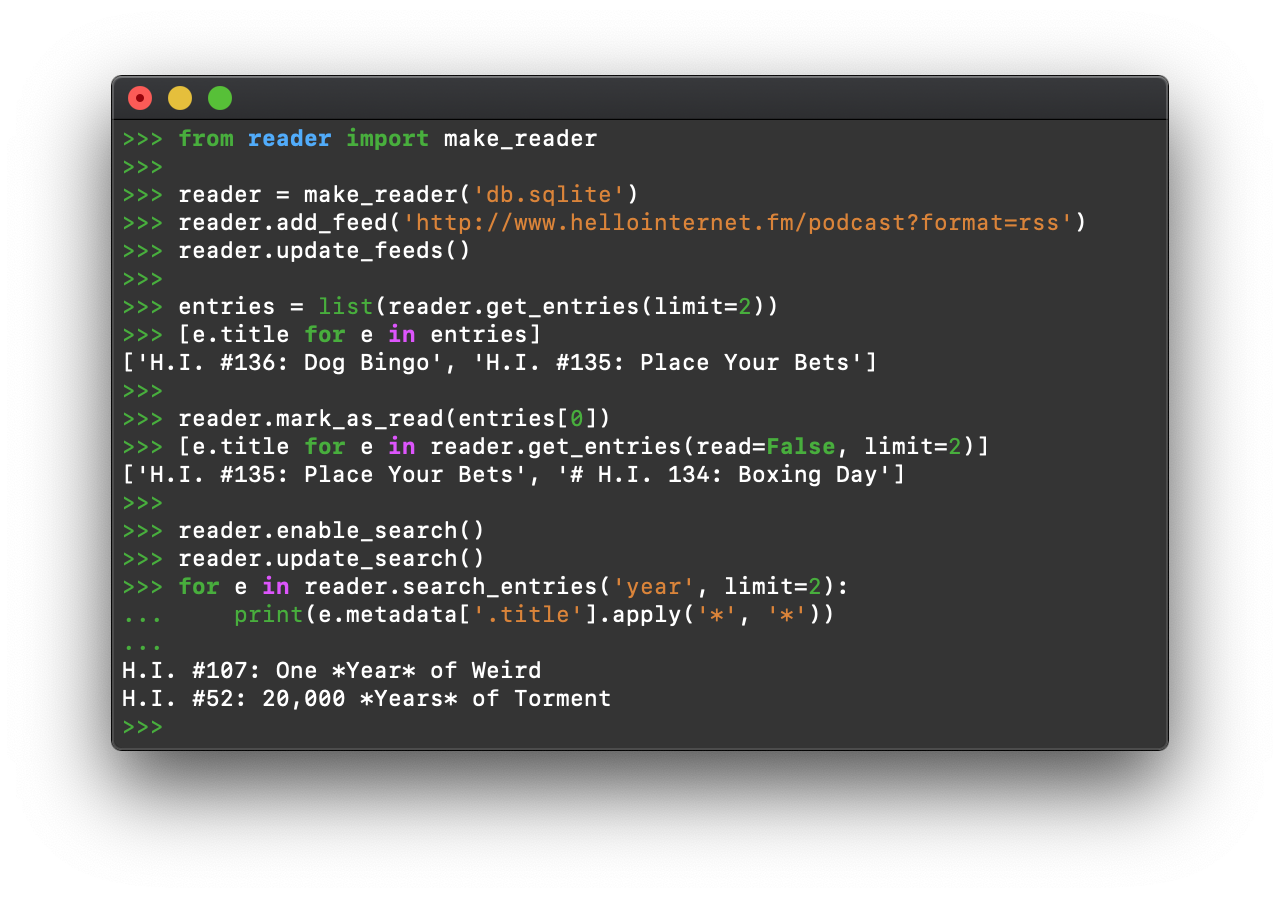
death and gravity
reader 3.26 released – discovery, exports, demo
Hi there!
I'm happy to announce version 3.26 of reader, a Python feed reader library.
What's new? #
Here are the highlights since reader 3.24.
Feed autodiscovery #
reader now discovers feeds automatically – instead of searching for feed links, just add the website URL, and the web app will suggest any feeds it finds.
Behind the scenes, this is enabled by the autodiscover plugin, which stores discovered feeds in a feed tag, so you can use it without the web app, or even without reader. For a short related rant about standards, check out this Bluesky thread (there are cats!).
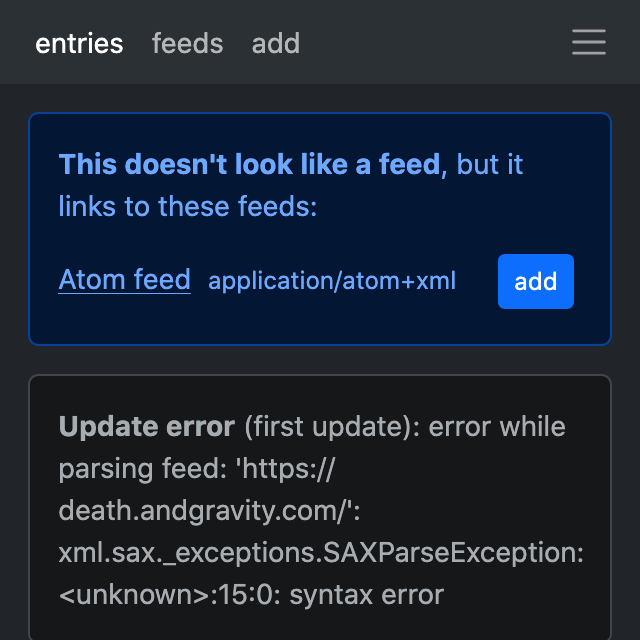 feed autodiscovery
feed autodiscovery
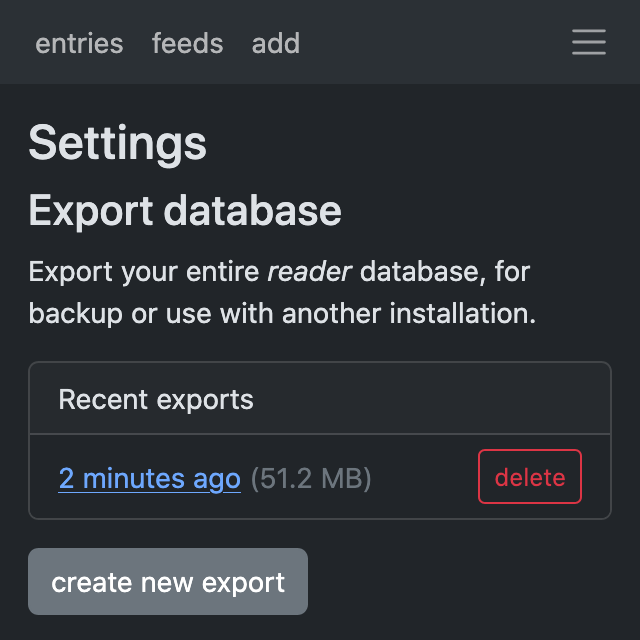 database exports
database exports
Database exports #
This is an optional feature that I really wanted in the hosted reader MVP – it should be possible to get all your data out, not just lists of feeds and read / starred articles.
So yeah, now you can download a copy of your entire database from the web app, which means you can always migrate to another reader installation. (If you're using reader locally or self-hosting, the command might be handy for backups.)
Hosted reader status update #
Speaking of, did I tell you I'm working on a hosted version of reader? :D
Background: Why another feed reader web app?, Why not just self-host it?
Public demo #
Another thing I wanted for the MVP was a demo (no login needed):
Go forth and click all the things! (it's read-only, nothing should break™)
OK, so what now? #
This is what is finished so far:
- multi-user version of the web app
- authentication via email
- infrastructure deployments using pyinfra
- multi-user feed updates
- context-sensitive help
- (new) public demo
So just launch the damn thing already:
- set up a landing page
- give it a good name
- publish a launch announcement + roadmap
Meanwhile, if this sounds like something you'd like to use, get in touch.
That's it for now. For more details, see the full changelog.
Want to contribute? Check out the docs and the roadmap.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- import / export feeds as OPML
- automatically discover feeds in web pages
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies
Spyder IDE
How your donations transformed Spyder in 2025
Thanks to the community's financial support, Spyder has not only survived but thrived in 2025. Read on as we share the new features, releases and interface improvements from the last year that your donations directly made possible.
June 23, 2026
PyCoder’s Weekly
Issue #740: Pluggy, ABCs, Scrapy Extensions, and More (2026-06-23)
#740 – JUNE 23, 2026
View in Browser »

Plugins Case Study: Pluggy
Pluggy is an open source plugin system used by frameworks such as pytest and tox. This article introduces you to how it works and what you can do with it.
ELI BENDERSKY
Implementing Interfaces in Python: ABCs and Protocols
Learn how to implement interfaces in Python using abstract base classes, Protocols, and duck typing, and enforce method contracts cleanly.
REAL PYTHON
Production Monitoring for Python Apps — Built by Developers, Not Suits

Error tracking, intelligent logging, and Just Enough APM™ in one tool. Our founders Ben and Josh built Honeybadger to fix their own production headaches. They think it can fix yours too — and they’ll personally write back if you hit a snag. Try Honeybadger Free!
HONEYBADGER sponsor
How to Build Your First Scrapy Extension
Scrapy is a great extensible web scraping python framework, here’s how to make it better with plugins.
AYAN PAHWA • Shared by Ayan Pahwa
Large Number of PEPs Marked Final
As part of the 3.15 beta, a significant number of PEPs have been moved to “Status: Final”: PEP 753, 668, 687, 691, 699, 701, 703, 728, 753, 770, 773, and 829. For more details see the list of PEPs.
GITHUB.COM/PYTHON
Articles & Tutorials
Python 3.14 Garbage Collection Rigamarole
Python 3.14.0 introduced a new incremental garbage collector. But reports of higher memory usage caused the Python team to revert the garbage collector changes in 3.14.5. This post covers how memory management works in Python and workloads that perform best and worst for the incremental garbage collector.
PIERRE ZEMB
Choosing a Python Task Queue Library in 2026
This post compares the Python task queue libraries worth considering in 2026: Celery, Dramatiq, FastStream, Taskiq, and Repid. The comparison covers broker support, async behavior, benchmark results, and the places where they differ.
ALEKSANDR SULIMOV • Shared by Aleksandr Sulimov
Are Insecure Code Completions a Vulnerability?
Seth tries out the PyCharm “Full Line Completion” plugin that uses a deep learning model to suggest lines of code, and is concerned about the results. Many of the suggestions were for code that turns off security features.
SETH LARSON
Everything Security at PyCon US 2026
This post to the PSF blog summarizes all things security related at PyCon US 2026. It includes the first talk at the security track, updates to how the PSF deals with security, the OSS security space, and more.
STHE LARSON
Why Dependency Management Trips Up New Developers
A mix of opinion piece and practical advice, this post talks about Python dependency management, virtual environments, Docker, and why setup issues frustrate so many new developers.
ETHAN CARVER
Context Engineering for Python Codebases
Learn how context engineering shapes what your AI coding agent sees on every turn, and use four practical strategies to keep your Python projects on track.
REAL PYTHON
Building Python Skills for the Job Market
Learn which Python skills employers value most and how to build them, using a skill roadmap worksheet, weekly practice plan, and interview prep tips.
REAL PYTHON course
Run Modified Python Code Using the AST Module
How to work with Python’s Abstract Syntax Tree (AST), a foundation of many metaprogramming techniques, and how this can be valuable in the age of AI
ALEX HALL • Shared by Alex Hall
Make Your SciPy Presentation in Quarto
Quarto is built for scientific presentations. Here’s how to build your next SciPy (or any conference) talk as a Quarto slide deck.
ISABELLA VELÁSQUEZ • Shared by Isabella Velásquez
Projects & Code
Events
PyDelhi User Group Meetup
June 27, 2026
MEETUP.COM
Python Sheffield
June 30, 2026
GOOGLE.COM
Python Southwest Florida (PySWFL)
July 1, 2026
MEETUP.COM
STL Python
July 2, 2026
MEETUP.COM
Canberra Python Meetup
July 2, 2026
MEETUP.COM
Happy Pythoning!
This was PyCoder’s Weekly Issue #740.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Glyph Lefkowitz
Adversarial Communication
As I have discussed in previous posts, “AIs” can make mistakes. In fact, they do make mistakes, and their mistake-making patterns are such that where and how they will make mistakes is both uncertain and constantly changing.
Thus, in any scenario where you want to attempt to make “productive” use of “AI”, you must have a system in place for checking every result. Not checking some results; checking every result. If each result might have a consequence for you (and if it didn’t have a consequence, why bother automating it?) and you cannot predict in advance which kinds of results will need verification, then verification is always required.
The verification often ends up being just as expensive as doing the work in the first place, which means that if you want your usage of “AI” to be personally profitable, you have to find someone else to externalize the cost of verification onto. This person becomes your adversary, and, if you are successful, your “AI’s” victim.
The Ladder-Climber And Their Reverse-Centaur Rungs
One way that this constellation of facts can straightforwardly assemble themselves into a dystopian nightmare is the phenomenon, described by Cory Doctorow, of the reverse centaur. This is when your employer non-consensually turns you into the verification system. The “AI” does the fun part of initially performing the work, and then you do the boring part where you check if the robot is right and clean up its messes, even if everyone already knows that it would, in aggregate, be cheaper for you to do the work in the first place.
Reverse centaurs can be made from any automation, not only “AI” automation. I think that there is a reason that this term happens to have emerged in the “age of AI”, though, and not with earlier automation technologies (even those which were considerably more viscerally horrific). That reason is: the wrongness of “AI” output is not merely a technical feature that must be compensated for, it is a generalized externality.
As I mentioned above, if you are responsible for the entirety of the work, both extruding the “AI” output and checking it, it’s usually cheaper to have humans do the entirety of the work to begin with. When humans do the writing directly, we can check as we go, and thus verification doesn’t need to be as comprehensive.
When “AI” coding advocates say “code review is the bottleneck”, what they are observing is that the LLM is still rolling the dice for each PR, and a human is still necessary to verify that each of those rolls is a winner. But calling this process “code review” is a bit of a misnomer; it’s not really “code review” in the traditional sense, it’s human understanding.
Before the advent of “AI”, the human understanding was implicit in the process of writing the code in the first place1, and the code review was a way of diffusing and extending that understanding. Now that the code can be authored with no initial understanding taking place, that cost has not gone away, it has moved.
Human understanding was always the bottleneck.
However, this is taking a collaborative view of a software project, where satisfying the needs and solving the problems of your customers are the goals. We can see that “AI” is a bad tool to satisfy those goals, because all it’s doing is converting the first half of the work, that of understanding the code as you write it, to understanding the agent’s output as you read it.
What if, instead, we were to take the view that every software company is a Hobbesian nightmare, red in tooth and claw? In this view, the only goal of a software project is for the individual developers to make their promo cycles and get their bonuses. Given that there is only a certain amount of money to go around, this is a zero-sum game where each programmer wants to look more productive than their colleagues.
Pretty much every organization finds it easy to reward “productivity” as expressed by lines of code emitted, but the benefits of doing thorough and thoughtful design, analysis, and code review very difficult to reward. In this world, an LLM is an invaluable tool for the sociopathic ladder-climber, particularly if your legacy organization is still structuring their workflows as if the person prompting the bot is “writing” the code, and then they get to foist off the act of “reviewing” the code onto someone else.
Here, the prompter effectively externalizes the cost of the LLM’s failures but internalizes any benefits. The prompter will vibe-code a big feature, so large that the assigned reviewer can’t possibly comprehend it all effectively. When this happens, the reviewer will, eventually, be pressured to approve it, even if they can try to spot a few problems along the way. The reviewer has their own work to get back to, after all, the obligation to review the prompter’s (read: the bot’s) code is a drain on their time that they are not going to get rewarded for.
If this feature is a big success, the prompter gets a promotion. If it causes a big issue, well, the reviewer must not have been careful enough.
This is why LLMs are “good for coding”, and also why their biggest promoters keep having outages.
The Generative Gish Galloper
Coding is the biggest “success story” of this type of adversarial communication, but it is by far not the only instance of such a thing. LLMs create a new form of leverage that can turn Brandolini’s law from a linear advantage into an exponential one. If you are engaged in a political debate where you want to overwhelm the other side in nonsense, an LLM can generate bullshit faster than it is physically possible for a human being to type, let alone respond thoughtfully. There is an asymmetry to the utility of this weapon as well: only one side of the political spectrum wants to flood the zone and destroy trust in institutions and the concept of truth. There’s a good reason that the fascists love it.
Straightforward Spam and Fraud
This is kind of obvious, but LLMs can generate lightly-customized, plausible-looking text much more quickly than any human being. This facilitates their use in fraud, spam, and scams. In a spamming or fraudulent interaction, once again, the costs are externalized onto the victim: the recipient of a spam message has to do all the work of “checking” the LLM’s output. Spammers already expect very low hit rates from boilerplate, and if the LLM can increase those percentages from 1% to 5% the technology will pay for itself; they don’t need anything like reliable accuracy.
Customer “Support”
If you have any kind of commercial relationship with a company, I probably don’t even need to mention this: customer “support” bots are a misery. Everybody knows it at this point. But customer support is usually conceptualized by businesses as an adversarial interaction, because it is a cost center. They maintain internal metrics on time-to-resolution and try to optimize them. Implicitly, this creates a dynamic where the goal of the customer service agent’s job is not to solve your problem, but to emit noise that will cause you to think your problem is resolved, or to give up, as fast as possible. Unsurprisingly, LLMs can emit this noise faster than humans can, getting those customers off the phone. But those customers will remember those interactions, and the story outside the TTR metrics is horrible.
Similarly to the situation in software development, LLMs can look very good on paper for customer support, but mostly what they are doing is illuminating the problems with the industry’s existing metrics, by turning “winning the metrics battle against the customer” into a more obvious and immediate defeat for the company’s long term reputation.
“Education”
In 2026 it is sadly a fact of life that students cheat all the time using “AI”, and that this cheating is very successful, in that the teachers find it very hard to detect.
LLMs are great for cheating on schoolwork because the student is externalizing the work of the checking onto the teachers, who are often starting at a disadvantage to begin with, at least in the US.
My view is that this is happening because of a divergence in the way that students vs. teachers (or, more accurately, “the broader educational system”) view grading.
When a student is asked to write an essay, the teachers see the effort as both intrinsically worthwhile for the student, as well as useful as a pedagogical tool to evaluate and react to the student’s progress. The student, by contrast, sees a stumbling block designed to knock them off the path to success and into a permanent underclass. It is no wonder that the student sees “AI” as useful to their own goals and has no compunction about deploying it.
There is a bitter irony that the ability to understand the inherent value of actually writing the essay on their own is the sort of thing that students can really only learn by writing a bunch of essays. There’s no way that I can think of which makes the benefit legible as long as a shortcut is available.
The net effect here is a downward spiral, where the already-wobbling educational system is sustaining an attack that it doesn’t have the resources to recover from. The individual students’ attacks against their teachers and their schools’ grading systems might appear to momentarily succeed, but they will win the battle and lose the war.
Spamming “For Good”?
Usually when we talk about someone unilaterally choosing to enter into an adversarial relationship, that’s an “attack” and for good reasons we have a negative impression of the attacker. However, I would be remiss if I did not point out that there are some cases where the relationship was already adversarial; just because you’re the attacker doesn’t mean that you are evil.
For example we might imagine use-cases like automatically filing appeals for prior authorizations against health insurance. It’s relatively well-known at this point that the main way for-profit insurers maintain their margins is by denying claims right up to the line of the policies themselves being fraud, so using a spamming tool to fight them might be entirely justifiable2 in that case.
Similarly, using an LLM could be justified in a fight against a company refusing to honor a warranty. One could imagine using an LLM to immediately generate replies and escalations.
However, even in imagined cases like these, the underlying problem is that the insurers and the vendors already have a tremendous amount of structural power, so it is more likely that they will have the advantage in deploying a communications weapon like an LLM, as well as enacting policies to simply ignore any LLM-based communication that you might submit. Worse, if these strategies were to become widespread, they might provide an excuse to reject any communications by feeding them into an unreliable “LLM detector” and issuing an automated “computer says no” even to hand-written correspondence.
It is also worth stressing that these cases are imagined, as compared to the very real coworker-abuse, spam, scam, fraud, and disinformation campaigns being waged in real life today.
Therefore, while legitimate uses might exist, it’s hard to imagine that there’s anywhere they would be genuinely valuable and sustainable. In the best case “AI” will provide a temporary advantage for underdogs that will provoke an arms race which the resource-advantaged adversaries will win in the long run, in the worst case the arms race itself will cement permanent structural change that will make things worse.
“Search” By Stealing
Most of the adversarial utility of “AI” is on the “write” side, since write-amplification is more obviously aggressive than reading. But the “read” side of LLMs — summarization and question-answering — can be a form of attack as well.
To begin with, the act of reading
itself
is currently enormously destructive, but that’s arguably not a fundamental
aspect of this technology. They could set reasonable rate-limits and respect
things like robots.txt, as search engines have for decades now. They could
also refrain from committing criminal
levels
of copyright
infringement.
But, today, using “AI” tools does suborn this sort of out-of-control crawling.
More insidiously, consider the scenario described in this YouTube video. The LTT Bros decided to try Linux again, and in the course of so doing, they had problems. When trying to solve these problems, they were faced with a choice: they could consult Reddit, or they could ask an LLM. Asking an LLM would “gaslight the heck out of” them, but they still found it preferable, because they would at least get an answer without getting yelled at.
Initially this sounds great. But it also means that you want to extract knowledge from a community, while mechanically eliding any values or norms that the community may want to impart as part of offering that knowledge. As someone who spent many years in a community tech support role, this is worrying. Many requests for support are people asking how to do things that will momentarily solve a superficial problem but create a long-term reliability problem or even an immediate security risk, that the question-asker doesn’t want to hear about. Consider the question “I’m tired of entering my password so much, how do I make it so my laptop unlocks automatically”. An obsequious chatbot will helpfully tell you how to do this without pushback.
But, this is also a sort of ethically murky area. The Linux community is somewhat famously, for many years now, a toxic cesspool of general hostility, misogyny, etc. It is certainly a good thing that people can get access to this knowledge without subjecting themselves to abuse. But it also means that the people with the power and the privilege to change the community for the better can just quietly withdraw, rather than fixing the problems. It also means that the positive elements of culture cannot be transmitted, and people will have no opportunity to learn about unknown unknowns.
In this case, the “adversarial” communication is with society. The thing that using an LLM for search lets you do is withdraw from society and avoid forming any personal connections. There are some personal connections which are painful and annoying, and so that can feel like a momentary balm. But the need to make connections in general is, like, the concept of society itself.
Who Am I Hurting?
LLMs are good at adversarial communication. They are so good at it, relative to their other benefits, that they will tend to make communications adversarial if you are not remaining vigilant about the possibility that it might do so. My request to you, dear reader, if you are going to use such tools, is to always ask yourself, “who might I be hurting, if I use an LLM for this?”
If you’re using an “AI”, who is its adversary? If you haven’t given it one yet, who might the “AI” turn into an adversary? Who might you overwhelm with an asymmetric amount of output, or, if you’re receiving information and not sending it, who are you taking that information from without consulting?
Figure out the answers to these questions and conduct yourself accordingly; the answer might be “yourself”.
Acknowledgments
Thank you to my patrons who are supporting my writing on this blog. If you like what you’ve read here and you’d like to read more of it, or you’d like to support my various open-source endeavors, you can support my work as a sponsor!
-
One of the reasons that software developers tend to prefer greenfield development is that when you are given a blank page, you can project your own specific understanding onto it. You can structure the codebase in a way that works for your brain, down to the variable naming conventions and the module layouts. LLM-assisted development makes everything into instant brownfield work, which makes developers instantly miserable; even those who are excited about the technology will frequently complain about how it feels like their agency has been stolen and their joy in the work has been diminished. But I digress. ↩
-
Modulo the massive amount of other externalities involved in using LLMs, of course, but I don’t have the time or energy to get into those here. ↩
Python Software Foundation
Mitigated API authentication bypass for python.org download metadata
This post is a cross-post from the Python Insider Blog.
On February 23rd 2026, Splitline Ng from the DEVCORE Research Team reported to the Python Security Response Team (PSRT) an authentication bypass vulnerability in the “python.org” release management API. By supplying an admin username with an arbitrary API key the request was processed with admin privileges.
If exploited, this would have allowed an attacker to modify Python release and file metadata that affects what URLs users are offered when visiting python.org/downloads. While it would not enable existing release files to be modified in-place, it would enable an attacker to modify the URLs that are provided on python.org for each release file, including verification material URLs. There is no evidence this vulnerability was exploited after auditing logs and database backups. This scenario is even more unlikely to have happened unnoticed due to the many redistributors requiring Python Sigstore and PGP materials be verified prior to builds.
PSRT confirmed the vulnerability on a local instance of python.org. Seth Larson and Hugo van Kemenade developed and deployed the patch to production with help from Jacob Coffee. Less than 48 hours after the initial report the PSRT and the reporter confirmed that the proof-of-concept provided by the reporter no longer worked locally or on the production deployment.
This vulnerability was likely never exploited. However due to the age of the vulnerability (existing in the codebase since 2014) we don’t have absolute certainty beyond our logs and database backups. We believe attempts to exploit this vulnerability would have been “loud” and discovered quickly given the number of downstream tools and distributions automatically verifying the Sigstore and PGP materials.
We confirmed that all artifacts on python.org had not been modified by verifying Sigstore and PGP materials. Our own workflow verifying all Sigstore signatures did not signal any changes to artifacts from years prior. While verifying PGP materials we were able to verify all signatures where keys are still readily accessible from Python 2.5 to 3.13. Note that Python 3.14 and onwards no longer provide PGP materials, so these were verified with Sigstore.
The codebase was manually audited and additional hardening was applied. In addition to manual auditing, LLM auditing tools were unable to find additional issues with authentication. The delay between the initial finding and publishing of this final report was to give ample time for auditing for other issues related to authentication, to receive access to LLM auditing tools, and to arrange and complete a third-party audit from Trail of Bits prior to publication of this report. Full results from the Trail of Bit audit will be published soon.
- Patch applied and deployed to ensure behavior is not mixed between the “guest” authentication mode and API key authentication. This fixes the issue and documents clearly the branch in behavior between the two cases. (python/pythondotorg#2946). Trail of Bits audit improved this functionality to require HTTPS URLs for newer releases (python/pythondotorg#3014) through a custom field validator.
- Added test cases for all negative authentication branches.
- Database and API now reject URLs which do not start with “
https://www.python.org/”. This additional hardening will reject attacker-controlled URLs even if authentication or authorization is circumvented. (python/pythondotorg#2947) - Increased logging retention from 3 days to 30 days for requests to python.org. This will aid in audit work for any follow-up reports.
- February 23rd: Report received from DEVCORE Research Team.
- February 23rd: Report acknowledged and confirmed by PSRT.
- February 24th: Patch reviewed and applied to python.org.
- February 24th: Patch confirmed working by DEVCORE Research Team.
- February 25th: Audit of logs, database backups, Sigstore and PGP completed, showing no exploitation. Codebase was manually audited by staff.
- April 23rd: LLM security auditing tools were applied to the codebase, finding no issues related to authentication or authorization.
- June 1st-5th: Trail of Bits audit of python.org and Python release process.
- June 23rd: This final report is published.
Thanks to Splitline Ng from the DEVCORE Research Team for responsibly disclosing this vulnerability and confirming the remediation.
Funding for the follow-up third-party audit was provided by OpenAI. The audit and mitigations were completed by Trail of Bits, with special thanks to Facundo Tuesca and Eric Quintero. Audit results and mitigations were reviewed and applied by Seth Larson. Seth Larson's role as Security Developer-in-Residence at the Python Software Foundation is supported by Alpha-Omega.
If your organization wants to support security at the Python Software Foundation through the Developers-in-Residence program please reach out to sponsors@python.org.
Python Bytes
#485 Creating memories
<strong>Topics covered in this episode:</strong><br> <ul> <li><strong><a href="https://offen.github.io/docker-volume-backup/?featured_on=pythonbytes">Backup Docker volumes locally or to any S3</a></strong></li> <li><strong><a href="https://blog.pyodide.org/posts/314-release/?featured_on=pythonbytes">Pyodide 314.0 Release</a></strong></li> <li><strong><a href="https://github.com/jupyter-ai-contrib/nb-cli?featured_on=pythonbytes">nb-cli</a>: A Command-Line Interface for AI Agents and Notebook Automation</strong></li> <li><strong><a href="https://hindsight.vectorize.io/?featured_on=pythonbytes">Hindsight</a> Agent Memory That Learns</strong></li> <li><strong>Extras</strong></li> <li><strong>Joke</strong></li> </ul><a href='https://www.youtube.com/watch?v=BZIGLfrjCZQ' style='font-weight: bold;'data-umami-event="Livestream-Past" data-umami-event-episode="485">Watch on YouTube</a><br> <p><strong>About the show</strong></p> <p>Sponsored by us! Support our work through:</p> <ul> <li>Our <a href="https://training.talkpython.fm/?featured_on=pythonbytes"><strong>courses at Talk Python</strong></a></li> <li><a href="https://www.midwestcommunityday.com/?featured_on=pythonbytes">AWS Community Day Midwest</a> tomorrow Wednesday the 24th in downtown Indianapolis, <a href="https://sixfeetup.com/?featured_on=pythonbytes">Six Feet Up</a> is sponsoring and there are 2 Sixies presenting</li> </ul> <p><strong>Connect with the hosts</strong></p> <ul> <li>Michael: <a href="https://fosstodon.org/@mkennedy">Mastodon</a> / <a href="https://bsky.app/profile/mkennedy.codes?featured_on=pythonbytes">BlueSky</a> / <a href="https://x.com/mkennedy?featured_on=pythonbytes">X</a> / <a href="https://www.linkedin.com/in/mkennedy/?featured_on=pythonbytes">LinkedIn</a></li> <li>Calvin: <a href="https://sixfeetup.social/@calvin?featured_on=pythonbytes">Mastodon</a> / <a href="https://bsky.app/profile/calvinhp.com?featured_on=pythonbytes">BlueSky</a> / <a href="https://x.com/calvinhp?featured_on=pythonbytes">X</a> / <a href="https://www.linkedin.com/in/calvinhp/?featured_on=pythonbytes">LinkedIn</a></li> <li>Show: <a href="https://fosstodon.org/@pythonbytes">Mastodon</a> / <a href="https://bsky.app/profile/pythonbytes.fm">BlueSky</a> / <a href="https://x.com/PythonBytes?featured_on=pythonbytes">X</a></li> </ul> <p>Join us on YouTube at <a href="https://pythonbytes.fm/stream/live"><strong>pythonbytes.fm/live</strong></a> to be part of the audience. Usually <strong>Tuesday at 7am PT</strong>. Older video versions available there too.</p> <p>Finally, if you want an bonus digest of every week of the show notes in email form? Add your name and email to <a href="https://pythonbytes.fm/friends-of-the-show">our friends of the show list</a>, we'll never share it.</p> <p><strong>Michael #1: <a href="https://offen.github.io/docker-volume-backup/?featured_on=pythonbytes">Backup Docker volumes locally or to any S3</a></strong></p> <ul> <li>Via Bryan Weber (thanks Bryan!), who spotted it over on Virtualization HowTo. Find Bryan at <a href="https://bryanwweber.com/?featured_on=pythonbytes">bryanwweber.com</a>.</li> <li><a href="https://offen.github.io/docker-volume-backup/?featured_on=pythonbytes">offen/docker-volume-backup</a> is a lightweight companion container that backs up the volumes your apps actually depend on, then ships them somewhere safe.</li> <li>It's tiny: written in Go and about 25MB compressed, roughly 1/20th the size of the shell-based image (<code>jareware/docker-volume-backup</code>) that inspired it.</li> <li>Drop it into your <code>docker compose</code> file as a <code>backup</code> service, mount the volumes you care about as read-only, and you're off.</li> <li>Push backups to a pile of destinations: a local directory, plus any S3, WebDAV, Azure Blob Storage, Dropbox, Google Drive, or SSH-compatible target. Mix and match as many as you want in one run.</li> <li>Recurring cron-style backups in a Compose setup, or one-off backups straight from the Docker CLI.</li> <li>Production-friendly touches worth calling out: <ul> <li>Rotates away old backups so you don't quietly fill the disk.</li> <li>GPG encryption for your archives.</li> <li>Notifications on finished and failed runs (so you find out about failures before you need the backup).</li> <li>Stop a container during backup for a consistent snapshot using a simple <code>docker-volume-backup.stop-during-backup=true</code> label, then auto-restart it.</li> <li>Run custom commands during the backup lifecycle (great for a database dump before the file copy).</li> <li>Docker Swarm support, plus <code>arm64</code> and <code>arm/v7</code> builds. Hello, Raspberry Pi homelab.</li> </ul></li> <li>Fun aside from Bryan: he searched our back catalog for this tool and the search came back so fast he thought it hadn't run. Love to hear it.</li> </ul> <p><strong>Calvin #2: <a href="https://blog.pyodide.org/posts/314-release/?featured_on=pythonbytes">Pyodide 314.0 Release</a></strong></p> <ul> <li><strong>PEP 783 is the real news</strong> — Pyodide maintainers used to hand-build 300+ packages. Now anyone can publish Pyodide wheels to PyPI with <code>cibuildwheel</code>.</li> <li><strong>The version jump from 0.29 to 314.0 is intentional</strong> — it now tracks the Python version, so 314.x = Python 3.14. Binary compatibility is locked per Python cycle, meaning packages you build today won't break on the next Pyodide release.</li> <li><strong><code>sqlite3</code>, <code>ssl</code>, and <code>lzma</code> are back in the default stdlib</strong> — no more <code>await pyodide.loadPackage("sqlite3")</code>. Bigger download, but a much smoother experience for newcomers.</li> <li><strong><code>bigint</code> precision bug is fixed</strong> — values above 2^53 were silently losing precision when crossing the Python/JS boundary. The new <code>JsBigInt</code> type makes the roundtrip correct. Worth flagging if anyone is doing numeric work in a browser app.</li> <li><strong>Experimental TCP sockets in Node.js</strong> — you can now connect Pyodide to a real database (MySQL, PostgreSQL, Redis tested) when running server-side. Blurs the line between "Python in the browser" and "Python runtime anywhere Wasm runs."</li> </ul> <p><strong>Michael #3: <a href="https://github.com/jupyter-ai-contrib/nb-cli?featured_on=pythonbytes">nb-cli</a>: A Command-Line Interface for AI Agents and Notebook Automation</strong></p> <ul> <li>From Piyush Jain (Jupyter and LangChain maintainer) on the Jupyter blog: <a href="https://blog.jupyter.org/nb-cli-a-command-line-interface-for-ai-agents-and-notebook-automation-996ad7edacd9?featured_on=pythonbytes">nb-cli: A Command-Line Interface for AI Agents and Notebook Automation</a>.</li> <li><a href="https://github.com/jupyter-ai-contrib/nb-cli?featured_on=pythonbytes">nb-cli</a> is an experimental, Rust-based CLI to read, write, execute, and search Jupyter notebooks. The premise: agents are great at CLIs but terrible at hand-editing the nested JSON in an <code>.ipynb</code>, so let them operate on the notebook from the outside instead of running inside it.</li> <li>Works with or without a Jupyter server. No server? It reads/writes <code>.ipynb</code> files directly and talks to kernels over ZeroMQ. Connected to a live JupyterLab, your edits show up instantly via Y.js (the same CRDT Jupyter uses).</li> <li>Smart output format: instead of token-heavy JSON or ambiguous plain markdown, it uses <code>@@cell</code> / <code>@@output</code> sentinels with inline metadata. Less wasted context, unambiguous structure, and it degrades gracefully on truncation.</li> <li>The payoff is composability. "Add a summary section and run it" becomes one shell pipeline instead of six agent tool calls. And <code>nb search notebook.ipynb --with-errors</code> returns only the failing cells, so the agent skips the cells that worked.</li> <li>Claude Code tie-in: it ships as an agent skill. <code>npx skills install jupyter-ai-contrib/nb-cli</code> and your agent can drive notebooks via <code>nb</code>.</li> <li>Out of jupyter-ai-contrib, which aims to become an official Jupyter AI subproject. Still early (<a href="http://crates.io?featured_on=pythonbytes">crates.io</a> is at v0.0.5), so kick the tires before anything load-bearing.</li> <li>See also <a href="https://marimo.io/blog/marimo-pair?featured_on=pythonbytes">marimo-pair</a>.</li> </ul> <p><strong>Calvin #4: <a href="https://hindsight.vectorize.io/?featured_on=pythonbytes">Hindsight</a> Agent Memory That Learns</strong></p> <ul> <li>AI agents forget everything between sessions — Hindsight gives them persistent memory that learns over time</li> <li>Simple three-method API: <code>retain()</code>, <code>recall()</code>, <code>reflect()</code> — store, retrieve, and reason over memories</li> <li>TEMPR retrieval runs semantic, keyword, graph, and temporal search in parallel for accurate results</li> <li>Automatically consolidates related facts into durable observations instead of piling up duplicates</li> <li><code>pip install hindsight-all</code> runs the entire server in-process; integrates with LangChain, LlamaIndex, Pydantic AI, CrewAI, and more</li> </ul> <p><strong>Extras</strong></p> <p>Calvin:</p> <ul> <li><a href="https://lucumr.pocoo.org/2026/5/26/clankers/?featured_on=pythonbytes"><strong>Clanker: A Word For The Machine</strong></a></li> <li><a href="https://github.com/DietrichGebert/ponytail?featured_on=pythonbytes">**Ponytail</a> — You know him. Long ponytail. Oval glasses. Has been at the company longer than the version control**</li> <li><a href="https://mcdonc.github.io/klangk/?featured_on=pythonbytes">**Klangk</a>: Multi-User AI Sandboxing, Collaboration and Coding Platform**</li> <li>Cursor announces <a href="https://cursor.com/origin?featured_on=pythonbytes">Origin</a></li> <li><a href="https://vorpus.github.io/performativeUI/#/">performative-ui</a> to quick start your new idea Michael:</li> <li><a href="https://talkpython.fm/episodes/show/552/astral-joins-openai?featured_on=pythonbytes">Astral Joins OpenAI: The Interview</a></li> <li><a href="https://arstechnica.com/ai/2026/06/spacex-will-acquire-coding-tool-cursor-to-compete-with-anthropic-openai/?featured_on=pythonbytes">SpaceX to acquire Cursor</a></li> <li>And <a href="https://www.linkedin.com/posts/marshcharles_im-proud-to-announce-that-were-renewing-share-7472388576807133184-XzKZ/?featured_on=pythonbytes">OpenAI renews Open Source support</a></li> <li>Portuguese subtitles are now available for <a href="https://training.talkpython.fm/courses/all?featured_on=pythonbytes">Talk Python courses</a></li> <li><a href="https://www.djangoproject.com/weblog/2026/jun/17/announcing-the-search-for-a-dsf-executive-director/?featured_on=pythonbytes">DSF is hiring</a> including Six Feet Up support</li> </ul> <p><strong>Joke: <a href="https://x.com/pr0grammerhum0r/status/2062202683742711910?s=12&featured_on=pythonbytes">Oh Babe…</a></strong></p>
Python Insider
Mitigated API authentication bypass for python.org download metadata
Vulnerability mitigated in python.org with follow-up third-party audit from Trail of Bits
Python 3.15.0 beta 3 is here!
The penultimate 3.15 beta is out!
Armin Ronacher
The Coming Loop
I don’t prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops.
— Boris Cherny
Over the last months I have watched more and more people build something on top of coding agents that feels meaningfully different from just using a coding agent. Some of this happens on top of Pi which is cool to see for sure! The pattern is the same everywhere though: work is put into a queue of sorts, a machine picks it up, attempts it, stops, and then some harness decides whether that was actually the end.
If not, the harness continues the same session, injects another message, starts a fresh session with modified context, or sends the task to another machine. The task stays alive beyond the point where the model by itself would normally have said: “I am done.”
I think about that type of loop more than I want to admit.
There is already an agent loop inside every coding agent. The model calls a tool, incorporates the result, calls another tool, reads a file, edits a file, runs tests, and eventually produces some answer. That loop is one we have been quite familiar with for a long time. The other loop is the harness level loop: the loop outside the agent loop. That loop is also not new. We have been doing versions of this since early Claude Code days, but that loop is becoming ever more present in agentic engineering and in recent weeks it has started to dominate the Twitter discourse.
I Am Not Good At This Yet
My current status is that I have not had much success with this way of working for code I deeply care about which turns out to be quite a lot of code.
Part of that is taste and part of it is control. I attempt to set a high bar for what I want code to look like, and I want to understand the code I ship. Under pressure, or in a discussion with another human, I want to be able to explain what the system does without first having to ask a clanker to explain it to me. Now there is obviously a question if this desire to understand the code is one that I will still have a few years from now. For now I have not moved past the point of comprehension being important to me.
Given this desire, there is something I lack with my experience of code written without me paying attention, particularly from loops. Present-day models tend to produce code that is too defensive, too complex, too local in its reasoning. They avoid strong invariants. They add fallbacks instead of making bad states impossible. They duplicate code, invent bad abstractions, and paper over unclear design with more machinery. Worse though: I so far see very little progress of this improving. If anything, on that front it feels to me that we might even be making steps in the wrong direction. At least for my taste, present-day hands-off harnesses like Claude Code with ultracode produce worse code than what we were producing last autumn. That’s because Claude Code, with Fable for instance will be working uninterrupted on a problem for thirty minutes or more, when previously the process would have been much more human in the loop.
Furthermore it’s well understood that models tend to observe some local failure and add a local defense. Karpathy mentioned how they are “mortally terrified of exceptions”. In systems with important invariants, especially persisted data formats or core infrastructure, the right fix is not “handle every malformed case.” The right fix is to make the malformed case unrepresentable or impossible to write in the first place. Yet even with a lot of manual steering, that type of code does not come out of LLMs naturally, and even if the code comes out naturally like that, they will still attempt to handle now impossible errors.
When you take that behavior and you put it behind loops, you tend to amplify it. If each iteration adds another small defense, the system slowly becomes less understandable while appearing more robust. The more hands-off you are, the more that happens. It also teaches really bad practices when tools like this are given to juniors without clear guidance. Because if you ask them, why they are doing all that, they will convincingly argue their case.
Where Loops Work
At the same time, it would be dishonest to pretend the loop pattern does not work because it already works astonishingly well in some domains.
Porting code one of them. There are already impressive examples of large automatic porting efforts, including the reported work around moving parts of Bun from Zig to Rust. I have used it with success myself to port MiniJinja to Go. Performance explorations are another case where this works beautifully. A machine can try experiments, benchmark them, discard failures, and keep searching. Security scanning fits naturally too and so does almost any type of research: asking a system to explore a complex problem space and report back without necessarily committing lasting code. One thing that many of these have in common is that they either do not generate new code, but transform code that already exists, or they produce code that intentionally does not have a long shelf life. They either produce proof of concepts or ideas, surface findings or are more akin to mechnical transformation.
I believe that loops that produce artifacts without necessity of longevity or that create some form of clearly verifiable mechnical translation matters more than the general ability of a harness to mechanically measure a goal. Many successful applications of loops use another LLM as a judge or as an orchestrator. The mechnical translation case can be verified with a binary test case, but it can also be judged by an LLM instead!
Claude Code, for instance, is increasingly good at creating entire experimental workflows that it will then execute. Sure, the code it produces is slop, but that’s more the fault of the model than the harness not being a good judge on if a step in the workflow resulted in a net improvement or completion.
The harness just needs some signal that lets it continue. It does not have to be objective or binary, it just has to be useful enough to drive another iteration.
I absolutely love loops already that take the boring parts out of my day to experiment and measure and to give me ideas.
Software As Organism
On the other hand using that same looping methodology to write lasting code does not yet sit well with me. The metaphor I like to reach for is one of moving from software as a deterministic machine to software as an organism.
I became a software engineer in an enviornment that encouraged me to understand the machine. There was always a layer you could peel off to deepen your understanding. Machines that did not exhibit deterministic observable behavior were maybe accepted, but generally seen as not exactly optimal. Software architecture-wise, I saw it as desireable to push further towards more determinism rather than less. Likewise the ability to understand the code has been an undeniable goal. In practice not always possible we still took pride in writing code so that it became possible even for new engineers to navigate complex code bases through clever architecture. On well designed systems there were always engineers that knew where the invariantes lived, which parts were load-bearing and which changes were safe. Ideally all of that was also well documented. Where that understanding was lacking, it was generally regarded as something to improve upon.
Obviously that ideal has always been strained. Many software systems, especially very successful ones had periods where engineers on the team were able to keep them clean. Large software systems are not infrequently too big, too dynamic and too dependent on external services to fit into anyone’s head. Even without LLMs we already diagnose distributed systems somewhat like doctors in that we observe symptoms, form hypotheses, “order more tests”, try some remedies, and observe again.
Yet with LLMs we’re pushing much further in that direction and much quicker. We use them to write the code and we also use them for diagnosis and remedy. There are plenty of engineers that already live in a world in which the first step after the occurrence of a production issue is followed by having a clanker read logs, propose root causes and proactively put up a patch. The resulting patch is then often picked up by another machine that reviews, sometimes even landing it on main without any human supervision.
Obviously that is powerful and I cannot deny that it sounds appealing. But giving in to that idea, particularly with less and less human oversight means accepting that we may no longer understand the whole system in the same way. We treat it, we monitor it, we stabilize it, but we do not necessarily comprehend it.
I have no doubts that for some software, that is okay. Not every line of code deserves human authorship and worse code might have been written in the past.
But do I want all software to be authored this way?
You Cannot Quite Opt Out
What’s very uncomfortable is that opting out of this fully machine-driven future may not be an option.
Security is the clearest example today. Even if you do not use loops to build your software, other people will use loops against your software. Attackers will run machines continuously and even if it’s not attackers, then security researchers will and some of that automated work will throw up dust but also find real issues. And both the signal and the noise will come your way at a volume that makes it almost impossible to deal with unless you yourself throw a machine at the problem.
Daniel Stenberg’s post about curl’s summer of bliss is a good example of the pressure maintainers are already under. As far as I know, AI does not play a tremendous role in the core development of curl today. Yet despite all of this, maintainers are overwhelmed by reports, most of which are now AI-generated ones.
If attackers and reporters loop, defenders will eventually need to loop too to keep up. Maybe not to write patches directly, maybe just to triage and reproduce and pressure will increase.
The same is true competitively as some teams will out-build others through raw speed. Some projects will suddenly move faster because a tiny group figures out how to orchestrate machines effectively. Some startups will do with five people what used to require fifty. Some people might literally put a machine against your product in a loop and ask it to “make it like the other one.” And if their users are happy, does it really matter?
Not all software will be equally affected. Some domains will punish sloppiness and demand trust and responsibility, but a lot of software lives in a world where raw speed, quick experimentation, and vast coverage matter enormously.
Building New Dependencies
The scariest part to me is that we become dependent on these new machines in new ways. Software has always depended on tools. I remember the time when I had to pay for compilers. These new tools are a flashback to times where creating software came with real costs. But now it’s no longer a one-time payment, it’s a constant dependency. Not just a dependency on a filled wallet, but also a cognitive dependency.
If a codebase is produced by loops, reviewed by loops, patched by loops, and kept alive by loops, what happens when you no longer have access to the same class of systems? What happens when some trade restrictions take away access to the most powerful models? What if just the cost becomes unbearable? What if you and your team just lose the last remaining ability to understand the code without using the machine?
We may create codebases that are not merely hard to maintain by humans, but that assume machine participation as part of their maintenance model. This is already happening! It’s not happening everywhere, and it might not even be happening in ways that are seen as problematic, but we see more and more of it. People more and more merge code they cannot fully explain. People lose their ability to create issue reports or discuss things in chat, without augmenting or rephrasing their messages with the context provided by a clanker. Too many people increasingly rely on a machine to summarize or contextualize it. More and more do I encounter people who converse with me through the indirection of an LLM.
Again, maybe that is not even going to be wrong, but it’s a massive change to how we did things.
Future Harnesses
I have little doubt that this is where things are going but going there will require us to do something about our tooling everywhere, and not just in the coding agents.
Just orchestrating more loops won’t be enough. Better visualizations of changes or orchestration or agents will not restore our understanding. Either we need to find clever ways to jolt the human back into the loop and make the changes of the loops legible long term, or we need to find better ways to compose these ever more complex systems.
This is also where my thinking about the role of Pi is changing. Pi has been cautious, and I think that caution is good. I do not want a future where every interaction turns into an uncontrolled swarm of machines making changes I cannot follow. I would not want Pi to become an unmaintainable mess in an effort to win the race towards software that writes itself and I would not want Pi to promote this type of engineering either. At the same time Pi is a harness and harnesses are at the center of people running these new types of experiments.
Task queues for coding tasks, orchestration of agents, subagents, durable sessions will matter more and more. Even those of us who have their reservations and are not blindly embracing loops will have to start doing those experiments. We need to, because we need to understand how to make this future bounded and survivable.
Controlling Loops
As you can read from this post, I’m very uneasy about this future. Not cause of fear, but because of caution given experiences with this technology so far.
Adopting the idea of harness loops means that the harness decides when work is finished. In the agent loop, the model eventually says “done” and I review. Even before that, I usually steer along the way. I am involved and I enjoy learning along the way. In the harness operated loop I’m not sure what my role even is. Even the “done” signal loses all meanings and just becomes communicated to yet another machine that judges. My role is reduced to that of a messenger.
Today I do not like much of the code that I see from systems built that way and neither do I enjoy interacting with too much of software built with AI assistence. Looping is powerful but it removes responsibility more and more, and it at least today very much encourages us to give in to the machine.
And yet I have no doubts that this looping future is going to be our future despite the fact that I presently resent it. I already see astonishingly small teams building at impossible speed and I see codebases turning more and more into obscure and confusing organisms that can only be diagnosed by more machines. Those codebases are simultaniously useful and messy.
So I guess I’m coming to terms with that the question is not whether we will loop because clearly we will. Maybe the question is that in a future of loops, how do we don’t abdicate judgment, how we can retain rules of good engineering, how we can ensure that responsible human can continue to supervise, how we need to re-think how we architect code to retain sanity along the way.
June 22, 2026
Rodrigo Girão Serrão
Write a coding agent from first principles

Learn how to write a coding agent in this Python tutorial that teaches how to interact with an LLM through an API, how to manage the conversation context, and how to do tool calling.
Introduction
This tutorial will show you how to create your own coding agent from first principles. By doing so, you'll understand how coding agents work under the hood.
Prerequisites
To be able to follow this tutorial, you'll need
- prior Python experience: this tutorial is not suitable for people who don't have programming experience
- a valid Claude API key: you can get a Claude API key in the Claude Console dashboard[^1]
- uv: to manage the project you'll be working on
The concepts explained in this tutorial are independent from your LLM provider but the code snippets will make use of the Claude API and its Python SDK. This means that you can follow along with a different model provider as long as you adapt the code snippets to match the format expected by the API of your provider.
What's a coding agent?
A coding agent is an agent that's specialised for coding. In turn, an agent is just an LLM that has been extended with extra functionality that allows it to interact with its environment. This extra functionality is provided through tools, one of the core ideas covered in this tutorial.
This short definition still hides a lot of details, but instead of giving you a theoretical definition you can learn what a coding agent is by creating one. That starts now.
Project set up
To set your project up, start by using uv to create a packageable app project[^2]:
% uv init --app --package agent
Initialized project `agent` at `/Users/rodrigogs/Documents/mathspp/agent`Then, cd into the project and add the two dependencies you'll need:
% cd agent
% uv add python-dotenv anthropicYou'll use python-dotenv to help you with authentication to access the Claude API and you'll use the dependency anthropic to make it easier to interact with the Claude API.
To set up authentication, create a .env file and paste your Claude API key there in front of the variable ANTHROPIC_API_KEY.
When you're done, your .env file should look like this:
ANTHROPIC_API_KEY="sk-ant-api03-qI_3mJ..."To make sure you never upload your API key to GitHub by accident, add the file .env to your .gitignore:
# .gitignore
# ... other entries generated by uv
.envNow that you've set up your project, you can make your first request to the Claude API.
Interacting with an LLM
A coding agent needs an LLM at its core.
Your LLM can come from any provider you want but you're going to use Claude because its SDK (the dependency anthropic you added in the previous section) is easy to use and because Claude is a popular model provider.
Using the anthropic SDK, here's how you can send a message to the LLM:
# src/agent/__init__.py
from anthropic import Anthropic
import dotenv
dotenv.load_dotenv() # Load .env
MODEL = "claude-haiku-4-5"...